LLM 评测
模型训完了,上线了——但它到底好不好?比上一版强多少?「感觉变好了」是工程决策最差的依据。
这一节理解论文和工业界真正在用的评测体系:评测指标怎么定义、开源评测框架怎么用、LLM-as-Judge 怎么让 强模型当裁判打分,以及如何看懂结果并写出有说服力的对比报告。
评测的本质是把「模型好不好」这个主观问题转化为可量化、可复现的客观分数。
核心三要素是标准化考题(benchmark)、自动化批改(metric)和可复现的流程(evaluation pipeline)。LLM-as-Judge 是近年兴起的做法:用 GPT-4 这类强模型来评判其他模型的回答质量。在 MT-Bench / Chatbot Arena 这类设置中,强模型 judge 与人类偏好有较高一致性;但一致性依赖任务、judge prompt、模型版本和答案格式。参考:MT-Bench / Chatbot Arena。
但 LLM-as-Judge 也有自己的陷阱——位置偏见、长度偏见和格式偏见都可能导致评分失真。
Perplexity 衡量模型在给定文本上预测下一个 token 的平均不确定性。它适合语言建模和预训练监控,但不能直接代表聊天质量、推理能力或安全性。
import os, json, sys, subprocess
from pathlib import Path
print(f"Python: {sys.version.split()[0]}")
print(f"工作目录: {os.getcwd()}")
# 检查关键依赖
deps = {
"openai": "OpenAI SDK",
"datasets": "HuggingFace datasets",
}
for pkg, desc in deps.items():
try:
__import__(pkg)
print(f" ✅ {pkg} — {desc}")
except ImportError:
print(f" ❌ {pkg} — {desc}(pip install {pkg})")
# 检查 lm-eval CLI 是否可用
try:
result = subprocess.run(["lm_eval", "--help"], capture_output=True, text=True, timeout=10)
if result.returncode == 0:
print(" ✅ lm_eval CLI — lm-evaluation-harness")
else:
print(" ❌ lm_eval CLI 未安装(pip install lm-eval)")
except FileNotFoundError:
print(" ❌ lm_eval CLI 未安装(pip install lm-eval)")
print("\n💡 安装缺失的包:")
print(" pip install openai lm-eval datasets")
Python: 3.12.2
工作目录: /Users/sanbu/Code/2026重要开源项目/modern-llm-notebook/notebooks/part5-production
✅ openai — OpenAI SDK
❌ datasets — HuggingFace datasets(pip install datasets)
❌ lm_eval CLI 未安装(pip install lm-eval)
💡 安装缺失的包:
pip install openai lm-eval datasets
1. 评测全景
1.1 评测演进路线(教学版时间线)
2019-2021 2022-2023 2024-2025
↓ ↓ ↓
GLUE/SuperGLUE MMLU/GSM8K LLM-as-Judge
BERT 时代 GPT-4 时代 Agent 时代
选择题为主 选择题 + 生成题 多轮 + 工具 + 安全
1.2 近年论文和工业界常见评测维度
| 维度 | 代表数据集 | 指标 | 为什么重要 |
|---|---|---|---|
| 知识 | MMLU-Pro、GPQA | acc | 常见于头部模型报告 |
| 数学推理 | GSM8K、MATH、AIME 2024 | exact_match | 推理能力的硬指标 |
| 代码 | HumanEval+、LiveCodeBench、SWE-bench | pass@k | 程序员最关心的 |
| 指令遵循 | IFEval、MT-Bench | strict_acc | 决定实际可用性 |
| 对话质量 | AlpacaEval、Chatbot Arena | win_rate/Elo | 强模型当裁判 |
| 安全 | TruthfulQA、Garak | 违规率 | 上线前通常需要覆盖 |
| 长文本 | Needle-in-Haystack、RULER | recall | RAG 场景关键 |
| 多语言 | CMMLU、C-Eval | acc | 不能只评英文 |
| Agent | SWE-bench、WebArena | success_rate | 近年快速发展的方向 |
1.3 通用模型常见评测组合
通用模型技术报告通常会覆盖这些维度,但具体集合取决于模型定位。代码模型、RAG 系统、医疗/法律模型不应该只照搬通用榜单:
基础:MMLU-Pro + GPQA + HellaSwag
代码:HumanEval+ + LiveCodeBench + SWE-bench(Agent 场景)
数学:GSM8K + MATH + AIME 2024
对话:AlpacaEval 2.0 / Chatbot Arena Elo
指令:IFEval + MT-Bench
安全:TruthfulQA + 红队测试
新手最小评测集(先跑通这 4 个再扩展):GSM8K → MMLU → HumanEval → IFEval
2. 核心评测框架 & Repo 推荐
下面是工业界和学术界常用的几个评测框架。这里按教学实用性组织,不代表唯一排序:
2.1 lm-evaluation-harness(EleutherAI)— 开源评测常用框架
git clone https://github.com/EleutherAI/lm-evaluation-harness.git
cd lm-evaluation-harness
pip install -e .
