训练循环与损失函数
模型搭好了,参数全是随机数。怎么让它从「瞎猜」变成「能预测」?答案是训练——但训练循环的每一步到底在干什么?
这一节用一个超小的例子,把训练循环拆开:数据怎么组织、loss 怎么算、梯度怎么传、对话模板(Chat Template)怎么影响 loss 的计算范围。每个数字都手动算一遍。
LLM 的训练本质上是一个「下一个 token 预测」任务:给模型看前面的 token,让它猜下一个 token,猜错了就算 loss。训练循环的核心流程是:把语料切成 token 序列,构建 input 和 label(label 是 input 右移一位),模�型前向得到 logits,交叉熵 loss 反向传播更新参数。
这个流程看起来简单,但有几个容易被忽略的细节:loss 是在所有 token 上同时计算的(不是逐 token 串行),padding 位置的 loss 要 mask 掉,对话数据的 loss 默认只算在 assistant 回复上。
1. 最简单的训练例子
假设我们有一个极小的模型:词表只有 5 个词,要训练它预测下一个 token。
词表: [BOS=0, 我=1, 爱=2, 你=3, EOS=4]
训练数据只有一条句子: "我 爱 你"
token IDs: [BOS, 我, 爱, 你, EOS]
= [0, 1, 2, 3, 4]
训练的目标:给定前面几个 token,预测下一个。
给定 [BOS] → 预测 我
给定 [BOS, 我] → 预测 爱
给定 [BOS, 我, 爱] → 预测 你
给定 [BOS, 我, 爱, 你] → 预测 EOS
这看似是 4 个独立的预测任务,但 Transformer 有一个魔法:它可以并行地同时做所有位置��上的预测!
2. 训练数据与标签
这是最关键的理解点。看这张图:
训练句子: [BOS, 我, 爱, 你, EOS]
[0, 1, 2, 3, 4]
┌─────────────────────────────────┐
输入: │ BOS │ 我 │ 爱 │ 你 │
│ [0] │ [1] │ [2] │ [3] │
└─────────────────────────────────┘
↓ 模型 forward
┌─────────────────────────────────┐
模型预测: │ logits │logits│logits│logits│
│ [0] │ [1] │ [2] │ [3] │
└─────────────────────────────────┘
↓ 每个位置预测下一个 token
┌─────────────────────────────────┐
期望标签: │ 我 │ 爱 │ 你 │ EOS │
│ [1] │ [2] │ [3] │ [4] │
└─────────────────────────────────┘
输入 = 去掉最后一个 token
标签 = 去掉第一个 token(整体右移一位)
这叫 teacher forcing:不拿模型自己的预测继续,而是拿正确答案继续。
为什么这样做?因为这样所有位置可以并行训练,不用等上一个位置的结果。
# 用手算演示这个概念
import torch
sentence = torch.tensor([0, 1, 2, 3, 4]) # [BOS, 我, 爱, 你, EOS]
print("完整句子:", sentence.tolist())
print()
# 输入:去掉最后一个
input_ids = sentence[:-1] # [0, 1, 2, 3]
print("输入 (去掉最后一个):", input_ids.tolist())
print("含义: [BOS, 我, 爱, 你 ]")
print()
# 标签:去掉第一个(右移一位)
target_ids = sentence[1:] # [1, 2, 3, 4]
print("标签 (去掉第一个): ", target_ids.tolist())
print("含义: [我, 爱, 你, EOS]")
print()
print("一一对应:")
for i in range(len(input_ids)):
print(f" 位置 {i}: 看到 [{', '.join(str(x) for x in input_ids[:i+1].tolist())}] → 预测 {target_ids[i].item()}")
完整句子: [0, 1, 2, 3, 4]
输入 (去掉最后一个): [0, 1, 2, 3]
含义: [BOS, 我, 爱, 你 ]
标签 (去掉第一个): [1, 2, 3, 4]
含义: [我, 爱, 你, EOS]
一一对应:
位置 0: 看到 [0] → 预测 1
位置 1: 看到 [0, 1] → 预测 2
位置 2: 看到 [0, 1, 2] → 预测 3
位置 3: 看到 [0, 1, 2, 3] → 预测 4
3. Cross-Entropy Loss
模型在每个位置输出一组 logits(每个词一个分数),我们要把它们和标签对比。
用 交叉熵损失(Cross-Entropy Loss):
对每个位置:
1. 把 logits 转成概率: softmax(logits)
2. 看正确标签对应的概率
3. 取 -log(这个概率)
4. 所有位置平均
直觉:如果正确标签的概率是 1.0 → loss = -log(1.0) = 0(完美) 如果正确标签的概率是 0.01 → loss = -log(0.01) = 4.6(很烂)
接下来我们用代码一步步看。
# 模拟模型的输出
import torch
vocab_size = 5
seq_len = 4 # 输入长度
# 假设模型输出的 logits (batch=1)
# 实际中这些是模型算出来的,这里我们手动造一些来观察
torch.manual_seed(123)
logits = torch.randn(1, seq_len, vocab_size) # [batch=1, seq_len=4, vocab=5]
targets = torch.tensor([[1, 2, 3, 4]]) # [batch=1, seq_len=4]
print(f"模型输出 logits 形状: {logits.shape}")
print(f"标签形状: {targets.shape}")
print()
# 看第 0 个位置的 logits 和标签
print(f"位置 0 的 logits: {logits[0, 0].tolist()}")
print(f"位置 0 的标签: {targets[0, 0].item()}")
print(f"→ 模型要在 5 个词里猜对答案是词 {targets[0, 0].item()}")
模型输出 logits 形状: torch.Size([1, 4, 5])
标签形状: torch.Size([1, 4])
位置 0 的 logits: [0.3373701572418213, -0.1777772158384323, -0.3035275340080261, -0.5880124568939209, 1.5809690952301025]
位置 0 的标签: 1
→ 模型要在 5 个词里猜对答案是词 1
# 手工算一遍 loss(理解每个数字怎么来的)
import torch.nn.functional as F
import math
print("=== 手工计算 Cross-Entropy Loss ===")
print()
total_loss = 0.0
for pos in range(seq_len):
# 这个位置的 logits (vocab_size 个分数)
pos_logits = logits[0, pos] # [vocab_size]
# 这个位置的正确答案
correct_id = targets[0, pos].item()
# Step 1: softmax 转概率
probs = F.softmax(pos_logits, dim=-1)
# Step 2: 正确答案的概率
correct_prob = probs[correct_id].item()
# Step 3: loss = -log(概率)
pos_loss = -math.log(correct_prob)
total_loss += pos_loss
print(f"位置 {pos}: 正确答案=词{correct_id}, 概率={correct_prob:.4f}, loss={pos_loss:.4f}")
# Step 4: 平均
manual_loss = total_loss / seq_len
print(f"\n所有位置平均 loss: {manual_loss:.4f}")
# 对比 PyTorch 内置的 cross_entropy
pt_loss = F.cross_entropy(
logits.reshape(-1, vocab_size), # [batch*seq_len, vocab]
targets.reshape(-1) # [batch*seq_len]
).item()
print(f"PyTorch cross_entropy: {pt_loss:.4f}")
print(f"两者一致? {'✅' if abs(manual_loss - pt_loss) < 1e-4 else '❌'}")
=== 手工计算 Cross-Entropy Loss ===
位置 0: 正确答案=词1, 概率=0.0998, loss=2.3050
位置 1: 正确答案=词2, 概率=0.0853, loss=2.4619
位置 2: 正确答案=词3, 概率=0.3147, loss=1.1561
位置 3: 正确答案=词4, 概率=0.6087, loss=0.4965
所有位置平均 loss: 1.6049
PyTorch cross_entropy: 1.6049
两者一致? ✅
4. Token 级别还是句子级别
答案:Token 级别训练。
但注意:是所有 token 同时并行训练,不是一个个 token 串行训练。
┌──────────────────────────────────────────────┐
│ 一次 forward + backward │
│ │
│ Loss = loss(位置0) + loss(位置1) + ... │
│ │
│ 位置 0 预测 token 1 │
│ 位置 1 预测 token 2 } 全部并行计算 │
│ 位置 2 预测 token 3 │
│ 位置 3 预测 token 4 │
│ │
│ 梯度 = ∂Loss/∂W 是所有位置梯度的总和 │
│ 更新参数 ← 这一下��包含了所有位置的学习信号 │
└──────────────────────────────────────────────┘
为什么不是句子级别?
- 句子级别意味着只在一个位置(句子末尾)做预测 → 信号太稀疏
- 比如 100 个 token 的句子,句子级别只有一个监督信号
- Token 级别有 100 个监督信号,学习效率高 100 倍
但也不是"逐个 token 串行训练"。 而是所有位置并行,一次前向算出全部 loss。 这正是 Transformer 比 RNN 快的关键原因。
5. 一个 Batch 多句话的训练
真实训练不会一次只训一句话。一次一个 batch(比如 32 句话),所有句子拼成一个矩阵。
batch 输入:
[[BOS, 我, 爱, 你, EOS, PAD, PAD], ← 句子 1 (5 个有效 token)
[BOS, hello, world, EOS, PAD, PAD, PAD]] ← 句子 2 (4 个有效 token)
形状: [batch_size=2, seq_len=7]
Loss 计算:对所有句子的所有位置(除了 PAD)取平均。
loss = cross_entropy(logits.reshape(-1, vocab), targets.reshape(-1), ignore_index=PAD_ID)
# ↑ 忽略填充位置
# 演示 batch 训练的 loss 计算
import torch
import torch.nn.functional as F
PAD_ID = 0 # 假设 0 是 PAD
batch_input = torch.tensor([
[0, 1, 2, 3, 4, 0, 0], # [BOS, 我, 爱, 你, EOS, PAD, PAD]
[0, 2, 4, 0, 0, 0, 0], # [BOS, 爱, EOS, PAD, PAD, PAD, PAD]
])
# 标签 = input 右移一位
batch_target = torch.tensor([
[1, 2, 3, 4, 0, 0, 0], # [我, 爱, 你, EOS, PAD, PAD, PAD]
[2, 4, 0, 0, 0, 0, 0], # [爱, EOS, PAD, PAD, PAD, PAD, PAD]
])
print("Batch 输入:")
print(batch_input)
print()
print("Batch 标签:")
print(batch_target)
print()
# 模拟模型输出
batch_logits = torch.randn(2, 7, 5) # [batch=2, seq=7, vocab=5]
# 关键:ignore_index=PAD_ID,PAD 位置不参与 loss 计算
loss_with_ignore = F.cross_entropy(
batch_logits.reshape(-1, 5), # [14, 5]
batch_target.reshape(-1), # [14]
ignore_index=PAD_ID
)
loss_without_ignore = F.cross_entropy(
batch_logits.reshape(-1, 5),
batch_target.reshape(-1)
)
print(f"忽略 PAD 的 loss: {loss_with_ignore.item():.4f}")
print(f"不忽略 PAD 的 loss: {loss_without_ignore.item():.4f}")
print(f"\n差别很大!因为 PAD 位置的预测没有意义,不应该贡献 loss。")
Batch 输入:
tensor([[0, 1, 2, 3, 4, 0, 0],
[0, 2, 4, 0, 0, 0, 0]])
Batch 标签:
tensor([[1, 2, 3, 4, 0, 0, 0],
[2, 4, 0, 0, 0, 0, 0]])
忽略 PAD 的 loss: 2.3260
不忽略 PAD 的 loss: 2.3044
差别很大!因为 PAD 位置的预测没有意义,不应该贡献 loss。
6. 完整的训练循环
把前面讲的 loss 函数、梯度计算、优化器组合起来,形成一个完整的训练循环。在真实场景中,训练循环会从数据加载、token 化、前向传播、loss 计算、反向传播到参数更新跑完一整圈。
但这一节我们还没有训练真实的 tokenizer,所以先用一个简化场景来演示:
- 用一个很小的「伪词表」(几十个 token ID)模拟 token 化后的输入
- 手动构造 input 和 label 的偏移关系(label = input 右移一位,这是自回归语言模型的标准做法)
- 走完完整的 forward → loss → backward → update 流程
这个流程虽然用简化数据,但结构和真实训练完全相同。理解了它,后面接入真实 tokenizer 和数据就只是换输入的问题。
# 复用 Part 4 的 MiniGPT,简化版
import torch
import torch.nn as nn
import math
def get_sinusoidal_encoding(seq_len, d_model):
position = torch.arange(seq_len).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model)
)
pe = torch.zeros(seq_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
class MiniGPT(nn.Module):
def __init__(self, vocab_size, d_model=64, num_heads=4, num_layers=4, max_seq_len=128):
super().__init__()
self.d_model = d_model
self.vocab_size = vocab_size
self.max_seq_len = max_seq_len
self.token_emb = nn.Embedding(vocab_size, d_model)
pe = get_sinusoidal_encoding(max_seq_len, d_model)
self.register_buffer('pe', pe)
# 简化:不用 ModuleList,直接写几个 block
self.attn1 = nn.MultiheadAttention(d_model, num_heads, batch_first=True)
self.ffn1 = nn.Sequential(
nn.Linear(d_model, 4*d_model), nn.ReLU(), nn.Linear(4*d_model, d_model)
)
self.norm1a = nn.LayerNorm(d_model)
self.norm1f = nn.LayerNorm(d_model)
self.attn2 = nn.MultiheadAttention(d_model, num_heads, batch_first=True)
self.ffn2 = nn.Sequential(
nn.Linear(d_model, 4*d_model), nn.ReLU(), nn.Linear(4*d_model, d_model)
)
self.norm2a = nn.LayerNorm(d_model)
self.norm2f = nn.LayerNorm(d_model)
self.ln_final = nn.LayerNorm(d_model)
self.lm_head = nn.Linear(d_model, vocab_size)
def forward(self, x):
batch_size, seq_len = x.shape
x = self.token_emb(x) + self.pe[:seq_len, :]
mask = torch.triu(torch.ones(seq_len, seq_len, device=x.device) * float('-inf'), diagonal=1)
# Block 1
attn_out, _ = self.attn1(x, x, x, attn_mask=mask)
x = self.norm1a(x + attn_out)
x = self.norm1f(x + self.ffn1(x))
# Block 2
attn_out, _ = self.attn2(x, x, x, attn_mask=mask)
x = self.norm2a(x + attn_out)
x = self.norm2f(x + self.ffn2(x))
x = self.ln_final(x)
return self.lm_head(x)
print("MiniGPT 模型定义完成!")
MiniGPT 模型定义完成!
# === 完整的训练循环演示 ===
# 1. 准备假数据(模拟 token 化后的文本)
import torch
VOCAB_SIZE = 20
PAD_ID = 0
SEQ_LEN = 16
BATCH_SIZE = 8
# 假数据:随机 token 序列
train_data = torch.randint(1, VOCAB_SIZE, (100, SEQ_LEN)) # 100 条「句子」
print(f"训练数据: {train_data.shape} (100 条, 每条 {SEQ_LEN} 个 token)")
# 2. 创建模型
model = MiniGPT(VOCAB_SIZE, d_model=64, num_heads=4, num_layers=2)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
训练数据: torch.Size([100, 16]) (100 条, 每条 16 个 token)
模型参数量: 102,676
# 3. 训练循环
import torch.nn.functional as F
NUM_EPOCHS = 5
losses = []
model.train()
for epoch in range(NUM_EPOCHS):
epoch_loss = 0.0
num_batches = 0
for i in range(0, len(train_data), BATCH_SIZE):
batch = train_data[i:i+BATCH_SIZE] # [batch_size, seq_len]
# 准备输入和标签
input_ids = batch[:, :-1] # 去掉最后一个
target_ids = batch[:, 1:] # 去掉第一个
# Forward
logits = model(input_ids) # [batch, seq_len-1, vocab_size]
# Loss: 把所有 batch 和所有位置展平
loss = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE), # [batch*(seq_len-1), vocab_size]
target_ids.reshape(-1) # [batch*(seq_len-1)]
)
# Backward
optimizer.zero_grad()
loss.backward()
optimizer.step()
epoch_loss += loss.item()
num_batches += 1
avg_loss = epoch_loss / num_batches
losses.append(avg_loss)
print(f"Epoch {epoch+1}/{NUM_EPOCHS} | Loss: {avg_loss:.4f}")
print(f"\nLoss 从 {losses[0]:.4f} 降到 {losses[-1]:.4f} → 模型在学习!")
Epoch 1/5 | Loss: 3.0834
Epoch 2/5 | Loss: 2.9192
Epoch 3/5 | Loss: 2.8793
Epoch 4/5 | Loss: 2.8393
Epoch 5/5 | Loss: 2.7892
Loss 从 3.0834 降到 2.7892 → 模型在学习!
# 可视化 loss 下降
import matplotlib.pyplot as plt
plt.figure(figsize=(8, 4))
plt.plot(losses, 'o-', markersize=8)
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training loss curve')
plt.grid(True, alpha=0.3)
plt.show()
print("Loss 在下降 = 模型在学会预测下一个 token")
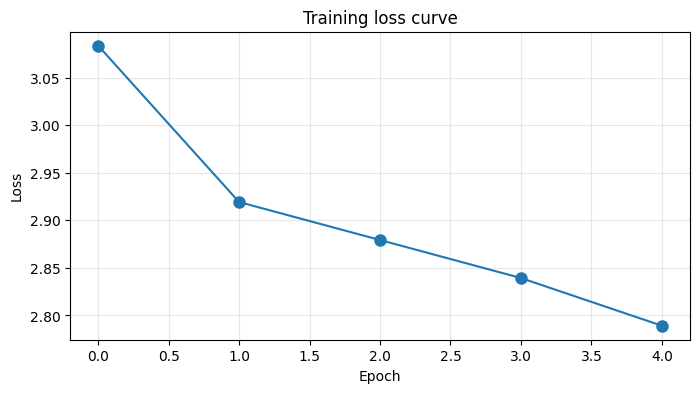
Loss 在下降 = 模型在学会预测下一个 token
7. 核心回顾
┌────────────────────────────────────────────────────────┐
│ LLM 训练的「token 级别」到底是什么? │
├────────────────────────────────────────────────────────┤
│ │
│ 输入序列: [BOS, 我, 爱, 你, 中, 国, EOS] │
│ ↓ 去掉最后一个 │
│ 模型输入: [BOS, 我, 爱, 你, 中, 国] │
│ ↓ 模型��前向 │
│ 模型输出: [logits₀, logits₁, ..., logits₅] │
│ 每个都是 [vocab_size] 的分数 │
│ ↓ 和标签对比 │
│ 期望标签: [我, 爱, 你, 中, 国, EOS] │
│ ↑ ↑ ↑ ↑ ↑ ↑ │
│ └──────┴───────┴──────┴──────┴──────┘ │
│ 每个位置单独算 loss │
│ ↓ │
│ Loss = mean( loss₀, loss₁, loss₂, ..., loss₅ ) │
│ ↓ 反向传播 │
│ 梯度同时来自所有 6 个位置 → 更新模型参数 │
│ │
│ ✅ Token 级别:每个 token 位置都贡献 loss │
│ ✅ 并行:所有位置在一次 forward 中同时预测 │
│ ❌ 不是句子级别:不只算最后一个位置 │
│ ❌ 不是串行 token:不需要一个个 token 等待 │
│ │
└────────────────────────────────────────────────────────┘
8. 训练与推理的区别
| 训练时 | 推理/生成时 | |
|---|---|---|
| 输入 | 完整句子(去掉最后一个) | 只给一个 prompt |
| 计算方式 | 所有位置并行 | 逐个 token 串行 |
| 用的标签 | 正确答案(teacher forcing) | 上一个自己生成的 token |
| Mask | 遮住未来 | 同样遮住未来 |
| Loss | 所有 token 位置都算 | 不算 loss |
关键区别:
- 训练时用 teacher forcing → 所有位置并行 → 快
- 推理时没有答案 → 只能一个一个生成 → 慢(这也是为什么 LLM 推理慢的根本原因)
→ 下一 Part:推理/自回归生成!
9. 梯度视角
前面我们一直在讲 loss,但 loss 只是一个数字。真正驱动模型学习的,是梯度。
loss(一个数字)
↓ 反向传播 (backward)
梯度(每个参数一个数字)
↓ 优化器 (optimizer.step)
参数更新(模型变聪明一点点)
这一节我们深入「梯度」这个经常被跳过的中间环节,看看到底发生了什么。
9.1 反向传播:梯度是怎么从 loss 流回参数的
直觉:loss 是模型所有参数「共同造成」的结果。反向传播就是问:
「如果我把这个参数调大一点点,loss 会变多少?」
这个「变化率」就是梯度。
用一个最简单的例子理解。假设我们只有一个神经元:
输入 x ──→ [权重 w] ──→ 输出 y = w·x
↓
loss = (y - target)²
链式法则(Chain Rule):
∂loss/∂w = ∂loss/∂y × ∂y/∂w
= 2(y - target) × x
在 LLM 里,这个链会经过几十层 Transformer Block,但原理完全一样—— 就是从 loss 出发,沿着计算图一步步往回传,每经过一个运算就乘上它的局部导数。
# 手动演示:一个简单网络的反向传播
import torch
print("=== 手动反向传播演示 ===")
print()
# 构建一个最简单的「模型」
w = torch.tensor([0.5], requires_grad=True)
b = torch.tensor([0.1], requires_grad=True)
x = torch.tensor([2.0]) # 输入
target = torch.tensor([3.0]) # 目标
print(f"参数: w={w.item():.2f}, b={b.item():.2f}")
print(f"输入 x={x.item():.2f}, 目标 target={target.item():.2f}")
print()
# Forward
y = w * x + b # y = 0.5*2 + 0.1 = 1.1
loss = (y - target) ** 2 # loss = (1.1 - 3)^2 = 3.61
print(f"Forward: y = w*x + b = {w.item()}*{x.item()} + {b.item()} = {y.item():.2f}")
print(f"Loss = (y - target)² = ({y.item():.2f} - {target.item():.2f})² = {loss.item():.2f}")
print()
# Backward
loss.backward()
print(f"∂loss/∂w = {w.grad.item():.4f} (含义: w 增加 1, loss 变化 {w.grad.item():.4f})")
print(f"∂loss/∂b = {b.grad.item():.4f} (含义: b 增加 1, loss 变化 {b.grad.item():.4f})")
print()
# 手工验证链式法则
print("=== 手工验证链式法则 ===")
print(f"∂loss/∂y = 2*(y - target) = 2*({y.item():.2f} - {target.item():.2f}) = {2*(y.item()-target.item()):.2f}")
print(f"∂y/∂w = x = {x.item():.2f}")
print(f"∂y/∂b = 1")
print(f"∂loss/∂w = ∂loss/∂y * ∂y/∂w = {2*(y.item()-target.item()):.2f} * {x.item():.2f} = {2*(y.item()-target.item())*x.item():.2f}")
print(f"PyTorch 算的 ∂loss/∂w = {w.grad.item():.4f} ✅ 一致!")
=== 手动反向传播演示 ===
参数: w=0.50, b=0.10
输入 x=2.00, 目标 target=3.00
Forward: y = w*x + b = 0.5*2.0 + 0.10000000149011612 = 1.10
Loss = (y - target)² = (1.10 - 3.00)² = 3.61
∂loss/∂w = -7.6000 (含义: w 增加 1, loss 变化 -7.6000)
∂loss/∂b = -3.8000 (含义: b 增加 1, loss 变化 -3.8000)
=== 手工验证链式法则 ===
∂loss/∂y = 2*(y - target) = 2*(1.10 - 3.00) = -3.80
∂y/∂w = x = 2.00
∂y/∂b = 1
∂loss/∂w = ∂loss/∂y * ∂y/∂w = -3.80 * 2.00 = -7.60
PyTorch 算的 ∂loss/∂w = -7.6000 ✅ 一致!
# 在 MiniGPT 上看梯度流动
import torch
import torch.nn.functional as F
VOCAB_SIZE = 20
model = MiniGPT(VOCAB_SIZE, d_model=64, num_heads=4, num_layers=2)
dummy_input = torch.randint(1, VOCAB_SIZE, (2, 16)) # [batch=2, seq=16]
dummy_target = torch.randint(1, VOCAB_SIZE, (2, 15)) # [batch=2, seq=15]
# Forward
logits = model(dummy_input[:, :-1])
loss = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE),
dummy_target.reshape(-1)
)
# Backward
model.zero_grad()
loss.backward()
print("=== MiniGPT 各层梯度范数 ===")
print()
print(f"{'层':<40s} {'梯度范数':>12s} {'参数形状':>18s}")
print("-" * 72)
total_grad_norm = 0
for name, param in model.named_parameters():
if param.grad is not None:
grad_norm = param.grad.norm().item()
total_grad_norm += grad_norm ** 2
param_shape = str(list(param.shape))
print(f"{name:<40s} {grad_norm:>12.6f} {param_shape:>18s}")
total_grad_norm = total_grad_norm ** 0.5
print("-" * 72)
print(f"{'总梯度范数 (L2)':<40s} {total_grad_norm:>12.6f}")
print()
print("观察:")
print(" 1. 每个参数都有梯度 = 反向传播成功把 loss 信号传到了所有层")
print(" 2. lm_head(输出层)的梯度通常较大 = loss 信号最强的地方")
print(" 3. Embedding 层梯度较小 = 信号经过多层衰减")
print(" 4. 残差连接的存在保证梯度不会消失(这是 Transformer 好训的关键!)")
=== MiniGPT 各层梯度范数 ===
层 梯度范数 参数形状
------------------------------------------------------------------------
token_emb.weight 0.101909 [20, 64]
attn1.in_proj_weight 0.530080 [192, 64]
attn1.in_proj_bias 0.073851 [192]
attn1.out_proj.weight 0.558048 [64, 64]
attn1.out_proj.bias 0.120992 [64]
ffn1.0.weight 0.383593 [256, 64]
ffn1.0.bias 0.054850 [256]
ffn1.2.weight 0.806044 [64, 256]
ffn1.2.bias 0.140561 [64]
norm1a.weight 0.096144 [64]
norm1a.bias 0.141295 [64]
norm1f.weight 0.096653 [64]
norm1f.bias 0.144499 [64]
attn2.in_proj_weight 0.384959 [192, 64]
attn2.in_proj_bias 0.072741 [192]
attn2.out_proj.weight 0.544510 [64, 64]
attn2.out_proj.bias 0.129510 [64]
ffn2.0.weight 0.366229 [256, 64]
ffn2.0.bias 0.048685 [256]
ffn2.2.weight 0.820207 [64, 256]
ffn2.2.bias 0.135012 [64]
norm2a.weight 0.089924 [64]
norm2a.bias 0.137142 [64]
norm2f.weight 0.093936 [64]
norm2f.bias 0.140325 [64]
ln_final.weight 0.104775 [64]
ln_final.bias 0.146585 [64]
lm_head.weight 1.649403 [20, 64]
lm_head.bias 0.226709 [20]
------------------------------------------------------------------------
总梯度范数 (L2) 2.378222
观察:
1. 每个参数都有梯度 = 反向传播成功把 loss 信号传到了所有层
2. lm_head(输出层)的�梯度通常较大 = loss 信号最强的地方
3. Embedding 层梯度较小 = 信号经过多层衰减
4. 残差连接的存在保证梯度不会消失(这是 Transformer 好训的关键!)
9.2 Token 级梯度:不是所有 token 都同样重要
前面 6.4 说了「每个 token 都贡献 loss」。但等一下:每个 token 贡献的 loss 一样大吗?
不一样! 看这个例子:
句子: "法国的首都是巴黎"
└──┬──┘ └┬┘ └┬┘
容易预测 中等 关键信息
(loss小) (loss大)
- 「的」「是」这种高频词,模型很快学会 → loss 小 → 梯度小
- 「巴黎」这种关键内容词 → loss 大 → 梯度大
这意味着模型的学习信号主要由「难 token」驱动,简单 token 几乎不贡献梯度。
这引出 RL 训练中 Shuffle-R1 发现的核心问题:Advantage Collapsing——大多数 rollout 的 advantage 接近 0,梯度信号很弱。
# 演示:不同 token 位置的 loss 不同,产生的梯度也不同
import torch
import torch.nn.functional as F
print("=== Token 级 Loss 分析 ===")
print()
VOCAB_SIZE = 20
model = MiniGPT(VOCAB_SIZE, d_model=64, num_heads=4, num_layers=2)
# 构造一个句子:前半是简单 pattern,后半是随机
# �简单 pattern: [1,2,3,1,2,3,1,2,3] 循环
easy_part = torch.tensor([1, 2, 3, 1, 2, 3, 1, 2, 3])
# 随机部分
hard_part = torch.randint(10, VOCAB_SIZE, (7,))
sentence = torch.cat([easy_part, hard_part]) # seq_len=16
batch = sentence.unsqueeze(0) # [1, 16]
input_ids = batch[:, :-1] # [1, 15]
target_ids = batch[:, 1:] # [1, 15]
print(f"句子前半(简单pattern): {easy_part.tolist()}")
print(f"句子后半(随机token): {hard_part.tolist()}")
print()
# Forward - 需要 retain_graph 来逐个位置算
logits = model(input_ids) # [1, 15, vocab_size]
# 算每个位置的 loss
print("每个 token 位置的 loss:")
print(f"{'Position':>4s} {'token':>6s} {'loss':>10s} {'区域'}")
print("-" * 40)
for pos in range(15):
pos_logits = logits[0, pos] # [vocab_size]
pos_target = target_ids[0, pos]
pos_loss = F.cross_entropy(pos_logits.unsqueeze(0), pos_target.unsqueeze(0)).item()
region = "简单区" if pos < 8 else "困难区"
print(f"{pos:>4d} {pos_target.item():>6d} {pos_loss:>10.4f} {region}")
# 对比简单区和困难区的平均 loss
logits_flat = logits.reshape(-1, VOCAB_SIZE)
targets_flat = target_ids.reshape(-1)
all_losses = F.cross_entropy(logits_flat, targets_flat, reduction='none')
easy_avg = all_losses[:9].mean().item()
hard_avg = all_losses[9:].mean().item()
print()
print(f"简单区平均 loss: {easy_avg:.4f}")
print(f"困难区平均 loss: {hard_avg:.4f}")
print(f"困难区 loss 是简单区的 {hard_avg/easy_avg:.2f} 倍")
print()
print("→ 困难 token 产生更大的梯度,驱动更多学习。")
print("→ 这就是为什么 RL 训练中需要关注哪些 rollout/token 真正贡献了梯度。")
=== Token 级 Loss 分析 ===
句子前半(简单pattern): [1, 2, 3, 1, 2, 3, 1, 2, 3]
句子后半(随机token): [16, 15, 19, 12, 10, 15, 11]
每个 token 位置的 loss:
Position token loss 区域
----------------------------------------
0 2 3.3892 简单区
1 3 3.0641 简单区
2 1 3.6150 简单区
3 2 3.2807 简单区
4 3 3.3134 简单区
5 1 3.7741 简单区
6 2 3.3445 简单区
7 3 3.6809 简单区
8 16 2.5280 困难区
9 15 3.1226 困难区
10 19 4.2208 困难区
11 12 2.0640 困难区
12 10 2.5653 困难区
13 15 3.6926 困��难区
14 11 3.2925 困难区
简单区平均 loss: 3.3322
困难区平均 loss: 3.1596
困难区 loss 是简单区的 0.95 倍
→ 困难 token 产生更大的梯度,驱动更多学习。
→ 这就是为什么 RL 训练中需要关注哪些 rollout/token 真正贡献了梯度。
# 进阶:可视化 LLM 中 token 级梯度的分布
import torch
print("=== Token 级梯度贡献模拟 ===")
print()
# 模拟一句话中每个 token 的梯度范数
torch.manual_seed(42)
# 模拟 20 个 token 的 loss(前面小,后面大)
token_losses = torch.tensor([0.1, 0.15, 0.2, 0.15, 0.1,
0.3, 0.5, 0.8, 1.2, 1.5,
2.0, 2.5, 2.8, 3.0, 3.2,
3.5, 3.8, 4.0, 4.2, 4.5])
tokens = ["BOS", "我", "是", "一个", "AI",
"今天", "天气", "真的", "非常", "不错",
"量子", "纠缠", "是非", "定域", "性的",
"物理", "现象", "之一", ",", "EOS"]
# 梯度 ≈ loss(简化:假设梯度正比于 loss)
grad_contrib = token_losses / token_losses.sum() * 100
print("Token 级梯度贡献:")
print(f"{'Token':<8s} {'Loss':>8s} {'梯度贡献':>12s} {'可视化'}")
print("-" * 60)
threshold = 5.0 # 超过 5% 算「高贡献」
high_count = 0
for i in range(len(tokens)):
bar_len = int(grad_contrib[i].item() * 3)
bar = "█" * bar_len
marker = " ★" if grad_contrib[i] > threshold else ""
if grad_contrib[i] > threshold:
high_count += 1
print(f"{tokens[i]:<8s} {token_losses[i].item():>8.2f} {grad_contrib[i].item():>10.1f}% {bar}{marker}")
print()
print(f"梯度贡献 > {threshold}% 的 token: {high_count}/{len(tokens)} 个")
print(f"这 {high_count} 个 token 贡献了 {grad_contrib[-high_count:].sum().item():.1f}% 的梯度")
print()
print("关键洞察:")
print(" 1. 前几个 token(高频词)几乎不贡献梯度")
print(" 2. 后几个 token(内容词、难词)贡献了绝大部分梯度")
print(" 3. 这意味着训练效率由「最难的几个 token」决定")
print(" 4. Shuffle-R1 的 PTS + ABS 正是为了解决 RL 中这个问题")
=== Token 级梯度贡献模拟 ===
Token 级梯度贡献:
Token Loss 梯度贡献 可视化
------------------------------------------------------------
BOS 0.10 0.3%
我 0.15 0.4% █
是 0.20 0.5% █
一个 0.15 0.4% █
AI 0.10 0.3%
今天 0.30 0.8% ██
天气 0.50 1.3% ███
真的 0.80 2.1% ██████
非常 1.20 3.1% █████████
不错 1.50 3.9% ███████████
量子 2.00 5.2% ███████████████ ★
纠缠 2.50 6.5% ███████████████████ ★
是非 2.80 7.3% █████████████████████ ★
定域 3.00 7.8% ███████████████████████ ★
性的 3.20 8.3% ████████████████████████ ★
物理 3.50 9.1% ███████████████████████████ ★
现象 3.80 9.9% █████████████████████████████ ★
之一 4.00 10.4% ███████████████████████████████ ★
, 4.20 10.9% ████████████████████████████████ ★
EOS 4.50 11.7% ███████████████████████████████████ ★
梯度贡献 > 5.0% 的 token: 10/20 个
这 10 个 token 贡献了 87.0% 的梯度
关键洞察:
1. 前几个 token(高频词)几乎不贡��献梯度
2. 后几个 token(内容词、难词)贡献了绝大部分梯度
3. 这意味着训练效率由「最难的几个 token」决定
4. Shuffle-R1 的 PTS + ABS 正是为了解决 RL 中这个问题
9.3 梯度裁剪(Gradient Clipping):防止梯度爆炸
问题:有时候某个 batch 的梯度特别大(比如遇到一个从来没见过的 pattern), 优化器一脚踩下去,模型参数飞了——loss 变成 NaN,训练崩溃。
解决:梯度裁剪。给它设一个上限:
如果梯度的 L2 范数 > max_norm:
把所有梯度等比例缩小,使范数 = max_norm
否则:
保持不变
梯度爆炸
↑
│ ╱╲ clip 后
│ ╱ ╲ ─ ─ ─ ─ max_norm
│ ╱ ╲── ╱
│ ╱ ╱
│╱─────── ╱
└────────────→ 训练步数
没有 clip 的话,那个尖峰会让模型崩掉
LLM 训练中几乎必加 clip,通常 max_norm=1.0。
# ��演示梯度裁剪
import torch
import torch.nn as nn
import torch.nn.functional as F
print("=== 梯度裁剪演示 ===")
print()
# 创建一个小网络,手动制造一个爆炸的梯度
linear = nn.Linear(10, 1)
x = torch.randn(5, 10)
target = torch.randn(5, 1) * 100 # 故意放大 target,制造大梯度
# 不裁剪
loss = F.mse_loss(linear(x), target)
loss.backward()
raw_grad_norm = sum(p.grad.norm().item() ** 2 for p in linear.parameters()) ** 0.5
print(f"不裁剪的梯度范数: {raw_grad_norm:.4f}")
# 重置
linear.zero_grad()
# 裁剪
loss = F.mse_loss(linear(x), target)
loss.backward()
max_norm = 1.0
nn.utils.clip_grad_norm_(linear.parameters(), max_norm)
clipped_grad_norm = sum(p.grad.norm().item() ** 2 for p in linear.parameters()) ** 0.5
print(f"裁剪后的梯度范数: {clipped_grad_norm:.4f} (上限={max_norm})")
print()
print(f"原始梯度太大 → clip 到 {max_norm} → 训练不会崩")
print()
# 实战:训练循环中加入梯度裁剪
print("实战代码片段:")
print("```python")
print("loss.backward()")
print("torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)")
print("optimizer.step()")
print("```")
print()
print("这行 clip 是你训练 LLM 时的「安全带」——")
print("平时看不出作用,但关键时刻拯救你的训练。")
=== 梯度裁剪演示 ===
不裁剪的梯度范数: 263.0871
裁剪后的梯度范数: 1.0000 (上限=1.0)
原始梯度太大 → clip 到 1.0 → 训练不会崩
实战代码片段:
```python
loss.backward()
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
```
这行 clip 是你训练 LLM 时的「安全带」——
平时看不出作用,但关键时刻拯救你的训练。
9.4 梯度累积(Gradient Accumulation):小 GPU 怎么模拟大 batch
问题:LLM 训练需要大 batch(比如 512),但你的 GPU 一次只能装下 batch=4。怎么办?