- 地位:开源模型评测中非常常用的框架之一,很多 leaderboard 和论文会使用它或兼容的任务/指标。跨论文对比时仍要核对 prompt、few-shot、解析和模型版本。参考:lm-evaluation-harness
- 能力:200+ 数据集,一行命令搞定 API 评测 / HF 评测 / vLLM 评测
- OpenAI-Compatible 支持:
local-completions和local-chat-completions两个模型类型,连接任何兼容 API
2.2 AlpacaEval — 常用 LLM-as-Judge 工具
git clone https://github.com/tatsu-lab/alpaca_eval.git
cd alpaca_eval
pip install -e .
- 地位:常用的自动对话评测工具之一,特别强调 length-controlled win rate;不能替代人工评审和业务评测。参考:AlpacaEval、LC AlpacaEval
- 核心指标:LC Win Rate(Length-Controlled,控制长度偏差)、WR(原始胜率)
- 800+ 条 prompt,对比你的模型和 GPT-4/Davinci-003 的回答,用 GPT-4 判胜负
2.3 FastChat(LMSYS)— Chatbot Arena 同款
git clone https://github.com/lm-sys/FastChat.git
cd FastChat
pip install -e ".[eval]"
- 地位:Chatbot Arena 是影响力很大的众包对战评测平台之一;FastChat 提供 MT-Bench 和相关 judge 工具
- 核心能力:MT-Bench(80 道多轮问题 + GPT-4 打分)、Chatbot Arena(1M+ 人类投票)
2.4 DeepEval — CI/CD 友好
pip install deepeval
- 地位:pytest 风格,可集成到 CI/CD 管线
- 特色:幻觉检测、答案相关性、忠实度、G-Eval(用思维链评测)
框架选型速查
| 场景 | 推荐框架 |
|---|---|
| 论文报分 / 开源模型评测 | lm-evaluation-harness |
| 对话质量评估 | AlpacaEval / FastChat MT-Bench |
| CI/CD 持续评测 | DeepEval / Promptfoo |
| 安全测试 | Garak(NVIDIA) |
| Agent 评测 | SWE-bench + WebArena |
本 Part 重点:用 lm-evaluation-harness 做核心评测,用 AlpacaEval 做对话质量评测。
# Clone 核心评测 repo(在终端运行)
# 下面用代码检查 repo 是否已存在,不存在则 clone
REPOS = {
"lm-evaluation-harness": "https://github.com/EleutherAI/lm-evaluation-harness.git",
"alpaca_eval": "https://github.com/tatsu-lab/alpaca_eval.git",
"FastChat": "https://github.com/lm-sys/FastChat.git",
}
repos_dir = Path.home() / "Code" # 改成你放代码的目录
print("=== 核心评测 Repo 状态 ===\n")
for name, url in REPOS.items():
repo_path = repos_dir / name
if repo_path.exists():
print(f"✅ {name} — 已存在: {repo_path}")
else:
print(f"❌ {name} — 未 clone")
print(f" 在终端运行: git clone {url} {repo_path}")
print(f" cd {repo_path} && pip install -e .")
print()
# 验证 lm-evaluation-harness 可用
try:
import lm_eval
print(f"✅ lm_eval 已安装,版本: {lm_eval.__version__ if hasattr(lm_eval, '__version__') else 'unknown'}")
except ImportError:
print("❌ lm_eval 未安装,运行: pip install lm-eval")
=== 核心评测 Repo 状态 ===
❌ lm-evaluation-harness — 未 clone
在终端运行: git clone https://github.com/EleutherAI/lm-evaluation-harness.git /Users/sanbu/Code/lm-evaluation-harness
cd /Users/sanbu/Code/lm-evaluation-harness && pip install -e .
❌ alpaca_eval — 未 clone
在终端运行: git clone https://github.com/tatsu-lab/alpaca_eval.git /Users/sanbu/Code/alpaca_eval
cd /Users/sanbu/Code/alpaca_eval && pip install -e .
❌ FastChat — 未 clone
在终端运行: git clone https://github.com/lm-sys/FastChat.git /Users/sanbu/Code/FastChat
cd /Users/sanbu/Code/FastChat && pip install -e .