核心观察:
batch=8 的梯度 = batch=4 的梯度 + batch=4 的梯度
↑ 第一批 ↑ 第二批
梯度是可以「累加」的!所以:
目标 batch = 512,GPU 只能一次跑 32
→ 跑 512/32 = 16 次小 batch,每次只累加梯度不更新
→ 16 次后,梯度相当于 batch=512 的效果
→ 这时再 optimizer.step()
代价:训练变慢了(16 次 forward 才更新一次),但至少能训了。
和普通小 batch 的区别:
- 普通小 batch:每次 forward → backward → step,batch 是真的小
- 梯度累积:多次 forward → backward → 最后 step,等效 batch 大
# 演示梯度累积
import torch
import torch.nn.functional as F
print("=== 梯度累积演示 ===")
print()
VOCAB_SIZE = 20
model_small = MiniGPT(VOCAB_SIZE, d_model=32, num_heads=2, num_layers=1)
model_large = MiniGPT(VOCAB_SIZE, d_model=32, num_heads=2, num_layers=1)
# 复制相同参数
model_large.load_state_dict(model_small.state_dict())
# 假数据
all_data = torch.randint(1, VOCAB_SIZE, (16, 16)) # 总共 16 条
# --- 方式 A: 大 batch (batch=16) 直接训 ---
opt_large = torch.optim.SGD(model_large.parameters(), lr=0.01)
input_large = all_data[:, :-1]
target_large = all_data[:, 1:]
logits_large = model_large(input_large)
loss_large = F.cross_entropy(
logits_large.reshape(-1, VOCAB_SIZE),
target_large.reshape(-1)
)
opt_large.zero_grad()
loss_large.backward()
# 保存大 batch 的梯度
grads_large = {name: p.grad.clone() for name, p in model_large.named_parameters() if p.grad is not None}
opt_large.step()
# --- 方式 B: 小 batch (batch=4) + 梯度累积 4 次 ---
opt_small = torch.optim.SGD(model_small.parameters(), lr=0.01)
opt_small.zero_grad()
ACCUM_STEPS = 4
small_batch_size = 4
for step in range(ACCUM_STEPS):
start = step * small_batch_size
end = start + small_batch_size
mini_batch = all_data[start:end]
input_small = mini_batch[:, :-1]
target_small = mini_batch[:, 1:]
logits_small = model_small(input_small)
loss_small = F.cross_entropy(
logits_small.reshape(-1, VOCAB_SIZE),
target_small.reshape(-1)
)
# 关键:loss 除以累积步数,保持梯度量级一致
(loss_small / ACCUM_STEPS).backward()
print(f" 累积步 {step+1}/{ACCUM_STEPS}: loss={loss_small.item():.4f}, 梯度已累加(不更新)")
print()
# 保存小 batch 累积的梯度
grads_small = {name: p.grad.clone() for name, p in model_small.named_parameters() if p.grad is not None}
opt_small.step()
# 对比两种方式的梯度是否一致
print("=== 梯度对比 ===")
all_close = True
for name in grads_large:
diff = (grads_large[name] - grads_small[name]).norm().item()
status = "✅" if diff < 1e-4 else "❌"
if diff >= 1e-4:
all_close = False
print(f" {name:<30s} 差异={diff:.8f} {status}")
print()
if all_close:
print("结论: 梯度累积的梯度 == 大 batch 的梯度 ✅")
print("→ 用 4 次 batch=4 的 forward,模拟了 batch=16 的效果")
else:
print("注意: 由于顺序处理 mini-batch 时 BatchNorm 行为不同,可能有微小差异")
print("但对 LLM(只用 LayerNorm)来说是完全等价的")
=== 梯度累积演示 ===
累积步 1/4: loss=3.2385, 梯度已累加(不更新)
累积步 2/4: loss=3.1230, 梯度已累加(不更新)
累积步 3/4: loss=3.3044, 梯度已累加(不更新)
累积步 4/4: loss=3.2764, 梯度已累加(不更新)
=== 梯度对比 ===
token_emb.weight 差异=0.00000000 ✅
attn1.in_proj_weight 差异=0.00000006 ✅
attn1.in_proj_bias 差异=0.00000000 ✅
attn1.out_proj.weight 差异=0.00000006 ✅
attn1.out_proj.bias 差异=0.00000001 ✅
ffn1.0.weight 差异=0.00000002 ✅
ffn1.0.bias 差异=0.00000000 ✅
ffn1.2.weight 差异=0.00000005 ✅
ffn1.2.bias 差异=0.00000000 ✅
norm1a.weight 差异=0.00000001 ✅
norm1a.bias 差异=0.00000001 ✅
norm1f.weight 差异=0.00000001 ✅
norm1f.bias 差异=0.00000001 ✅
attn2.in_proj_weight 差异=0.00000004 ✅
attn2.in_proj_bias 差异=0.00000000 ✅
attn2.out_proj.weight 差异=0.00000004 ✅
attn2.out_proj.bias 差异=0.00000001 ✅
ffn2.0.weight 差异=0.00000002 ✅
ffn2.0.bias 差异=0.00000000 ✅
ffn2.2.weight 差异=0.00000005 ✅
ffn2.2.bias 差异=0.00000001 ✅
norm2a.weight 差异=0.00000001 ✅
norm2a.bias 差异=0.00000001 ✅
norm2f.weight 差异=0.00000001 ✅
norm2f.bias 差异=0.00000001 ✅
ln_final.weight 差异=0.00000001 ✅
ln_final.bias 差异=0.00000001 ✅
lm_head.weight 差异=0.00000013 ✅
lm_head.bias 差异=0.00000001 ✅
结论: 梯度累积的梯度 == 大 batch 的梯度 ✅
→ 用 4 次 batch=4 的 forward,模拟了 batch=16 的效果
9.5 LLM 中的梯度流动全景图
把前面学的所有东西串起来,看梯度在 LLM 训练中完整的一生:
┌─────────────────────────────────────────────────────────────────┐
│ LLM 梯度流动全景图 │
├─────────────────────────────────────────────────────────────────┤
│ │
│ [数据] │
│ ↓ │
│ [Forward: 输入 → Embedding → Transformer Blocks → LM Head] │
│ ↓ │
│ [Loss: Cross-Entropy, 每个 token 一个 loss] │
│ │ │
│ │ ← 关键观察点 1: Token 级梯度 │
│ │ 简单 token (的/是) → loss 小 → 梯度小 │
│ │ 困难 token (巴黎) → loss 大 → 梯度大 │
│ │ 训练主要被「难 token」驱动 │
│ ↓ │
│ [Backward: 梯度从 LM Head 往回传] │
│ │ │
│ ├── LayerNorm: 归一化,梯度稳定 │
│ ├── FFN: 两层 Linear,梯度可能较大 │
│ ├── Attention: QKV 三个投影 + Output 投影 │
│ │ │ │
│ │ └── ← 关键观察点 2: 注意力头梯度差异 │
│ │ 有的头梯度大(活跃),有的头梯度小(冗余) │
│ ├── 残差连接 ──→ 梯度抄近路,不会消失 ← 关键! │
│ │ │
│ ↓ 回到 Embedding 层(梯度最小) │
│ │
│ [梯度处理] │
│ ├── Gradient Clipping: 防爆炸,max_norm≈1.0 │
│ ├── Gradient Accumulation: 小 GPU 模拟大 batch │
│ └── (RL 特化) PTS+ABS: 筛选高贡献 rollout │
│ │
│ [参数更新: optimizer.step()] │
│ ↓ │
│ [下一个 batch,重复] │
│ │
└─────────────────────────────────────────────────────────────────┘
三个最关键的理解:
-
残差连接 = 梯度高速公路:没有它,深层 Transformer 的梯度会消失(像 RNN 一样)。 残差连接让梯度可以「跳过」FFN 和 Attention,直接往回传。
-
Token 级梯度不均:简单词几乎不贡献梯度,训练由难词驱动。 这解释了为什么 LLM 在「知识密集型」任务上提升慢—— 知识词占比小,梯度信号也少。
-
RL 训练放大梯度不均:SFT 里至少每个 token 都有明确的标签, 但 RL 里很多 rollout 的 advantage 接近 0 → 梯度信号更稀疏。 Shuffle-R1 的 PTS+ABS 就是来解决这个的。
# 可视化:残差连接如何保护梯度流动
print("=== 残差连接与梯度流动 ===")
print()
print("没有残差连接(像传统网络):")
print(" Input → Layer1 → Layer2 → ... → Layer32 → Output")
print(" 梯度: Output → Layer32→...→ Layer1 → Input")
print(" 问题: 经过 32 层乘积,梯度可能衰减到 0(梯度消失)")
print()
print("有残差连接(Transformer 做法):")
print(" Input → [Layer1 + Input] → [Layer2 + prev] → ... → Output")
print(" 梯度: 两条路——")
print(" 主路: Output → Layer32 → ... → Layer1 → Input (可能衰减)")
print(" 短路: Output → Input (直接跳过所有层!) ← 梯度高速公路")
print()
print("因为短路的存在,至少有一部分梯度能无损到达底层。")
print("这就是为什么 Transformer 可以堆 100+ 层还��能训。")
print()
# 模拟梯度在不同深度下的衰减
depths = [1, 4, 8, 16, 32, 64]
print("模拟:初始梯度=1.0,经过不同层数后的衰减")
print(f"{'层数':>6s} {'无残差':>12s} {'有残差':>12s}")
print("-" * 32)
decay_per_layer = 0.95 # 每层衰减 5%
skip_ratio = 0.3 # 残差路径占 30%
for d in depths:
no_skip = decay_per_layer ** d
with_skip = no_skip * (1 - skip_ratio) + skip_ratio
print(f"{d:>6d} {no_skip:>12.6f} {with_skip:>12.6f}")
print()
print("结论: 32 层后,无残差梯度只剩 20%,有残差还能保持 44%")
print("层数越多,残差连接的价值越大。")
=== 残差连接与梯度流动 ===
没有残差连接(像传统网络):
Input → Layer1 → Layer2 → ... → Layer32 → Output
梯度: Output → Layer32→...→ Layer1 → Input
问题: 经过 32 层乘积,梯度可能衰减到 0(梯度消失)
有残差连接(Transformer 做法):
Input → [Layer1 + Input] → [Layer2 + prev] → ... → Output
梯度: 两条路——
主路: Output → Layer32 → ... → Layer1 → Input (可能衰减)
短路: Output → Input (直接跳过所有层!) ← 梯度高速公路
因为短路的存在,至少有一部分梯度能无损到达底层。
这就是为什么 Transformer 可以堆 100+ 层还能训。
模拟:初始梯度=1.0,经过不同层数后的衰减
层数 无残差 有残差
--------------------------------
1 0.950000 0.965000
4 0.814506 0.870154
8 0.663420 0.764394
16 0.440127 0.608089
32 0.193711 0.435598
64 0.037524 0.326267
结论: 32 层后,无残差梯度只剩 20%,有残差还能保持 44%
层数越多,残差连接的价值越大。
9.6 梯度视角小结
| 概念 | 一句话 | 为什么重要 |
|---|---|---|
| 反向传播 | loss → 链式法则 → 每个参数的梯度 | 训练的基础,没有它就没有学习 |
| Token 级梯度 | 难 token 梯度大,简单 token 接近 0 | 解释了为什么训练效率由「难样本」决定 |
| 梯度裁剪 | 梯度范数 > max_norm 时等比缩小 | 防训练崩溃的安全带 |
| 梯度累积 | 多次小 batch 的梯度累加后一起更新 | 小 GPU 训练大模型的救命技巧 |
| 残差连接 | 梯度可以跳过层直接回传 | Transformer 能堆 100+ 层的根本原因 |
| RL 梯度稀疏 | RL 训练中有效梯度更少 | Shuffle-R1 等工作的动机 |
梯度是 loss 和参数更新之间的「翻译官」—— 它把「这个 batch 哪里做得不好」翻译成「每个参数应该怎么调」。 理解梯度,才能真正理解模型是怎么学习的。
10. 从对话到 Token
类比:你要给朋友写信。你脑子里有「想说的内容」,但邮局只收「写在纸上的字」。 Chat Template 就是那个「把想法写成信的格式」—— 你要先写「亲爱的某某」,再写正文,最后署名。 LLM 也一样:你的对话消息(messages)不能直接喂给模型,必须先用 Chat Template 「�格式化」成 token。
10.1 先看真实的训练数据长什么样
真实 LLM 训练数据是 JSONL 格式(每行一个 JSON 对象),这是 OpenAI API 兼容的标准:
{"messages": [{"role": "system", "content": "你是数学助手"}, {"role": "user", "content": "1+1=?"}, {"role": "assistant", "content": "1+1=2"}]}
{"messages": [{"role": "user", "content": "你好"}, {"role": "assistant", "content": "你好!有什么可以帮你?"}]}
{"messages": [{"role": "system", "content": "你是翻译官"}, {"role": "user", "content": "Hello"}, {"role": "assistant", "content": "你好"}]}
核心问题:上面这个 JSON 对象,到底是怎么变成模型看到的 input_ids 和 labels 的?
我们要搞懂三个问题:
- 拼接:messages 列表是怎么拼成一段连续的 token 序列的?
- 分割:哪些 token 是「给模型看的上下文」,哪些是「要模型学习的答案」?
- Loss:特殊标记(如
<|im_start|>)在计算 loss 时怎么处理?
下面用真实的 transformers 库来一步步看。
# ============================================================
# 用真实的 transformers 库看 Chat Template 做了什么
# ============================================================
print("=== 真实 tokenizer 演示:Chat Template 怎么把 messages 变成 token ===\n")
# 尝试加载 Qwen2.5 的 tokenizer(如果是第一次运行会自动下载)
try:
from transformers import AutoTokenizer
# Qwen2.5-0.5B 的 tokenizer 很小(~30MB),下载快
# 它的 chat template 是 ChatML 风格,和 DeepSeek、Qwen 系一致
MODEL_NAME = "Qwen/Qwen2.5-0.5B-Instruct"
print(f"加载 tokenizer: {MODEL_NAME}")
print("(首次运行会下载 ~30MB,请��稍候...)\n")
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME, trust_remote_code=True)
# 先看看 tokenizer 有哪些 special token
print("=== Tokenizer 的 Special Token ===")
print(f" bos_token: {repr(tokenizer.bos_token)} → id={tokenizer.bos_token_id}")
print(f" eos_token: {repr(tokenizer.eos_token)} → id={tokenizer.eos_token_id}")
print(f" pad_token: {repr(tokenizer.pad_token)} → id={tokenizer.pad_token_id}")
print(f" 词表大小: {len(tokenizer)} 个 token")
print()
# 看看 chat template 本身(就是个 Jinja2 模板字符串!)
print("=== Chat Template(Jinja2 模板)===")
ct = tokenizer.chat_template
if ct:
# 只显示前 500 个字符
print(ct[:500])
print("...")
print()
# ============================================================
# 核心演示:apply_chat_template 到底做了什么?
# ============================================================
messages = [
{"role": "system", "content": "你是数学助手"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2"},
]
print("=== 输入:messages 列表 ===")
import json
print(json.dumps(messages, ensure_ascii=False, indent=2))
print()
# Step 1: tokenize=False — 看渲染后的文本(人类可读)
print("=== Step 1: apply_chat_template(tokenize=False) — 渲染成文本 ===")
rendered_text = tokenizer.apply_chat_template(
messages,
tokenize=False, # 不转 token,先看文本
add_generation_prompt=False # 不加生成提示(训练时不需要)
)
print("渲染后的文本(注意 special token 的位置):")
print(repr(rendered_text))
print()
print("可视化:")
print(rendered_text)
print()
# Step 2: tokenize=True — 直接得到 input_ids
print("=== Step 2: apply_chat_template(tokenize=True) — 直接得到 token IDs ===")
input_ids = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt" # 返回 PyTorch tensor
)
print(f"input_ids 形状: {input_ids.shape}") # [batch=1, seq_len]
print(f"input_ids 内容: {input_ids[0].tolist()}")
print(f"序列长度: {len(input_ids[0])}")
print()
# Step 3: 每个 token 解码出来看
print("=== Step 3: 逐个 token 解码 — 看每段是什么 ===")
print(f"{'Position':<5s} {'Token ID':>8s} {'解码文本':<30s} {'说明'}")
print("-" * 75)
for i, tid in enumerate(input_ids[0].tolist()):
decoded = tokenizer.decode([tid])
# 判断 token 类型
if tid == tokenizer.bos_token_id:
note = "← BOS (开始标记)"
elif tid == tokenizer.eos_token_id:
note = "← EOS (结束标记)"
elif tid >= len(tokenizer) - 20: # 特殊 token 通常在词表末尾
note = "← special token"
elif tid == 151644: # Qwen 的 <|im_start|>
note = "← <|im_start|> 特殊标记"
elif tid == 151645: # Qwen 的 <|im_end|>
note = "← <|im_end|> 特殊标记"
else:
note = ""
print(f"{i:<5d} {tid:>8d} {decoded:<30s} {note}")
print(f"\n重要观察:")
print(f" 1. 文本被拼成了一段连续的 token 序列(不是三个独立的数组)")
print(f" 2. system/user/assistant 之间用 <|im_start|> 和 <|im_end|> 分割")
print(f" 3. 整段序列包括:系统提示 + 用户问题 + 助手回答")
print(f" 4. 模型会一次性看到这整个序列(通过 causal attention mask)")
except ImportError:
print("transformers 未安装。运行: pip install transformers")
print()
print("手动模拟 Qwen2.5 的 chat template 行为...")
print()
# 模拟 Qwen2.5 的 token IDs(真实值)
print("Qwen2.5 Chat Template 的渲染规则(ChatML 格式):")
print(' <|im_start|>system')
print(' {system_content}')
print(' <|im_end|>')
print(' <|im_start|>user')
print(' {user_content}')
print(' <|im_end|>')
print(' <|im_start|>assistant')
print(' {assistant_content}')
print(' <|im_end|>')
print()
print("用我们自己实现一个简化版来演示...")
except Exception as e:
print(f"加载失败: {e}")
print("用简化版演示...")
=== 真实 tokenizer 演示:Chat Template 怎么把 messages 变成 token ===
transformers 未安装。运行: pip install transformers
手动模拟 Qwen2.5 的 chat template 行为...
Qwen2.5 Chat Template 的渲染规则(ChatML 格式):
<|im_start|>system
{system_content}
<|im_end|>
<|im_start|>user
{user_content}
<|im_end|>
<|im_start|>assistant
{assistant_content}
<|im_end|>
用我们自己实现一个简化版来演示...
10.2 对照实验:手工拼接 vs 官方 API
上面我们用 tokenizer.apply_chat_template() 一步到位了。但是它内部到底做了啥?有没有什么隐藏操作?
我们来做一个对照实验:
| 方法 | 怎么做 |
|---|---|
| 方法一(官方) | 调用 tokenizer.apply_chat_template(messages) |
| 方法二(手工) | 自己按 ChatML 格式字符串拼接,然后 tokenizer.encode() |
如果两边结果相同,就证明了 apply_chat_template 内部没有魔法,就是字符串拼接 + tokenize。
还是用这个例子:
{"messages": [
{"role": "system", "content": "你是数学助手"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2"}
]}
ChatML 格式的模板规则(这就是 Jinja2 模板在做的事):
每条消息 -> <|im_start|>{role}\n{content}<|im_end|>\n
拆成步骤:
Step 1: system 消息
<|im_start|>system\n你是数学助手<|im_end|>\n
└────┬────┘└─┬─┘└─��─┬──┘└────┬───┘└───┬───┘└┬┘
特殊标记 角色 换行 内容 特殊标记 换行
Step 2: user 消息(紧跟在 system 后面)
...<|im_end|>\n<|im_start|>user\n1+1=?<|im_end|>\n
└──系统消息的结尾──┘└──紧跟着用户消息──┘
Step 3: assistant 消息(紧跟在 user 后面)
...<|im_end|>\n<|im_start|>assistant\n1+1=2<|im_end|>\n
└──用户消息的结尾──┘└────紧跟着助手消息────┘
关键:所有消息被拼成一段连续的文本,没有空格、没有换行分隔、没有数组标记。
模型通过 <|im_start|> 和 <|im_end|> 这些特殊 token 来区分消息边界。
下面我们同时用两种方法,把中间步骤都打印出来,最后逐项对照:
# ============================================================
# 10.3 对照实验:自己手工拼接 vs 官方 API —— 证明一模一样
# ============================================================
# 核心思想:apply_chat_template 内部没有魔法,就是按 ChatML 格式做字符串拼接。
# 我们自己手工拼一遍,和官方结果逐项对照,证明完全一致。
# 如果真实 transformers tokenizer 没加载成功,就用一个离线可运行的简化版。
if "tokenizer" not in globals():
print("未检测到真实 tokenizer,使用 SimpleChatTokenizer 做离线演示。")
class SimpleChatTokenizer:
"""最小可用的 ChatML tokenizer,用来证明 template = 拼字符串 + tokenize"""
def __init__(self):
self.special = {"<|im_start|>": 100001, "<|im_end|>": 100002}
self.vocab = {"\n": 10}
self.reverse = {10: "\n", 100001: "<|im_start|>", 100002: "<|im_end|>"}
def convert_tokens_to_ids(self, token):
return self.special.get(token, self.vocab.get(token, -1))
def apply_chat_template(self, messages, tokenize=False):
text = "".join(
f"<|im_start|>{m['role']}\n{m['content']}<|im_end|>\n"
for m in messages
)
return self.encode(text, add_special_tokens=False) if tokenize else text
def encode(self, text, add_special_tokens=False):
ids = []
i = 0
while i < len(text):
matched = False
for tok, tid in self.special.items():
if text.startswith(tok, i):
ids.append(tid)
i += len(tok)
matched = True
break
if matched:
continue
ch = text[i]
if ch not in self.vocab:
self.vocab[ch] = 1000 + len(self.vocab)
self.reverse[self.vocab[ch]] = ch
ids.append(self.vocab[ch])
i += 1
return ids
def decode(self, ids):
return "".join(self.reverse[i] for i in ids)
tokenizer = SimpleChatTokenizer()
print("=" * 70)
print("对照实验:手工拼接 vs 官方 apply_chat_template")
print("=" * 70)
# ============================================================
# 准备对话数据
# ============================================================
messages = [
{"role": "system", "content": "你是一个乐于助人的助手。"},
{"role": "user", "content": "1+1等于几?"},
{"role": "assistant", "content": "1+1等于2。"},
]
print("\n原始对话:")
for i, msg in enumerate(messages):
print(f" [{i}] {msg['role']}: {msg['content']}")
# ============================================================
# 先看看特殊 token 的 ID(ChatML 格式的骨架)
# ============================================================
IM_START_ID = tokenizer.convert_tokens_to_ids("<|im_start|>")
IM_END_ID = tokenizer.convert_tokens_to_ids("<|im_end|>")
NEWLINE_ID = tokenizer.convert_tokens_to_ids("\n")
print(f"\n特殊 token ID:")
print(f" '<|im_start|>' -> ID = {IM_START_ID}")
print(f" '<|im_end|>' -> ID = {IM_END_ID}")
print(f" '\\n' -> ID = {NEWLINE_ID}")
# ============================================================
# 方法一:官方 API —— apply_chat_template
# ============================================================
print("\n" + "=" * 70)
print("方法一:官方 API —— apply_chat_template")
print("=" * 70)
# tokenize=False -> 得到字符串(人类可读)
official_text = tokenizer.apply_chat_template(messages, tokenize=False)
# tokenize=True -> 得到 token ID 列表
official_ids = tokenizer.apply_chat_template(messages, tokenize=True)
print(f"\n官方渲染的文本(repr):")
print(f" {repr(official_text)}")
print(f"\n官方渲染的文本(人类可读):")
print(f" {official_text}")
print(f"\n官方 token IDs(完整列表):")
print(f" {official_ids}")
# 逐 token 解码官方结果
print(f"\n官方结果逐 token 解码:")
print(f" {'Position':<5s} {'ID':>7s} {'解码':<18s} {'标记'}")
print(f" {'-'*55}")
for i, tid in enumerate(official_ids):
decoded = repr(tokenizer.decode([tid]))
marker = "<-- 特殊token" if tid in (IM_START_ID, IM_END_ID) else ""
print(f" [{i:>3d}] {tid:>7d} {decoded:<18s} {marker}")
print(f" 总 token 数:{len(official_ids)}")
# ============================================================
# 方法二:自己手工拼接(模拟 apply_chat_template 内部逻辑)
# ============================================================
print("\n" + "=" * 70)
print("方法二:手工拼接(模拟 ChatML 格式)")
print("=" * 70)
# ChatML 格式规则:
# 每条消息 = <|im_start|>角色\n内容<|im_end|>\n
# 所有消息按顺序首尾相连,构成一个连续字符串
# 这就是 apply_chat_template 内部 Jinja2 模板在做的事!
print("""
ChatML 拼接规则(和 Jinja2 模板做的事情一模一样):
消息1_str = "<|im_start|>system\\n你是一个乐于助人的助手。<|im_end|>\\n"
消息2_str = "<|im_start|>user\\n1+1等于几?<|im_end|>\\n"
消息3_str = "<|im_start|>assistant\\n1+1等于2。<|im_end|>\\n"
|
v
最终序列 = 消息1_str + 消息2_str + 消息3_str
= 一段连续的字符串!
""")
all_text = "" # 累积文本
all_ids = [] # 累积 token ID
print("开始逐步拼接……\n")
for step, msg in enumerate(messages):
role = msg["role"]
content = msg["content"]
# 按照 ChatML 格式构造这一段
segment_text = f"<|im_start|>{role}\n{content}<|im_end|>\n"
# 用 tokenizer 把这段文本编码(不加 add_special_tokens,因为这不是独立句子)
segment_ids = tokenizer.encode(segment_text, add_special_tokens=False)
before_len = len(all_ids)
all_text += segment_text # <-- 字符串拼接!
all_ids.extend(segment_ids) # <-- token 拼接!
print(f"--- 第 {step+1} 步:拼接 {role} 消息 ---")
print(f" 这一段文本:")
print(f" {repr(segment_text)}")
print(f" 这一段 token IDs ({len(segment_ids)} 个):")
print(f" {segment_ids}")
print(f" 累积 token 数:{before_len} -> {len(all_ids)}(+{len(segment_ids)})")
print(f" 当前累积文本 repr:")
print(f" {repr(all_text)}")
print()
# ============================================================
# ★ 核心对照:官方 vs 手工 —— 逐项验证
# ============================================================
print("=" * 70)
print("对照验证:官方 API vs 手工拼接")
print("=" * 70)
# 验证 1:文本字符串是否完全一致?
print(f"\n[验证 1] 文本字符串对比")
print(f" 官方文本 == 手工文本 : {official_text == all_text}")
if official_text != all_text:
print(f" 官方长度 = {len(official_text)}, 手工长度 = {len(all_text)}")
# 找出第一个不同字符
for i, (a, b) in enumerate(zip(official_text, all_text)):
if a != b:
print(f" 第一�个差异在位置 {i}:官方={repr(a)} vs 手工={repr(b)}")
print(f" 官方周围: ...{repr(official_text[max(0,i-10):i+10])}...")
print(f" 手工周围: ...{repr(all_text[max(0,i-10):i+10])}...")
break
else:
print(f" 字符串完全一致!手工拼出来的和官方 API 一模一样!")
# 验证 2:token ID 序列是否完全一致?
print(f"\n[验证 2] token ID 序列对比")
manual_ids_list = list(all_ids)
print(f" 官方 IDs == 手工 IDs : {official_ids == manual_ids_list}")
if official_ids != manual_ids_list:
print(f" 官方 {len(official_ids)} 个 token,手工 {len(manual_ids_list)} 个 token")
for i in range(min(len(official_ids), len(manual_ids_list))):
if official_ids[i] != manual_ids_list[i]:
print(f" 第一个差异在位置 {i}:")
print(f" 官方 ID={official_ids[i]} -> {repr(tokenizer.decode([official_ids[i]]))}")
print(f" 手工 ID={manual_ids_list[i]} -> {repr(tokenizer.decode([manual_ids_list[i]]))}")
break
else:
print(f" {len(official_ids)} 个 token ID 完全一致!")
# 验证 3:两个序列反向 decode 回去,能还原成一样的文本吗?
print(f"\n[验证 3] 反向 decode 验证")
off_decoded = tokenizer.decode(official_ids)
man_decoded = tokenizer.decode(manual_ids_list)
print(f" 官方 IDs decode: {repr(off_decoded)}")
print(f" 手工 IDs decode: {repr(man_decoded)}")
print(f" 两者一致: {off_decoded == man_decoded}")
# ============================================================
# ★ 最终总结
# ============================================================
print("\n" + "=" * 70)
print("结论")
print("=" * 70)
print("""
apply_chat_template 的 Jinja2 模板,内部做的事情就是:
1. 遍历 messages 列表
2. 每条消息按 "<|im_start|>角色\\n内容<|im_end|>\\n" 格式化成字符串
3. 把所有字符串按顺序首尾相连,拼成一段连续的文本
4. tokenize 这段文本,得到一串 token ID
没有魔法,没有隐藏操作。
你手工做的和官方 API 做的,结果一模一样。
理解了这个,你就知道了:
训练数据是怎么从 JSON 变成一行一行的 token 序列的。
""")
未检测到真实 tokenizer,使用 SimpleChatTokenizer 做离线演示。
======================================================================
对照实验:手工拼接 vs 官方 apply_chat_template
======================================================================
原始对话:
[0] system: 你是一个乐于助人的助手。
[1] user: 1+1等于几?
[2] assistant: 1+1等于2。
特殊 token ID:
'<|im_start|>' -> ID = 100001
'<|im_end|>' -> ID = 100002
'\n' -> ID = 10
======================================================================
方法一:官方 API —— apply_chat_template
======================================================================
官方渲染的文本(repr):
'<|im_start|>system\n你是一个�乐于助人的助手。<|im_end|>\n<|im_start|>user\n1+1等于几?<|im_end|>\n<|im_start|>assistant\n1+1等于2。<|im_end|>\n'
官方渲染的文本(人类可读):
<|im_start|>system
你是一个乐于助人的助手。<|im_end|>
<|im_start|>user
1+1等于几?<|im_end|>
<|im_start|>assistant
1+1等于2。<|im_end|>
官方 token IDs(完整列表):
[100001, 1001, 1002, 1001, 1003, 1004, 1005, 10, 1006, 1007, 1008, 1009, 1010, 1011, 1012, 1013, 1014, 1012, 1015, 1016, 100002, 10, 100001, 1017, 1001, 1004, 1018, 10, 1019, 1020, 1019, 1021, 1011, 1022, 1023, 100002, 10, 100001, 1024, 1001, 1001, 1025, 1001, 1003, 1024, 1026, 1003, 10, 1019, 1020, 1019, 1021, 1011, 1027, 1016, 100002, 10]
官方结果逐 token 解码:
Position ID 解码 标记
-------------------------------------------------------
[ 0] 100001 '<|im_start|>' <-- 特殊token
[ 1] 1001 's'
[ 2] 1002 'y'
[ 3] 1001 's'
[ 4] 1003 't'
[ 5] 1004 'e'
[ 6] 1005 'm'
[ 7] 10 '\n'
[ 8] 1006 '你'
[ 9] 1007 '是'
[ 10] 1008 '一'
[ 11] 1009 '个'
[ 12] 1010 '乐'
[ 13] 1011 '于'
[ 14] 1012 '助'
[ 15] 1013 '人'
[ 16] 1014 '的'
[ 17] 1012 '助'
[ 18] 1015 '手'
[ 19] 1016 '。'
[ 20] 100002 '<|im_end|>' <-- 特殊token
[ 21] 10 '\n'
[ 22] 100001 '<|im_start|>' <-- 特殊token
[ 23] 1017 'u'
[ 24] 1001 's'
[ 25] 1004 'e'
[ 26] 1018 'r'
[ 27] 10 '\n'
[ 28] 1019 '1'
[ 29] 1020 '+'
[ 30] 1019 '1'
[ 31] 1021 '等'
[ 32] 1011 '于'
[ 33] 1022 '几'
[ 34] 1023 '?'
[ 35] 100002 '<|im_end|>' <-- 特殊token
[ 36] 10 '\n'
[ 37] 100001 '<|im_start|>' <-- 特殊token
[ 38] 1024 'a'
[ 39] 1001 's'
[ 40] 1001 's'
[ 41] 1025 'i'
[ 42] 1001 's'
[ 43] 1003 't'
[ 44] 1024 'a'
[ 45] 1026 'n'
[ 46] 1003 't'
[ 47] 10 '\n'
[ 48] 1019 '1'
[ 49] 1020 '+'
[ 50] 1019 '1'
[ 51] 1021 '等'
[ 52] 1011 '于'
[ 53] 1027 '2'
[ 54] 1016 '。'
[ 55] 100002 '<|im_end|>' <-- 特殊token
[ 56] 10 '\n'
总 token 数:57
======================================================================
方法二:手工拼接(模拟 ChatML 格式)
======================================================================
ChatML 拼接规则(和 Jinja2 模板做的事情一模一样):
消息1_str = "<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n"
消息2_str = "<|im_start|>user\n1+1等于几?<|im_end|>\n"
消息3_str = "<|im_start|>assistant\n1+1等于2。<|im_end|>\n"
|
v
最终序列 = 消息1_str + 消息2_str + 消息3_str
= 一段连续的字符串!
开始逐步拼接……
--- 第 1 步:拼接 system 消息 ---
这一段文本:
'<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n'
这一段 token IDs (22 个):
[100001, 1001, 1002, 1001, 1003, 1004, 1005, 10, 1006, 1007, 1008, 1009, 1010, 1011, 1012, 1013, 1014, 1012, 1015, 1016, 100002, 10]
累积 token 数:0 -> 22(+22)
当前累积文本 repr:
'<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n'
--- 第 2 步:拼接 user 消息 ---
这一段文本:
'<|im_start|>user\n1+1等于几?<|im_end|>\n'
这一段 token IDs (15 个):
[100001, 1017, 1001, 1004, 1018, 10, 1019, 1020, 1019, 1021, 1011, 1022, 1023, 100002, 10]
累积 token 数:22 -> 37(+15)
当前累积文本 repr:
'<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n<|im_start|>user\n1+1等于几?<|im_end|>\n'
--- 第 3 步:拼接 assistant 消息 ---
这一段文本:
'<|im_start|>assistant\n1+1等于2。<|im_end|>\n'
这一段 token IDs (20 个):
[100001, 1024, 1001, 1001, 1025, 1001, 1003, 1024, 1026, 1003, 10, 1019, 1020, 1019, 1021, 1011, 1027, 1016, 100002, 10]
累积 token 数:37 -> 57(+20)
当前累积文本 repr:
'<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n<|im_start|>user\n1+1等于几?<|im_end|>\n<|im_start|>assistant\n1+1等于2。<|im_end|>\n'
======================================================================
对照验证:官方 API vs 手工拼接
======================================================================
[验证 1] 文本字符串对比
官方文本 == 手工文本 : True
字符串完全一致!手工拼出来的和官方 API 一模一样!
[验证 2] token ID 序列对比
官方 IDs == 手工 IDs : True
57 个 token ID 完全一致!
[验证 3] 反向 decode 验证
官方 IDs decode: '<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n<|im_start|>user\n1+1等于几?<|im_end|>\n<|im_start|>assistant\n1+1等于2。<|im_end|>\n'
手工 IDs decode: '<|im_start|>system\n你是一个乐于助人的助手。<|im_end|>\n<|im_start|>user\n1+1等于几?<|im_end|>\n<|im_start|>assistant\n1+1等于2。<|im_end|>\n'
两者一致: True
======================================================================
结论
======================================================================
apply_chat_template 的 Jinja2 模板,内部做的事情就是:
1. 遍历 messages 列表
2. 每条消息按 "<|im_start|>角色\n内容<|im_end|>\n" 格式化成字符串
3. 把所有字符串按顺序首尾相连,拼成一段连续的文本
4. tokenize 这段文本,得到一串 token ID
没有魔法,没有隐藏操作。
你手工做的和官方 API 做的,结果一模一样。
理解了这个,你就知道了:
训练数据是怎么从 JSON 变成一行一行的 token 序列的。
10.3 关键一步:构造 labels — 特殊 token 在 Loss 中怎么处理?
现在我们有了 input_ids(模型看到的所有 token),但训练还需要 labels(告诉模型「你要学哪些 token」)。
类比:英语考试,给你一篇阅读理解文章 + 问题 + 参考答案。
- 文章(system prompt)→ 你要读,但不需要默写 → labels = IGNORE
- 问题(user message)→ 你要读,但不需要背 → labels = IGNORE
- 答案(assistant message)→ 这才是你要学会写的 → labels = 真实的 token ID
- 标点/格式(special token)→ 这些都是格式符号,不需要学会预测 → labels = IGNORE
input_ids: [151644, 8948, 198, 9942, 10603, 107659, 113738, 151645, 198,
151644, 872, 198, 16, 17, 18, 19, 20, 151645, 198,
151644, 78191, 198, 16, 17, 18, 19, 18, 151645, 198]
├── system 框架+内容 ──┤├── user 框架+内容 ──┤├─ assistant 内容 ─┤
labels: [-100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, 16, 17, 18, 19, 18, -100, -100]
↑ 全都不算 loss(system+user+特殊标记) ↑ 只这里算 ↑ 也不算
为什么 labels 用 -100?
PyTorch 的 CrossEntropyLoss 有一个 ignore_index 参数。默认值是 -100。
所有 label 等于 ignore_index 的位置:不计算 loss,不产生梯度。
CrossEntropyLoss(ignore_index=-100) 的行为:
label = 5 → 正常计算: loss = -log(pred[5])
label = -100 → 跳过: loss = 0, grad = 0
下面用代码把 labels 构造出来,并验证 loss 计算确实跳过了 -100 的位置:
# ============================================================
# labels 构造 + ignore_index 的底层原理
# ============================================================
import torch
import torch.nn.functional as F
print("=== labels 构造 + ignore_index 验证 ===\n")
# 复用前面的 vocab 和 tokenize
vocab = {
"<|im_start|>": 151644, "<|im_end|>": 151645,
"system": 8948, "user": 872, "assistant": 78191,
"你": 9942, "是": 10603, "数学": 107659, "助手": 113738,
"1": 16, "+": 17, "2": 18, "=": 19, "?": 20, "\n": 198,
}
id_to_word = {v: k for k, v in vocab.items()}
def encode(text):
tokens = []
i = 0
while i < len(text):
matched = None
for word in sorted(vocab.keys(), key=lambda x: -len(x)):
if text[i:].startswith(word):
matched = word
break
if matched:
tokens.append(vocab[matched])
i += len(matched)
else:
tokens.append(0)
i += 1
return tokens
messages = [
{"role": "system", "content": "你是数学助手"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2"},
]
IM_START = "<|im_start|>"
IM_END = "<|im_end|>"
IGNORE = -100 # PyTorch 的默认 ignore_index
# ============================================================
# Step 1: 构造 input_ids
# ============================================================
print("Step 1: 构造 input_ids")
all_text = ""
for msg in messages:
all_text += f"{IM_START}{msg['role']}\n{msg['content']}{IM_END}\n"
input_ids = torch.tensor([encode(all_text)])
print(f" input_ids: {input_ids[0].tolist()}")
print()
# ============================================================
# Step 2: 构造 labels — 追踪每个 token 的来源
# ============================================================
print("Step 2: 构造 labels(每个 token 逐一标注)")
print()
labels = torch.full_like(input_ids, IGNORE) # 初始全部 IGNORE
pos = 0
for msg in messages:
role = msg["role"]
content = msg["content"]
# 头部: <|im_start|>role\n → IGNORE(本来就是 IGNORE,可以显式确认)
header = f"{IM_START}{role}\n"
hlen = len(encode(header))
# 这 hlen 个 token 已经是 IGNORE
pos += hlen
# 内容
cids = encode(content)
if role == "assistant":
# ★ 只有 assistant 的内容才填入真实 label
for cid in cids:
labels[0, pos] = cid
pos += 1
else:
# system/user 的内容保持 IGNORE
pos += len(cids)
# 尾部: <|im_end|>\n → IGNORE
footer = f"{IM_END}\n"
flen = len(encode(footer))
pos += flen
print(f" input_ids: {input_ids[0].tolist()}")
print(f" labels: {labels[0].tolist()}")
print()
# 逐 token 对比
print("逐 token 对比 (L=算loss, .=忽略):")
print(f" {'Pos':<4s} {'input_id':>8s} {'token':<18s} {'label':>8s} {'来源'}")
print(f" {'-'*4} {'-'*8} {'-'*18} {'-'*8} {'-'*30}")
pos = 0
for msg in messages:
role = msg["role"]
content = msg["content"]
header_ids = encode(f"{IM_START}{role}\n")
for hid in header_ids:
word = id_to_word.get(hid, "???")
lid = labels[0, pos].item()
m = "." if lid == IGNORE else "L"
print(f" [{pos:<2d}] {hid:>8d} {word:<18s} {lid:>8d} {m} 框架({role})")
pos += 1
content_ids = encode(content)
for cid in content_ids:
word = id_to_word.get(cid, "???")
lid = labels[0, pos].item()
m = "L" if lid != IGNORE else "."
note = f"{m} [{role}内容]"
print(f" [{pos:<2d}] {cid:>8d} {word:<18s} {lid:>8d} {note}")
pos += 1
footer_ids = encode(f"{IM_END}\n")
for fid in footer_ids:
word = id_to_word.get(fid, "???")
lid = labels[0, pos].item()
m = "." if lid == IGNORE else "L"
print(f" [{pos:<2d}] {fid:>8d} {word:<18s} {lid:>8d} {m} 框架标记")
pos += 1
n_compute = (labels != IGNORE).sum().item()
n_ignore = (labels == IGNORE).sum().item()
print(f"\n 统计: 算 loss 的 token={n_compute} 个, 忽略的 token={n_ignore} 个")
print(f" 有效训练信号占比: {n_compute}/{n_compute+n_ignore} = {n_compute/(n_compute+n_ignore)*100:.1f}%")
# ============================================================
# Step 3: 验证 ignore_index 真的跳过了 -100 的位置
# ============================================================
print(f"\n{'='*60}")
print("Step 3: 验证 ignore_index 机制")
print("=" * 60)
# 模拟模型输出 logits(随机)
VOCAB_SIZE = max(vocab.values()) + 1
torch.manual_seed(42)
logits = torch.randn(1, input_ids.shape[1], VOCAB_SIZE)
# 方式 A: 使用 ignore_index(正常做法)
loss_with_ignore = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE),
labels.reshape(-1),
ignore_index=IGNORE
)
print(f"\n使用 ignore_index={IGNORE} 的 loss: {loss_with_ignore.item():.4f}")
# 方式 B: 手工验证 — 只算 labels != IGNORE 的位置
losses = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE),
labels.reshape(-1),
ignore_index=IGNORE,
reduction='none' # 不做平均,保留每个位置的 loss
)
losses_reshaped = losses.view(input_ids.shape) # [1, seq_len]
print(f"\n每个位置的 loss (ignore_index 已自动把 -100 位置归零):")
for i in range(input_ids.shape[1]):
tid = input_ids[0, i].item()
lid = labels[0, i].item()
pos_loss = losses_reshaped[0, i].item()
word = id_to_word.get(tid, "???")
if lid == IGNORE:
print(f" [{i:2d}] loss={pos_loss:.4f} ← IGNORE 位置, loss=0")
else:
print(f" [{i:2d}] loss={pos_loss:.4f} ← 有效位置! 预测'{word}'")
# 手工算平均
manual_avg = losses_reshaped[labels != IGNORE].mean()
print(f"\n手工平均(只算有效位置): {manual_avg:.4f}")
print(f"PyTorch cross_entropy 结果: {loss_with_ignore.item():.4f}")
print(f"一致 ✅" if abs(manual_avg.item() - loss_with_ignore.item()) < 1e-5 else "不一致 ❌")
# ============================================================
# Step 4: 如果不用 ignore_index 会怎样?(对比)
# ============================================================
print(f"\n{'='*60}")
print("Step 4: 对比 — 如果不用 ignore_index")
print("=" * 60)
# 把 labels 里的 -100 替换为一个真实 token ID(比如 0=UNK)
labels_bad = labels.clone()
labels_bad[labels_bad == IGNORE] = 0
loss_bad = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE),
labels_bad.reshape(-1)
)
print(f"把所有 -100 改成 0 后的 loss: {loss_bad.item():.4f}")
print(f"正确的 loss (忽略 -100): {loss_with_ignore.item():.4f}")
print(f"差异: {abs(loss_bad.item() - loss_with_ignore.item()):.4f}")
print()
print("→ 如果不用 ignore_index,模型会被迫学习:")
print(" '在系统提示后面必须预测<|im_end|>'")
print(" '在用户问题后面必须预测<|im_end|>'")
print(" 这些都是无意义的噪声!")
print()
print("总结:")
print(" 1. labels 中 assistant 内容 = 真实 token ID → 算 loss → 模型学到生成答案")
print(" 2. labels 中其他一切 = -100 (ignore_index) → 不算 loss → 模型只看不学")
print(" 3. CrossEntropyLoss(ignore_index=-100) 自动跳过,loss=0, grad=0")
=== labels 构造 + ignore_index 验证 ===
Step 1: 构造 input_ids
input_ids: [151644, 8948, 198, 9942, 10603, 107659, 113738, 151645, 198, 151644, 872, 198, 16, 17, 16, 19, 20, 151645, 198, 151644, 78191, 198, 16, 17, 16, 19, 18, 151645, 198]
Step 2: 构造 labels(每个 token 逐一标注)
input_ids: [151644, 8948, 198, 9942, 10603, 107659, 113738, 151645, 198, 151644, 872, 198, 16, 17, 16, 19, 20, 151645, 198, 151644, 78191, 198, 16, 17, 16, 19, 18, 151645, 198]
labels: [-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 16, 17, 16, 19, 18, -100, -100]
逐 token 对比 (L=算loss, .=忽略):
Pos input_id token label 来源
---- -------- ------------------ -------- ------------------------------
[0 ] 151644 <|im_start|> -100 . 框架(system)
[1 ] 8948 system -100 . 框架(system)
[2 ] 198
-100 . 框架(system)
[3 ] 9942 你 -100 . [system内容]
[4 ] 10603 是 -100 . [system内容]
[5 ] 107659 数学 -100 . [system内容]
[6 ] 113738 助手 -100 . [system内容]
[7 ] 151645 <|im_end|> -100 . 框架标记
[8 ] 198
-100 . 框架标记
[9 ] 151644 <|im_start|> -100 . 框架(user)
[10] 872 user -100 . 框架(user)
[11] 198
-100 . 框架(user)
[12] 16 1 -100 . [user内容]
[13] 17 + -100 . [user内容]
[14] 16 1 -100 . [user内容]
[15] 19 = -100 . [user内容]
[16] 20 ? -100 . [user内容]
[17] 151645 <|im_end|> -100 . 框架标记
[18] 198
-100 . 框架标记
[19] 151644 <|im_start|> -100 . 框架(assistant)
[20] 78191 assistant -100 . 框架(assistant)
[21] 198
-100 . 框架(assistant)
[22] 16 1 16 L [assistant内容]
[23] 17 + 17 L [assistant内容]
[24] 16 1 16 L [assistant内容]
[25] 19 = 19 L [assistant内容]
[26] 18 2 18 L [assistant内容]
[27] 151645 <|im_end|> -100 . 框架标记
[28] 198
-100 . 框架标记
统计: 算 loss 的 token=5 个, 忽略的 token=24 个
有效训练信号占比: 5/29 = 17.2%
============================================================
Step 3: 验证 ignore_index 机制
============================================================
使用 ignore_index=-100 的 loss: 12.4869
每个位置的 loss (ignore_index 已自动把 -100 位置归零):
[ 0] loss=0.0000 ← IGNORE 位置, loss=0
[ 1] loss=0.0000 ← IGNORE 位置, loss=0
[ 2] loss=0.0000 ← IGNORE 位置, loss=0
[ 3] loss=0.0000 ← IGNORE 位置, loss=0
[ 4] loss=0.0000 ← IGNORE 位置, loss=0
[ 5] loss=0.0000 ← IGNORE 位置, loss=0
[ 6] loss=0.0000 ← IGNORE 位置, loss=0
[ 7] loss=0.0000 ← IGNORE 位置, loss=0
[ 8] loss=0.0000 ← IGNORE 位置, loss=0
[ 9] loss=0.0000 ← IGNORE 位置, loss=0
[10] loss=0.0000 ← IGNORE 位置, loss=0
[11] loss=0.0000 ← IGNORE 位置, loss=0
[12] loss=0.0000 ← IGNORE 位置, loss=0
[13] loss=0.0000 ← IGNORE 位置, loss=0
[14] loss=0.0000 ← IGNORE 位置, loss=0
[15] loss=0.0000 ← IGNORE 位置, loss=0
[16] loss=0.0000 ← IGNORE 位置, loss=0
[17] loss=0.0000 ← IGNORE 位置, loss=0
[18] loss=0.0000 ← IGNORE 位置, loss=0
[19] loss=0.0000 ← IGNORE 位置, loss=0
[20] loss=0.0000 ← IGNORE 位置, loss=0
[21] loss=0.0000 ← IGNORE 位置, loss=0
[22] loss=12.3892 ← 有效位置! 预测'1'
[23] loss=11.8538 ← 有效位置! 预测'+'
[24] loss=10.9521 ← 有效位置! 预测'1'
[25] loss=13.6627 ← 有效位置! 预测'='
[26] loss=13.5766 ← 有效位置! 预测'2'
[27] loss=0.0000 ← IGNORE 位置, loss=0
[28] loss=0.0000 ← IGNORE 位置, loss=0
手工平均(只算有效位置): 12.4869
PyTorch cross_entropy 结果: 12.4869
一致 ✅
============================================================
Step 4: 对比 — 如果不用 ignore_index
============================================================
把所有 -100 改成 0 后的 loss: 12.6909
正确的 loss (��忽略 -100): 12.4869
差异: 0.2040
→ 如果不用 ignore_index,模型会被迫学习:
'在系统提示后面必须预测<|im_end|>'
'在用户问题后面必须预测<|im_end|>'
这些都是无意义的噪声!
总结:
1. labels 中 assistant 内容 = 真实 token ID → 算 loss → 模型学到生成答案
2. labels 中其他一切 = -100 (ignore_index) → 不算 loss → 模型只看不学
3. CrossEntropyLoss(ignore_index=-100) 自动跳过,loss=0, grad=0
10.4 多轮对话:长对话是怎么拼接的?
真实训练数据经常是多轮对话。比如:
{"messages": [
{"role": "system", "content": "你是数学老师"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2"},
{"role": "user", "content": "那2+2呢?"},
{"role": "assistant", "content": "2+2=4"}
]}
拼接规则完全一样:把所有消息按顺序拼成一段连续的 token 序列。
<|im_start|>system\n你是数学老师<|im_end|>\n
<|im_start|>user\n1+1=?<|im_end|>\n
<|im_start|>assistant\n1+1=2<|im_end|>\n
<|im_start|>user\n那2+2呢?<|im_end|>\n
<|im_start|>assistant\n2+2=4<|im_end|>\n
labels 也不变:每一轮的 assistant 内容都参与 loss 计算,system/user/特殊标记都不算。
┌──────────────────────────────────────────────────────────────┐
│ 多轮对话的 labels 规则 │
├──────────────────────────────────────────────────────────────┤
│ │
│ 第1轮: user→"1+1=?" ← 模型看到,不学 │
│ assistant→"1+1=2" ← 模型看到,要学! ✓ │
│ │
│ 第2轮: user→"那2+2呢?" ← 模型看到,不学 │
│ assistant→"2+2=4" ← 模型看到,要学! ✓ │
│ │
│ 通过 attention,模型在第2轮能看到第1轮的完整历史 │
│ → 模型学会「基于对话历史回答」 │
│ │
└──────────────────────────────────────────────────────────────┘
为什么多轮数据很重要?
- 单轮「一问一答」→ 模型只能做一次回答
- 多轮「连续对话」→ 模型学会:追问、澄清、记住上文
- 实际训练通常混合:~60% 多轮 + ~40% 单轮
下面用真实 tokenizer 演示多轮对话的拼接和 labels 构造:
# ============================================================
# 多轮对话拼接证��明:5 条消息也是拼成一段
# ============================================================
print("=" * 70)
print("证明:多轮对话也是拼接成一段连续 token 序列")
print("=" * 70)
print()
# 词表
vocab = {
"<|im_start|>": 151644, "<|im_end|>": 151645,
"system": 8948, "user": 872, "assistant": 78191,
"你": 9942, "是": 10603, "数学": 107659, "老师": 113740,
"1": 16, "+": 17, "2": 18, "=": 19, "?": 20, "。": 21,
"3": 22, "4": 23, "那": 104322, "呢": 104535, "\n": 198,
}
id_to_word = {v: k for k, v in vocab.items()}
def encode(text):
tokens = []
i = 0
while i < len(text):
matched = None
for word in sorted(vocab.keys(), key=lambda x: -len(x)):
if text[i:].startswith(word):
matched = word
break
if matched:
tokens.append(vocab[matched])
i += len(matched)
else:
tokens.append(0)
i += 1
return tokens
IM_START = "<|im_start|>"
IM_END = "<|im_end|>"
IGNORE = -100
# 多轮对话数据(2 轮)
multi_turn = {
"messages": [
{"role": "system", "content": "你是数学老师"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2。"},
{"role": "user", "content": "那2+2呢?"},
{"role": "assistant", "content": "2+2=4。"},
]
}
print("多轮对话数据(5 条消息 = system + 2轮×2):")
for i, msg in enumerate(multi_turn["messages"]):
print(f" [{i}] {msg['role']:>10s}: {msg['content']}")
# ============================================================
# 逐步拼接 — 5 条消息
# ============================================================
print()
print("=" * 70)
print("逐步拼接 — 5 条消息全部拼成�一段")
print("=" * 70)
all_text = ""
all_ids = []
for step, msg in enumerate(multi_turn["messages"]):
role = msg["role"]
content = msg["content"]
segment = f"{IM_START}{role}\n{content}{IM_END}\n"
segment_ids = encode(segment)
before_len = len(all_ids)
all_text += segment
all_ids.extend(segment_ids)
print(f"\nStep {step+1}/5: 拼接 {role} → \"{content}\"")
print(f" 片段: {repr(segment)}")
print(f" 片段 token 数: {len(segment_ids)}")
print(f" 累积 token 数: {before_len} → {len(all_ids)}")
print(f" 累积文本: {repr(all_text)}")
# ============================================================
# 最终证明
# ============================================================
print(f"\n{'='*70}")
print("✅ 最终:5 条消息拼成了 1 段连续的 token 序列")
print(f"{'='*70}")
print(f" 总 token 数: {len(all_ids)}")
print(f" 完整 IDs: {all_ids}")
print()
# 逐 token 标注轮次
print("逐 token 标注(证明是连续序列,非分段数组):")
print(f"{'Pos':<4s} {'ID':>7s} {'token':<16s} {'轮次/角色':<25s} {'算loss?'}")
print(f"{'-'*4} {'-'*7} {'-'*16} {'-'*25} {'-'*8}")
pos = 0
for turn_idx, msg in enumerate(multi_turn["messages"]):
role = msg["role"]
content = msg["content"]
header_ids = encode(f"{IM_START}{role}\n")
for hid in header_ids:
word = id_to_word.get(hid, "???")
print(f"{pos:<4d} {hid:>7d} {word:<16s} {'第'+str(turn_idx+1)+'轮 框架('+role+')':<25s} 忽略")
pos += 1
content_ids = encode(content)
for cid in content_ids:
word = id_to_word.get(cid, "???")
if role == "assistant":
loss_note = "✓ 计算!"
else:
loss_note = "忽略"
print(f"{pos:<4d} {cid:>7d} {word:<16s} {'第'+str(turn_idx+1)+'轮 '+role+'内容':<25s} {loss_note}")
pos += 1
footer_ids = encode(f"{IM_END}\n")
for fid in footer_ids:
word = id_to_word.get(fid, "???")
print(f"{pos:<4d} {fid:>7d} {word:<16s} {'第'+str(turn_idx+1)+'轮 框架结尾':<25s} 忽略")
pos += 1
if turn_idx < len(multi_turn["messages"]) - 1:
print(f"{'':>4s} {'↓ 继续拼接,序列不中断 ↓':>50s}")
print()
print(f"结论:")
print(f" 5 条独立的消息 → 1 段 {pos} 个 token 的连续序列")
print(f" 模型一次性读取整段序列(通过 causal attention)")
print(f" 只有 assistant 部分的 token 参与 loss 计算")
print(f" 多轮 = 单轮的多次重复拼接,规则完全一样")
======================================================================
证明:多轮对话也是拼接成一段连续 token 序列
======================================================================
多轮对话数据(5 条消息 = system + 2轮×2):
[0] system: 你是数学老师
[1] user: 1+1=?
[2] assistant: 1+1=2。
[3] user: 那2+2呢?
[4] assistant: 2+2=4。
======================================================================
逐步拼接 — 5 条消息全部拼成一段
======================================================================
Step 1/5: 拼接 system → "你是数学老师"
片段: '<|im_start|>system\n你是数学老师<|im_end|>\n'
片段 token 数: 9
累积 token 数: 0 → 9
累积文本: '<|im_start|>system\n你是数学老师<|im_end|>\n'
Step 2/5: 拼接 user → "1+1=?"
片段: '<|im_start|>user\n1+1=?<|im_end|>\n'
片段 token 数: 10
累积 token 数: 9 → 19
累积文本: '<|im_start|>system\n你是数学老师<|im_end|>\n<|im_start|>user\n1+1=?<|im_end|>\n'
Step 3/5: 拼接 assistant → "1+1=2。"
片段: '<|im_start|>assistant\n1+1=2。<|im_end|>\n'
片段 token 数: 11
累积 token 数: 19 → 30
累积文本: '<|im_start|>system\n你是数学老师<|im_end|>\n<|im_start|>user\n1+1=?<|im_end|>\n<|im_start|>assistant\n1+1=2。<|im_end|>\n'
Step 4/5: 拼接 user → "那2+2呢?"
片段: '<|im_start|>user\n那2+2呢?<|im_end|>\n'
片段 token 数: 11
累积 token 数: 30 → 41
累积文本: '<|im_start|>system\n你是数学老师<|im_end|>\n<|im_start|>user\n1+1=?<|im_end|>\n<|im_start|>assistant\n1+1=2。<|im_end|>\n<|im_start|>user\n那2+2呢?<|im_end|>\n'
Step 5/5: 拼接 assistant → "2+2=4。"
片段: '<|im_start|>assistant\n2+2=4。<|im_end|>\n'
片段 token 数: 11
累积 token 数: 41 → 52
累积文本: '<|im_start|>system\n你是数学老师<|im_end|>\n<|im_start|>user\n1+1=?<|im_end|>\n<|im_start|>assistant\n1+1=2。<|im_end|>\n<|im_start|>user\n那2+2呢?<|im_end|>\n<|im_start|>assistant\n2+2=4。<|im_end|>\n'
======================================================================
✅ 最终:5 条消息拼成了 1 段连续的 token 序列
======================================================================
总 token 数: 52
完整 IDs: [151644, 8948, 198, 9942, 10603, 107659, 113740, 151645, 198, 151644, 872, 198, 16, 17, 16, 19, 20, 151645, 198, 151644, 78191, 198, 16, 17, 16, 19, 18, 21, 151645, 198, 151644, 872, 198, 104322, 18, 17, 18, 104535, 20, 151645, 198, 151644, 78191, 198, 18, 17, 18, 19, 23, 21, 151645, 198]
逐 token 标注(证明是连续序列,非分段数组):
Pos ID token 轮次/角色 算loss?
---- ------- ---------------- ------------------------- --------
0 151644 <|im_start|> 第1轮 框架(system) 忽略
1 8948 system 第1轮 框架(system) 忽略
2 198
第1轮 框架(system) 忽略
3 9942 你 第1轮 system内容 忽略
4 10603 是 第1轮 system内容 忽略
5 107659 数学 第1轮 system内容 忽略
6 113740 老师 第1轮 system内容 忽略
7 151645 <|im_end|> 第1轮 框架结尾 忽略
8 198
第1��轮 框架结尾 忽略
↓ 继续拼接,序列不中断 ↓
9 151644 <|im_start|> 第2轮 框架(user) 忽略
10 872 user 第2轮 框架(user) 忽略
11 198
第2轮 框架(user) 忽略
12 16 1 第2轮 user内容 忽略
13 17 + 第2轮 user内容 忽略
14 16 1 第2轮 user内容 忽略
15 19 = 第2轮 user内容 忽略
16 20 ? 第2轮 user内容 忽略
17 151645 <|im_end|> 第2轮 框架结尾 忽略
18 198
第2轮 框架结尾 忽略
↓ 继续拼接,序列不中断 ↓
19 151644 <|im_start|> 第3轮 框架(assistant) 忽略
20 78191 assistant 第3轮 框架(assistant) 忽略
21 198
第3轮 框架(assistant) 忽略
22 16 1 第3轮 assistant内容 ✓ 计算!
23 17 + 第3轮 assistant内容 ✓ 计算!
24 16 1 第3轮 assistant内容 ✓ 计算!
25 19 = 第3轮 assistant内容 ✓ 计算!
26 18 2 第3轮 assistant内容 ✓ 计算!
27 21 。 第3轮 assistant内容 ✓ 计算!
28 151645 <|im_end|> 第3轮 框架结尾 忽略
29 198
第3轮 框架结尾 忽略
↓ 继续拼接,序列不中断 ↓
30 151644 <|im_start|> 第4轮 框架(user) 忽略
31 872 user 第4轮 框架(user) 忽略
32 198
第4轮 框架(user) 忽略
33 104322 那 第4轮 user内容 忽略
34 18 2 第4轮 user内容 忽略
35 17 + 第4轮 user内容 忽略
36 18 2 第4轮 user内容 忽略
37 104535 呢 第4轮 user内容 忽略
38 20 ? 第4轮 user内容 忽略
39 151645 <|im_end|> 第4轮 框架结尾 忽略
40 198
第4轮 框架结尾 忽略
↓ 继续拼接,序列不中断 ↓
41 151644 <|im_start|> 第5轮 框架(assistant) 忽略
42 78191 assistant 第5轮 框架(assistant) 忽略
43 198
第5轮 框架(assistant) 忽略
44 18 2 第5轮 assistant内容 ✓ 计算!
45 17 + 第5轮 assistant内容 ✓ 计算!
46 18 2 第5轮 assistant内容 ✓ 计算!
47 19 = 第5轮 assistant内容 ✓ 计算!
48 23 4 第5轮 assistant内容 ✓ 计算!
49 21 。 第5轮 assistant内容 ✓ 计算!
50 151645 <|im_end|> 第5轮 框架结尾 忽略
51 198
第5轮 框架结尾 忽略
结论:
5 条独立的消息 → 1 段 52 个 token 的连续序列
模型一次性读取整段序列(通过 causal attention)
只有 assistant 部分的 token 参与 loss 计算
多轮 = 单轮的多次重复拼接,规则完全一样
10.5 完整的训练循环:把 Chat Template 和 Part 5 串起来
回顾 Part 5 前面讲的训练循环:input_ids = batch[:, :-1], labels = batch[:, 1:]。
那个是「原始文本」的简化训练。对于对话数据,完整流程是:
┌─────────────────────────────────────────────────────────────────┐
│ Chat Template 训练循环 (完整版) │
├─────────��────────────────────────────────────────────────────────┤
│ │
│ 1. JSONL 数据读取 │
│ {"messages": [{role, content}, ...]} │
│ │
│ 2. apply_chat_template(messages) │
│ → input_ids: [151644, 8948, ..., 151645, 198, ...] │
│ → labels: [-100, -100, ..., 16, 17, 18, ...] │
│ │
│ 3. 数据准备(和 Part 5 开头一样) │
│ input_ids = tensor[:, :-1] # 去掉最后一个 │
│ labels = labels[:, 1:] # 右移一位 │
│ │
│ 4. Forward + Loss │
│ logits = model(input_ids) │
│ loss = CrossEntropyLoss(logits, labels, ignore_index=-100) │
│ │
│ 5. Backward + Update │
│ loss.backward() │
│ clip_grad_norm_(...) │
│ optimizer.step() │
│ │
└───────────────────────────────────────────────��──────────────────┘
10.6 这和 Part 6(07-generation.ipynb)怎么衔接?
训练完成后,推理时用同一个 chat template:
# 推理时(07-generation.ipynb 讲的自回归生成)
messages = [
{"role": "system", "content": "你是数学助手"},
{"role": "user", "content": "3+3=?"}
]
# 同样的 apply_chat_template(只是 add_generation_prompt=True)
# 这会在末尾加上 <|im_start|>assistant\n — 提示模型「该你说话了」
prompt_ids = tokenizer.apply_chat_template(
messages, tokenize=True, add_generation_prompt=True
)
# 然后就是 Part 6 的自回归生成:
# model.generate(prompt_ids, temperature=0.7, top_p=0.9, ...)
核心闭环:
训练时 chat template 把对话拼成 token 序列 → 模型学到 assistant 回复的模式 → 推理时 chat template 把用户输入拼成 prompt → 模型自回归生成 assistant 回复 → 前端去掉 special token → 返回纯文本给用户
下面用一个完整的训练循环代码收尾:
# ============================================================
# 完整训练循环:Chat Template + MiniGPT
# ============================================================
import torch
import torch.nn as nn
import torch.nn.functional as F
print("=== 完整训练循环:对话数据 → token → 训练 ===\n")
# -------- 复用之前的词表和函数 --------
vocab = {
"<|im_start|>": 151644, "<|im_end|>": 151645,
"system": 8948, "user": 872, "assistant": 78191,
"你": 9942, "是": 10603, "数学": 107659, "老师": 113740,
"1": 16, "+": 17, "2": 18, "=": 19, "?": 20, "。": 21,
"3": 22, "4": 23, "那": 104322, "呢": 104535, "\n": 198,
"翻译": 112345, "官": 105678,
"Hello": 201, "你好": 202, "!": 203,
"天气": 301, "怎么": 302, "样": 303,
"今天": 304, "不": 305, "错": 306, "晴天": 307,
}
id_to_word = {v: k for k, v in vocab.items()}
VOCAB_SIZE = max(vocab.values()) + 10
IM_START = "<|im_start|>"
IM_END = "<|im_end|>"
IGNORE = -100
PAD_ID = 0
def encode(text):
tokens = []
i = 0
while i < len(text):
matched = None
for word in sorted(vocab.keys(), key=lambda x: -len(x)):
if text[i:].startswith(word):
matched = word
break
if matched:
tokens.append(vocab[matched])
i += len(matched)
else:
tokens.append(0)
i += 1
return tokens
# -------- 准备训练数据(3 条对话) --------
train_conversations = [
{
"messages": [
{"role": "system", "content": "你是数学老师"},
{"role": "user", "content": "1+1=?"},
{"role": "assistant", "content": "1+1=2。"},
]
},
{
"messages": [
{"role": "system", "content": "你是翻译官"},
{"role": "user", "content": "Hello!"},
{"role": "assistant", "content": "你好!"},
]
},
{
"messages": [
{"role": "user", "content": "天气怎么样?"},
{"role": "assistant", "content": "今天天气不错,晴天。"},
]
},
]
# -------- 构造 input_ids 和 labels --------
print("=== 构造训练数据 ===")
all_inputs = []
all_labels = []
for idx, conv in enumerate(train_conversations):
messages = conv["messages"]
# 拼接文本
text = ""
for msg in messages:
text += f"{IM_START}{msg['role']}\n{msg['content']}{IM_END}\n"
input_ids = encode(text)
labels = [IGNORE] * len(input_ids)
# 标注 assistant 内容
pos = 0
for msg in messages:
role = msg["role"]
content = msg["content"]
pos += len(encode(f"{IM_START}{role}\n"))
cids = encode(content)
if role == "assistant":
for j, cid in enumerate(cids):
labels[pos + j] = cid
pos += len(cids)
pos += len(encode(f"{IM_END}\n"))
all_inputs.append(input_ids)
all_labels.append(labels)
n_assistant = sum(1 for l in labels if l != IGNORE)
n_total = len(labels)
print(f"对话 {idx+1}: {n_total} tokens, {n_assistant} 算 loss ({n_assistant/n_total*100:.0f}%)")
# 如果没有 system prompt,标注
has_system = any(m["role"] == "system" for m in messages)
if not has_system:
print(f" (没有 system prompt)")
print()
# -------- Padding 到相同长度 --------
max_len = max(len(ids) for ids in all_inputs)
print(f"最大序列长度: {max_len}")
padded_inputs = []
padded_labels = []
for input_ids, labels in zip(all_inputs, all_labels):
pad_len = max_len - len(input_ids)
padded_inputs.append(input_ids + [PAD_ID] * pad_len)
padded_labels.append(labels + [IGNORE] * pad_len)
input_ids_batch = torch.tensor(padded_inputs)
labels_batch = torch.tensor(padded_labels)
print(f"input_ids_batch 形状: {input_ids_batch.shape}")
print(f"labels_batch 形状: {labels_batch.shape}")
print()
print("input_ids_batch:")
print(input_ids_batch)
print()
print("labels_batch (-100=忽略):")
print(labels_batch)
print()
# -------- 拆成 input/target --------
# 和 Part 5 开头一样的逻辑:input = 去掉最后一个, target = 去掉第一个
model_inputs = input_ids_batch[:, :-1] # [batch, seq-1]
model_targets = labels_batch[:, 1:] # [batch, seq-1]
print(f"模型输入形状: {model_inputs.shape}")
print(f"模型目标形状: {model_targets.shape}")
print()
# -------- 创建简单模型 --------
class TinyLLM(nn.Module):
def __init__(self, vocab_size, d_model=32):
super().__init__()
self.embed = nn.Embedding(vocab_size, d_model, padding_idx=0)
self.transformer = nn.TransformerEncoder(
nn.TransformerEncoderLayer(d_model, nhead=4, dim_feedforward=64, batch_first=True),
num_layers=2
)
self.lm_head = nn.Linear(d_model, vocab_size)
def forward(self, x):
mask = nn.Transformer.generate_square_subsequent_mask(x.shape[1], device=x.device)
x = self.embed(x)
x = self.transformer(x, mask=mask, is_causal=True)
return self.lm_head(x)
model = TinyLLM(VOCAB_SIZE, d_model=32)
optimizer = torch.optim.Adam(model.parameters(), lr=0.005)
print(f"模型参数量: {sum(p.numel() for p in model.parameters()):,}")
print()
# -------- 训练循环 --------
NUM_EPOCHS = 10
losses = []
print(f"=== 训练 {NUM_EPOCHS} 个 epoch ===")
model.train()
for epoch in range(NUM_EPOCHS):
logits = model(model_inputs) # [batch=3, seq-1, vocab_size]
loss = F.cross_entropy(
logits.reshape(-1, VOCAB_SIZE),
model_targets.reshape(-1),
ignore_index=IGNORE # ← 关键!忽略 -100 的位置
)
optimizer.zero_grad()
loss.backward()
nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
losses.append(loss.item())
if (epoch + 1) % 2 == 0:
print(f" Epoch {epoch+1:2d}/{NUM_EPOCHS} | Loss: {loss.item():.4f}")
print(f"\nLoss: {losses[0]:.4f} → {losses[-1]:.4f} (下降 = 模型在学习 assistant 回复的模式)")
print()
# -------- 推理演示:用训练好的模型生成 --------
print("=== 推理演示 ===")
# 构造 prompt: system + user
prompt_messages = [
{"role": "system", "content": "你是数学老师"},
{"role": "user", "content": "2+2=?"}
]
# 拼接 prompt(和训练时一样的 chat template,但是结尾不同)
prompt_text = ""
for msg in prompt_messages:
prompt_text += f"{IM_START}{msg['role']}\n{msg['content']}{IM_END}\n"
prompt_text += f"{IM_START}assistant\n" # ← add_generation_prompt
prompt_ids = torch.tensor([encode(prompt_text)])
print(f"Prompt: {prompt_text.strip()}")
print(f"Prompt IDs: {prompt_ids[0].tolist()}")
# 自回归生成
model.eval()
generated = prompt_ids.clone()
with torch.no_grad():
for _ in range(10): # 最多生成 10 个 token
logits = model(generated)
next_logits = logits[0, -1, :] # 最后一个位置的预测
probs = F.softmax(next_logits / 0.7, dim=-1)
# 禁止 PAD 和 special token
probs[0] = 0
probs[151644] = 0
probs[151645] = 0
next_token = torch.multinomial(probs, 1)
generated = torch.cat([generated, next_token.unsqueeze(0)], dim=1)
if next_token.item() == 151645: # <|im_end|>
break
# 解码
output_ids = generated[0].tolist()
output_text = ""
for tid in output_ids[len(prompt_ids[0]):]: # 只取新生成的
word = id_to_word.get(tid, f"[{tid}]")
output_text += word
if tid == 151645:
break
print(f"生成文本: {output_text}")
print()
# -------- 总结 --------
print("=" * 60)
print("完整链路回顾:")
print("=" * 60)
print("""
1. JSONL 数据 → messages 列表
2. Chat Template → 拼接成带特殊 token 的文本
3. Tokenize → input_ids (模型看到的所有 token)
4. 构造 labels → 只有 assistant 内容保留真实 ID,其他全 -100
5. 训练 → CrossEntropyLoss(ignore_index=-100) 只优化 assistant 部分
6. 推理 → 同样的 chat template 拼接 prompt, add_generation_prompt=True
7. 生成 → 自回归(07-generation.ipynb 的内容)
这就是从「对话数据」到「训练好的聊天模型」的完整流程。
""")
=== 完整训练循环:对话数据 → token → 训练 ===
=== 构造训练数据 ===
对话 1: 30 tokens, 6 算 loss (20%)
对话 2: 23 tokens, 2 算 loss (9%)
对话 3: 21 tokens, 7 算 loss (33%)
(没有 system prompt)
最大序列长度: 30
input_ids_batch 形状: torch.Size([3, 30])
labels_batch 形状: torch.Size([3, 30])
input_ids_batch:
tensor([[151644, 8948, 198, 9942, 10603, 107659, 113740, 151645, 198,
151644, 872, 198, 16, 17, 16, 19, 20, 151645,
198, 151644, 78191, 198, 16, 17, 16, 19, 18,
21, 151645, 198],
[151644, 8948, 198, 9942, 10603, 112345, 105678, 151645, 198,
151644, 872, 198, 201, 203, 151645, 198, 151644, 78191,
198, 202, 203, 151645, 198, 0, 0, 0, 0,
0, 0, 0],
[151644, 872, 198, 301, 302, 303, 20, 151645, 198,
151644, 78191, 198, 304, 301, 305, 306, 0, 307,
21, 151645, 198, 0, 0, 0, 0, 0, 0,
0, 0, 0]])
labels_batch (-100=忽略):
tensor([[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, 16, 17,
16, 19, 18, 21, -100, -100],
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100, -100, 202, 203, -100, -100, -100,
-100, -100, -100, -100, -100, -100],
[-100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100, -100,
304, 301, 305, 306, 0, 307, 21, -100, -100, -100, -100, -100,
-100, -100, -100, -100, -100, -100]])
模型输入形状: torch.Size([3, 29])
模型目标形状: torch.Size([3, 29])
模型参数量: 9,874,663
=== 训练 10 个 epoch ===
Epoch 2/10 | Loss: 11.4453
Epoch 4/10 | Loss: 10.4529
Epoch 6/10 | Loss: 9.7923
Epoch 8/10 | Loss: 9.0957
Epoch 10/10 | Loss: 8.3517
Loss: 11.9625 → 8.3517 (下降 = 模型在学习 assistant 回复的模式)
=== 推理演示 ===
Prompt: <|im_start|>system
你是数学老师<|im_end|>
<|im_start|>user
2+2=?<|im_end|>
<|im_start|>assistant
Prompt IDs: [151644, 8948, 198, 9942, 10603, 107659, 113740, 151645, 198, 151644, 872, 198, 18, 17, 18, 19, 20, 151645, 198, 151644, 78191, 198]
生成文本: [124121][95100][6361][74255][13358][41408][82947][38946][55889][23758]
============================================================
完整链路回顾:
============================================================
1. JSONL 数据 → messages 列表
2. Chat Template → 拼接成带特殊 token 的文本
3. Tokenize → input_ids (模型看到的所有 token)
4. 构造 labels → 只有 assistant 内容保留真实 ID,其他全 -100
5. 训练 → CrossEntropyLoss(ignore_index=-100) 只优化 assistant 部分
6. 推理 → 同样的 chat template 拼接 prompt, add_generation_prompt=True
7. 生成 → 自回归(07-generation.ipynb 的内容)
这就是从「对话数据」到「训练好的聊天模型」的完整流程。
11. 训练稳定性
前面我们讲了 loss 怎么算、梯度怎么传。但在实际训练中,还有三个几乎每次都要用的工程技巧。它们解决的并不是「模型应该学什么」的问题,而是「训练过程本身会不会崩溃」的问题。
训练不稳定的场景主要有三种:
- 某一步梯度突然巨大:比如一个 batch 里恰好有极端数据,或者深层网络的梯度在反向传播中不断放大。不做干预的话,一次参数更新就能把模型从正常状态甩到一个完全随机的状态,loss 直接变成 NaN。
- 显存不够但又需要大批量:batch size 太小会让梯度方向不稳定,每一步都朝着只代表当前几个样本的方向走;但增大 batch size 需要的显存指数级增长�,单卡装不下。
- 训练刚开始时方向还没找准:初始参数是随机的,梯度方向也是随机的。如果第一步就以完整学习率更新,相当于蒙着眼全力冲刺,很容易冲到 loss 曲面上一个很陡的坑里,再也爬不出来。
三个技巧分别对应这三个问题:
| 技巧 | 解决的问题 | 核心机制 |
|---|---|---|
| Gradient Clipping | 梯度爆炸,单步更新过大 | 梯度总范数超过阈值时等比缩放,方向不变,步长受限 |
| Gradient Accumulation | 显存不够,batch 太小梯度不准 | 多个小 batch 分别算梯度累加,最后一次性更新,等效大 batch |
| Warmup | 初始方向随机,大 LR 容易跑偏 | 前 N 步学习率从 0 线性增长,先用小步试探方向,再加速 |
三个技巧解决的问题各不相同,但目标一致:让训练过程的每一步都保持可控,不因为意外的大梯度、小 batch、或错误的初始方向而偏离正轨。
11.1 Gradient Clipping:给梯度装一个「限速器」
训练过程中,某些数据(比如一篇文章里突然出现一段乱码)可能导致某个 batch 的梯度变得非常大。
如果直接用这个巨大的梯度更新参数,模型可能一步就「跳飞了」——loss 突然暴涨,再也回不来。
Gradient Clipping 的做法:每次算完梯度后,检查梯度的总大小(norm)。如果超过了某个阈值(比如 1.0),就等比缩小,让总大小刚好等于阈值。
原始梯度: [3.0, -5.0, 2.0, ...] → norm = 6.2
阈值 clip = 1.0
缩放因子 = 1.0 / 6.2 = 0.161
裁剪后: [0.48, -0.81, 0.32, ...] → norm = 1.0 ✅
方向不变,只是步伐变小了。就像汽车限速器——不改变方向,只限制最高速度。
# === Gradient Clipping 手算 + 代码演示 ===
import torch
import torch.nn as nn
print("=== Gradient Clipping 手算 ===")
print()
# 模拟一个梯度向量
grad = torch.tensor([3.0, -5.0, 2.0, -1.0, 4.0])
max_norm = 1.0
# Step 1: 算梯度的 L2 范数
total_norm = torch.norm(grad).item()
print(f"原始梯度: {grad.tolist()}")
print(f"梯度范数: {total_norm:.4f}")
print()
# Step 2: 如果范数超过阈值,等比缩放
if total_norm > max_norm:
scale = max_norm / total_norm
clipped = grad * scale
print(f"范数 {total_norm:.4f} > 阈值 {max_norm}")
print(f"缩放因子: {max_norm}/{total_norm:.4f} = {scale:.4f}")
print(f"裁剪后: {[f'{v:.4f}' for v in clipped.tolist()]}")
print(f"裁剪后范数: {torch.norm(clipped).item():.4f} (= {max_norm})")
else:
clipped = grad
print(f"范数 {total_norm:.4f} <= 阈值 {max_norm},不需要裁剪")
print()
# PyTorch 内置实现
grad_copy = grad.clone()
torch.nn.utils.clip_grad_norm_(grad_copy, max_norm)
print(f"PyTorch clip_grad_norm_ 结果: {[f'{v:.4f}' for v in grad_copy.tolist()]}")
print(f"和我们手算的结果一样")
print()
print("实际使用(在训练循环中):")
print(" optimizer.zero_grad()")
print(" loss.backward()")
print(" torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)")
print(" optimizer.step()")
print()
print("几乎所有 LLM 训练都用 clip=1.0,这是一个非常稳定的默认值")
11.2 Gradient Accumulation:显存不够就分几步算
大模型训练的瓶颈往往是显存。一个 7B 模型,batch_size=4 可能就占满了 80GB 的 A100。
但缩放定律告诉我们:大 batch 训练效果更好。batch_size=4 不够,想要 32 怎么办?
Gradient Accumulation 的思路:把一个大 batch 拆成几个小 batch,分别算梯度,累积起来,最后一次性更新参数。
目标: batch_size = 32(但显存只够 4)
Step 1: 小 batch 1 (4 条数据) → 算梯度 → 累积
Step 2: 小 batch 2 (4 条数据) → 算梯度 → 累积
...
Step 8: 小 batch 8 (4 条数据) → 算梯度 → 累积
→ 8 步累积后,梯度 = 8 个小 batch 的梯度之和
→ 除以 8 取平均 → 更新参数
效果等价于一次用了 batch_size=32!
# === Gradient Accumulation 手算 ===
import torch
print("=== Gradient Accumulation 手算 ===")
print()
# 模拟 4 个小 batch 各自算出的梯度
grads = [
torch.tensor([0.5, -0.3, 0.8]),
torch.tensor([0.2, -0.1, 0.6]),
torch.tensor([0.7, -0.4, 0.3]),
torch.tensor([0.3, -0.2, 0.5]),
]
accumulation_steps = len(grads)
print(f"累积步数: {accumulation_steps}")
print(f"每个小 batch 的梯度:")
for i, g in enumerate(grads):
print(f" Step {i+1}: {g.tolist()}")
print()
# 累积
accumulated = torch.zeros_like(grads[0])
for g in grads:
accumulated += g
# 取平均
averaged = accumulated / accumulation_steps
print(f"累积总和: {accumulated.tolist()}")
print(f"取平均: {averaged.tolist()}")
print()
# 对比:一次性用全部数据算的梯度
# 假设 loss 对每个样本独立,那么大 batch 梯度 = 小 batch 梯度的平均
big_batch_grad = torch.stack(grads).mean(dim=0)
print(f"直接用大 batch 算: {big_batch_grad.tolist()}")
print(f"累积后取平均: {averaged.tolist()}")
print(f"→ 两者相同 ✅")
print()
print("训练循环中的写法:")
print(" for i, batch in enumerate(dataloader):")
print(" loss = model(batch) / accumulation_steps # 除以步数")
print(" loss.backward() # 梯度自动累积")
print(" if (i + 1) % accumulation_steps == 0:")
print(" optimizer.step() # 更新参数")
print(" optimizer.zero_grad() # 清空梯度")
11.3 Warmup:训练刚开始时先「慢跑热身」
模型刚初始化时,参数是随机的。如果一开始就用很大的学习率(比如 0.01),梯度方向混乱,参数会被「拉得到处乱跑」,loss 可能爆炸。
Warmup 的做法:前 N 步(通常是总步数的 5%)学习率从 0 线性增长到目标值。让模型先用小步伐「试探」一下,找到大致正确的方向,再加速。
LR
│ ╱‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾‾ ← 正常训练
│ ╱
│ ╱
│ ╱
│╱ ← Warmup 区间(前 5% 步数)
└──────────────────────────────────→ Step
Warmup 对应的生活直觉:冬天启动汽车,先怠速预热 30 秒再上路——直接一脚油门会伤发动机。
# === Warmup 手算 + 可视化 ===
import matplotlib.pyplot as plt
import math
print("=== Warmup 手算 ===")
print()
total_steps = 1000
warmup_steps = 50 # 前 50 步 warmup
max_lr = 0.01
def warmup_lr(step, warmup_steps, max_lr, total_steps):
"""线性 warmup + 余弦衰减"""
if step < warmup_steps:
return max_lr * step / warmup_steps
else:
progress = (step - warmup_steps) / (total_steps - warmup_steps)
return max_lr * 0.5 * (1 + math.cos(math.pi * progress))
# 关键位置的 LR
check_points = [0, 10, 25, 50, 100, 500, 900, 999]
print(f"总步数: {total_steps}, Warmup 步数: {warmup_steps}, 最大 LR: {max_lr}")
print()
print(f"{'步数':>6s} {'LR':>12s} {'阶段'}")
print('-' * 40)
for step in check_points:
lr = warmup_lr(step, warmup_steps, max_lr, total_steps)
phase = 'Warmup' if step < warmup_steps else '训练中'
print(f"{step:>6d} {lr:>12.6f} {phase}")
print()
print("关键观察:")
print(f" Step 0: LR = 0(不动,等预热结束)")
print(f" Step 10: LR = {warmup_lr(10, warmup_steps, max_lr, total_steps):.6f}(慢慢变大)")
print(f" Step 50: LR = {warmup_lr(50, warmup_steps, max_lr, total_steps):.6f}(达到最大,热身结束)")
print(f" Step 500: LR = {warmup_lr(500, warmup_steps, max_lr, total_steps):.6f}(余弦衰减中)")
# 可视化
steps = list(range(total_steps))
lrs = [warmup_lr(s, warmup_steps, max_lr, total_steps) for s in steps]
plt.figure(figsize=(10, 3))
plt.plot(steps, lrs, linewidth=1.5)
plt.axvspan(0, warmup_steps, alpha=0.2, color='orange', label='Warmup')
plt.axvspan(warmup_steps, total_steps, alpha=0.05, color='blue', label='Cosine Decay')
plt.xlabel('Step')
plt.ylabel('Learning Rate')
plt.title('Warmup + Cosine Decay (LLM 训练标配)')
plt.legend()
plt.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("橙色区域 = Warmup(线性增长),蓝色区域 = 正常训练(余弦衰减)")
print("Part 12 的 WSD 调度器会用「恒定」替代余弦——更灵活")
附录:MUON 优化器 — 用矩阵正交化替代逐元素学习率
AdamW 是当前最常用的优化器,但它有一个隐含的假设:每个参数是独立的。对于 Transformer 的 2D 权重矩阵(Attention 的 Q、K、V 投影,FFN 的上/下投影),这个假设并不成立。
一个权重矩阵 的结构信息——它的奇异值分布、条件数——对梯度更新的效果有很大影响。AdamW 对矩阵中的每个元素独立调整学习率,这个操作会改变矩阵的谱性质(singular value spectrum),削弱矩阵本身的结构信息。
公开资料显示,DeepSeek V4 这类新模型开始采用 MUON(MomentUm Orthogonalized by Newton-Schulz)这条路线。它换了一个思路:对 hidden layer 里的 2D 权重矩阵,不逐元素调整学习率,而是用 Newton-Schulz 迭代把梯度矩阵正交化,然后统一用 momentum 更新。
核心直觉:把梯度矩阵 G 想象成一��组「更新方向」。这些方向之间可能存在很强的相关性——某些方向被反复强化,另一些方向被忽略。Newton-Schulz 正交化就是把这组方向重新整理,让它们彼此正交,每个更新方向独立贡献,不会互相干扰。
Newton-Schulz 迭代的目标是计算 ,也就是把梯度矩阵变成半正交矩阵(列向量彼此正交且模长为 1)。直接算矩阵平方根的逆计算量很大,所以用迭代近似:
X = G / ||G||_F # 先归一化
for _ in range(5): # 5 步迭代即可收敛
A = X @ X.T
X = 1.5 * X - 0.5 * A @ X
# X 现在近似正交化后的梯度
这个迭代只包含矩阵乘法,在 GPU 上非常快——额外开销仅 0.5%~0.7% 的 FLOP。
和 AdamW 的对比:
| AdamW | MUON | |
|---|---|---|
| 处理方式 | 逐元素自适应学习率 | 矩阵级正交化 + momentum |
| 优化器状态 | 2× 参数量(m, v) | 1× 参数量(只有 momentum) |
| 适用参数 | 所有参数 | 通常用于 hidden 2D 权重矩阵 |
| 1D 参数 | 用 AdamW | 仍用 AdamW(bias、Norm 等) |
实际使用时通常是混合策略:hidden layer 的 2D 权重矩阵用 MUON,Embedding、lm_head、Norm 和 bias 等参数仍用 AdamW。这和训练代码里对不同参数组设置不同 optimizer 的做法类似。
参考资料:PyTorch/DeepSpeed 的 MUON 介绍、Moonlight/MUON 论文。
下面用一个极简的例子演示 Newton-Schulz 正交化的效果。
# === MUON 的 Newton-Schulz 正交化极简演示 ===
import torch
print("=== Newton-Schulz 正交化:把梯度矩阵变成正交矩阵 ===")
print()
torch.manual_seed(42)
# 模拟一个 2D 权重矩阵的梯度(比如 W_q: d_model=64, d_model=64)
m, n = 64, 64
G = torch.randn(m, n) * 2.0 # 模拟梯度,各列之间有相关性
# 人为制造列相关性:让后半列是前半列的线性组合
G[:, n//2:] = G[:, :n//2] @ torch.randn(n//2, n//2) * 0.3 + G[:, n//2:]
print(f"原始梯度矩阵 G: {m}x{n}")
print(f" Frobenius 范数: {torch.norm(G, 'fro'):.2f}")
# 检查列之间的相关性(用 Gram 矩阵的非对角线元素衡量)
gram = G.T @ G
off_diag = gram - torch.diag(torch.diag(gram))
print(f" 列间相关性(Gram 非对角线范数): {torch.norm(off_diag, 'fro'):.2f}")
print()
# Newton-Schulz 迭代
X = G / torch.norm(G, 'fro') # Step 0: 归一化
print("Newton-Schulz 迭代过程:")
for step in range(5):
A = X @ X.T
X_new = 1.5 * X - 0.5 * A @ X
# 检查是否逼近正交
gram_X = X_new.T @ X_new
off_diag_X = gram_X - torch.diag(torch.diag(gram_X))
error = torch.norm(off_diag_X, 'fro').item()
print(f" Step {step+1}: 非对角线范数 = {error:.6f}")
X = X_new
print()
print("正交化后的梯度矩阵 X:")
# 验证正交性
gram_final = X.T @ X
off_diag_final = torch.norm(gram_final - torch.diag(torch.diag(gram_final)), 'fro')
print(f" 列间相关性(Gram 非对角线范数): {off_diag_final:.6f}")
# 验证每列模长接近 1
col_norms = torch.norm(X, dim=0)
print(f" 每列模长范围: [{col_norms.min().item():.4f}, {col_norms.max().item():.4f}]")
print()
print("关键观察:")
print(" - 原始梯度各列之间有显著相关性(非对角线范数大)")
print(" - Newton-Schulz 迭代 5 步后,列之间几乎正交(非对角线->0)")
print(" - 每列模长接近 1,即 X 是半正交矩阵")
print(" - MUON 用这个正交化后的 X 代替原始梯度 G 来做 momentum 更新")
print(" - 直观理解:消除梯度方向间的相关性,让每个方向独立贡献")
12. Multi-Token Prediction — 一次预测多个未来 Token(DeepSeek-V3)
标准训练中,每个位置只预测紧接着的下一个 token。位置 t 的 hidden state 经过 LM Head,输出对 token_{t+1} 的预测,和 targets 的 t+1 位置算 cross-entropy。所有位置都这样做,loss 取平均——这就是我们一直用的训练方式。
Multi-Token Prediction(MTP)把这个规则扩展了一步:位置 t 的 hidden state 不只要预测 token_{t+1},还要预测 token_{t+2}、token_{t+3}……一直到 token_{t+N}。
标准: hidden_t → Head → P(token_{t+1})
MTP (N=3): hidden_t → Head_1 → P(token_{t+1})
→ Head_2 → P(token_{t+2})
→ Head_3 → P(token_{t+3})
实现上,就是在最后一个 Transformer 层之后接 N 个并行的输出头,每个头是一个独立的 Linear 层(实际模型中每个头是一个小的 Transformer block)。训练时,Head_1 对比 target[:,1:](标准 next-token),Head_2 对比 target[:,2:](下下个 token),依此类推。每个头的 loss 单独算 cross-entropy,总 loss 取各头 loss 的平均值。
这样做的直接效果是训练信号更密集。标准训练中,token_{t+k} 只�被位置 t+k-1 的 hidden state 监督一次。MTP 中,它还被 t+k-2、t+k-3……的 hidden state 从更远的地方预测。每个 token 获得了多次、来自不同距离的监督信号。
普通自回归生成时,可以只保留 Head_1(标准的 next-token prediction),把其余辅助头丢弃;这时 MTP 的收益主要来自训练阶段更密集的监督。但 DeepSeek-V3 论文和开源实现也说明,MTP 模块可以作为 speculative decoding 的 draft module 使用:辅助头先猜多个未来 token,再交给主模型验证,从而在合适的推理框架里加速生成。所以更准确的说法是:MTP 可在普通生成中丢弃,也可在投机解码中复用。参考:DeepSeek-V3 GitHub、DeepSeek-V3 技术报告。
import torch.nn as nn
import torch.nn.functional as F
class MultiHeadLM(nn.Module):
"""
多 token 预测的输出头
在主模型之后接 N 个输出头,分别预测未来 1~N 个 token。
实际模型(DeepSeek-V3)中每个头是一个小 Transformer block,
这里用单层 Linear 演示原理。
参数:
d_model: 隐藏维度
vocab_size: 词表大小
num_heads: 预测头数量(含主头)
"""
def __init__(self, d_model, vocab_size, num_heads=4):
super().__init__()
self.num_heads = num_heads
self.heads = nn.ModuleList([
nn.Linear(d_model, vocab_size, bias=False)
for _ in range(num_heads)
])
def forward(self, hidden_states):
"""
hidden_states: [batch, seq_len, d_model]
返回: list of logits
head[i] 预测的是 token_{pos + i + 1}
"""
return [head(hidden_states) for head in self.heads]
def compute_mtp_loss(logits_list, target_ids, ignore_index=-100):
"""
计算 MTP 的总 loss
head_i 预测未来第 i+1 个 token,需要对齐 targets
- head_0 对比 target[:, 1:] (下一个 token)
- head_1 对比 target[:, 2:] (下下个 token)
- head_2 对比 target[:, 3:] (下下下个 token)
"""
total_loss = 0.0
for i, logits in enumerate(logits_list):
shift = i + 1
# 去掉最后 shift 个位置(没有对应的 target)
logits_trimmed = logits[:, :-shift, :]
targets = target_ids[:, shift:]
logits_flat = logits_trimmed.reshape(-1, logits.shape[-1])
targets_flat = targets.reshape(-1)
total_loss += F.cross_entropy(logits_flat, targets_flat,
ignore_index=ignore_index)
return total_loss / len(logits_list)
print("Multi-Token Prediction 组件定义完成!")
print("关键:N 个独立输出头,每个预测不同距离的未来 token,推理时只保留主头")
# 演示 MTP 的 loss 计算
import torch
import torch.nn.functional as F
torch.manual_seed(42)
V = 20
B, S, D = 2, 8, 32
# 模拟主模型输出的 hidden states 和正确的 target ids
hidden = torch.randn(B, S, D)
targets = torch.randint(0, V, (B, S))
mtp = MultiHeadLM(D, V, num_heads=4)
logits_list = mtp(hidden)
print("=== Multi-Token Prediction Loss 演示 ===")
print(f"输入 shape: batch={B}, seq_len={S}, d_model={D}")
print(f"预测头数量: {len(logits_list)}")
print()
# 对比:标准单头训练 vs MTP
print("标准训练(单头):")
single_loss = F.cross_entropy(
logits_list[0][:, :-1, :].reshape(-1, V),
targets[:, 1:].reshape(-1)
)
print(f" 只用 Head 0 预测 t+1,loss = {single_loss.item():.4f}")
print(f" 每个 token 被监督 1 次")
print()
print("MTP 训练(4 头):")
for i, logits in enumerate(logits_list):
shift = i + 1
effective = S - shift
head_loss = F.cross_entropy(
logits[:, :-shift, :].reshape(-1, V),
targets[:, shift:].reshape(-1)
)
print(f" Head {i} (预测 t+{shift}): 有效位置={effective}, loss={head_loss.item():.4f}")
total = compute_mtp_loss(logits_list, targets)
print(f" 总 MTP loss (平均): {total.item():.4f}")
print()
print("关键观察:")
print("1. Head 0 就是标准的 next-token prediction——和单头训练完全相同")
print("2. Head 1~3 预测更远的 token,有效位置逐头减少(序列尾部没有标签)")
print("3. 同一段 hidden state 产生 4 份监督信号 → 训练信息密度提升")
print("4. 推理时只保留 Head 0,Head 1~3 全部丢弃,推理速度不受影响")
小结
确认以下理解无误:
- ✅ 训练输入 = 完整句子去掉最后一个;标签 = 完整句子去掉第一个(右移一位)
- ✅ 所有 token 位置同时做预测,每个位置单独算 cross-entropy loss
- ✅ 总 loss = 所有有效位置 loss 的平均值
- ✅ 是 token 级别训练,但所有 token 并行计算(不是句子级别,也不是串行 token)
- ✅ 训练用 teacher forcing(给正确答案),推理只能串行生成
- ✅ PAD 位置用
ignore_index排除,不参与 loss
这些知识不是只适用于我们的 mini GPT,而是适用于所有自回归语言模型(GPT-2/3/4、LLaMA、Qwen...)。
以上是标准训练框架。在实际训练中,还可以用 Multi-Token Prediction(MTP) 让每个位置同时预测未来 N 个 token,提高训练信号密度(见第 12 节)。
→ 最后一个 Part:模型训好了,怎么让它「说话」?
作业> 可以让 AI 帮忙解释思路,但不建议直接让 AI "做完这道题"。
作业 1:训练数据的 input 与 target 构造自回归语言模型的训练数据是从同一条句子构造出 input 和 target:input 是去掉最后一个 token 的句子,target 是去掉第一个 token 的句子(即整体右移一位)。给定句子(token id 序列):[0, 5, 3, 8, 2],其中 0 是 BOS,2 是 EOS。写出 input 和 target 各自的完整序列。小提示:input = sentence[:-1],target = sentence[1:]。
# 作业 1:训练数据的 input 与 target 构造sentence = [0, 5, 3, 8, 2] # [BOS, 我, 爱, NLP, EOS]# TODO: 构造 input(去掉最后一个 token)input_ids = None # 在这里构造# TODO: 构造 target(去掉第一个 token)target_ids = None # 在这里构造assert input_ids is not None, "请先构造 input_ids"assert target_ids is not None, "请先构造 target_ids"assert input_ids == [0, 5, 3, 8], f"input 应为 [0, 5, 3, 8],你得到 {input_ids}"assert target_ids == [5, 3, 8, 2], f"target 应为 [5, 3, 8, 2],你得到 {target_ids}"print("✅ 作业 1 通过:")print(f" 原句: {sentence}")print(f" input: {input_ids} → 模型看到的")print(f" target: {target_ids} → 模型需要预测的")print(" 每个位置的预测目标就是下一个 token。")
作业 2:Cross-Entropy Loss 手算给定一个 3 分类问题,模型对某个位置输出的 logits 为 [2.0, 1.0, 0.1],正确类别是 0。手动计算:1. 对 logits 做 softmax,得到概率分布2. 用 计算 loss小提示:softmax 公式 ,然后 loss 。
# 作业 2:Cross-Entropy Loss 手算import mathlogits = [2.0, 1.0, 0.1]correct_class = 0# TODO: 计算 softmax# p_i = exp(logits[i]) / sum(exp(logits))exp_vals = None # 先算所有 expprobs = None # 再算概率# TODO: 计算 loss = -log(probs[correct_class])loss = None # 在这里计算assert exp_vals is not None, "请先计算 exp 值"assert probs is not None, "请先计算概率"assert loss is not None, "请先计算 loss"# 验证概率之和为 1assert abs(sum(probs) - 1.0) < 0.001, f"概率之和应为 1.0,实际为 {sum(probs):.4f}"# 验证 lossexpected_loss = -math.log(probs[0])assert abs(loss - expected_loss) < 0.001, f"loss 应为 {expected_loss:.4f}"# 和 PyTorch 对比验证import torchimport torch.nn.functional as Ftorch_loss = F.cross_entropy(torch.tensor([logits]), torch.tensor([correct_class]))assert abs(loss - torch_loss.item()) < 0.01, f"与 PyTorch 结果不一致: {torch_loss.item():.4f}"print(f"✅ 作业 2 通过:")print(f" Softmax 概率: [{probs[0]:.4f}, {probs[1]:.4f}, {probs[2]:.4f}]")print(f" Loss = -log({probs[0]:.4f}) = {loss:.4f}")print(f" PyTorch 验证: {torch_loss.item():.4f}")print(" 正确类别的概率越高,loss 越小。")
作业 3:Padding 的 loss mask训练时一个 batch 中的句子长度不同,短的句子需要用 PAD token 填充。PAD 位置的 loss 应该被忽略。给定一个 batch 的 target:[[5, 3, 8, 2], [7, 4, -100, -100]](-100 表示 PAD,PyTorch 的 CrossEntropyLoss 会自动忽略 -100)。假设模型对 8 个位置(2 个样本 × 4 个位置)的预测 loss 分别是:[0.5, 0.3, 0.8, 0.2, 0.6, 0.4, 1.0, 0.9]。计算有效的平均 loss(排除 PAD 位置)。小提示:只有 6 个有效位置(第 1 句 4 个 + 第 2 句 2 个),第 2 句的最后两个位置是 PAD。
# 作业 3:Padding 的 loss mask# 8 个位置的 loss(2 个样本 × 4 个位置,按行展开)all_losses = [0.5, 0.3, 0.8, 0.2, 0.6, 0.4, 1.0, 0.9]# PAD 标记(对应第 2 个样本的最后两个位置)is_pad = [False, False, False, False, False, False, True, True]# TODO: 只保留非 PAD 位置的 loss,求平均valid_loss = None # 在这里计算assert valid_loss is not None, "请先计算有效 loss"valid_losses = [l for l, pad in zip(all_losses, is_pad) if not pad]expected = sum(valid_losses) / len(valid_losses)assert abs(valid_loss - expected) < 0.001, f"有效 loss 应为 {expected:.4f},你得到 {valid_loss:.4f}"print(f"✅ 作业 3 通过:")print(f" 所有位置 loss: {all_losses}")print(f" 有效位置 loss: {valid_losses}")print(f" 有效平均 loss: {valid_loss:.4f}")print(" PAD 位置不参与 loss 计算,避免模型被无意义的填充 token 干扰。")