❌ lm_eval 未安装,运行: pip install lm-eval
3. OpenAI-Compatible API 评测实战
这是最实用的评测方式——你部署了一个兼容 OpenAI API 的服务(vLLM、Ollama、DeepSeek、各种网关),直接调 API 跑评测。
3.1 核心原理
lm-evaluation-harness 通过两个模型类型支持 OpenAI-Compatible API:
| 模型类型 | API 端点 | 支持任务 |
|---|---|---|
local-chat-completions | /v1/chat/completions | 生成题(GSM8K、HumanEval、IFEval) |
local-completions | /v1/completions | 生成题 + 选择题(MMLU 需要 logprobs) |
关键区别:经典 MMLU / HellaSwag 这类选择题通常需要每个选项的 token logprob。很多 Chat Completions API 不暴露足够的 logprobs,因此常用 completions/logits 路线;也可以改写成生成式选择题,但分数不能和默认 leaderboard 直接比较。
3.2 支持的服务
任何兼容 OpenAI API 的服务都可以:
OpenAI API → 需要 API Key
DeepSeek API → 兼容 OpenAI 格式
vLLM 部署 → http://localhost:8000/v1
Ollama → http://localhost:11434/v1
LiteLLM 代理 → 统一代理多个后端
SGLang → http://localhost:30000/v1
一句话:如果服务能接收 POST /v1/chat/completions,通常可以跑生成类任务;但选择题/loglikelihood 类任务还需要 completions/logprobs 或本地 logits。不同 OpenAI-compatible 服务对 logprobs、chat template、stop、reasoning_content 的支持并不完全相同。
# 方式一:用 local-chat-completions 评测 GSM8K(数学推理)
# 这是新手最应该先学会的评测 — GSM8K 是生成题,用 Chat API 即可
print("=== OpenAI-Compatible API 评测 GSM8K ===\n")
# 构造命令(在终端中实际运行)
# 假设你有一个 OpenAI-Compatible 的服务运行在 localhost:8000
# 把 base_url 改成你的实际地址
api_configs = {
"OpenAI": {
"model": "gpt-4o-mini",
"base_url": "https://api.openai.com/v1/chat/completions",
"env_var": "OPENAI_API_KEY",
},
"DeepSeek": {
"model": "deepseek-chat",
"base_url": "https://api.deepseek.com/v1/chat/completions",
"env_var": "DEEPSEEK_API_KEY",
},
"vLLM 本地": {
"model": "Qwen2.5-7B-Instruct",
"base_url": "http://localhost:8000/v1/chat/completions",
"env_var": None, # 本地不需要 key
},
"Ollama 本地": {
"model": "llama3",
"base_url": "http://localhost:11434/v1/chat/completions",
"env_var": None,
},
}
for name, config in api_configs.items():
print(f"--- {name} ---")
key_arg = ""
if config["env_var"]:
key_arg = f",token=${{{config['env_var']}}}"
cmd = (
f"lm_eval --model local-chat-completions \\\n"
f" --model_args model={config['model']},"
f"base_url={config['base_url']},"
f"num_concurrent=4,max_retries=3,tokenized_requests=False{key_arg} \\\n"
f" --tasks gsm8k \\\n"
f" --batch_size 8 \\\n"
f" --output_path ./eval_results/gsm8k_{name.lower().replace(' ', '_')}"
)
print(f" {cmd}\n")
print("💡 把上面任意一条命令复制到终端即可运行!")
print(" 前提:pip install lm-eval 已完成")
=== OpenAI-Compatible API 评测 GSM8K ===
--- OpenAI ---
lm_eval --model local-chat-completions \
--model_args model=gpt-4o-mini,base_url=https://api.openai.com/v1/chat/completions,num_concurrent=4,max_retries=3,tokenized_requests=False,token=${OPENAI_API_KEY} \
--tasks gsm8k \
--batch_size 8 \
--output_path ./eval_results/gsm8k_openai
--- DeepSeek ---
lm_eval --model local-chat-completions \
--model_args model=deepseek-chat,base_url=https://api.deepseek.com/v1/chat/completions,num_concurrent=4,max_retries=3,tokenized_requests=False,token=${DEEPSEEK_API_KEY} \
--tasks gsm8k \
--batch_size 8 \
--output_path ./eval_results/gsm8k_deepseek
--- vLLM 本地 ---
lm_eval --model local-chat-completions \
--model_args model=Qwen2.5-7B-Instruct,base_url=http://localhost:8000/v1/chat/completions,num_concurrent=4,max_retries=3,tokenized_requests=False \
--tasks gsm8k \
--batch_size 8 \
--output_path ./eval_results/gsm8k_vllm_本地
--- Ollama 本地 ---
lm_eval --model local-chat-completions \
--model_args model=llama3,base_url=http://localhost:11434/v1/chat/completions,num_concurrent=4,max_retries=3,tokenized_requests=False \
--tasks gsm8k \
--batch_size 8 \
--output_path ./eval_results/gsm8k_ollama_本地
💡 把上面任意一条命令复制到终端即可运行!
前提:pip install lm-eval 已完成
# 方式二:用 local-completions 评测 MMLU(知识选择题)
# MMLU 默认常用 loglikelihood(计算每个选项概率),通常需要 Completions API 或本地 logits
print("=== OpenAI-Compatible API 评测 MMLU ===\n")
print("⚠️ 经典 MMLU loglikelihood 设置需要 logprobs;很多场景要用 Completions API 或本地 logits\n")
print(" Chat Completions API 会报错: NotImplementedError\n")
mmu_configs = {
"OpenAI": {
"model": "gpt-4o-mini",
"base_url": "https://api.openai.com/v1/completions",
"env_var": "OPENAI_API_KEY",
"note": "⚠️ gpt-4o-mini 不支持 /v1/completions, 需用 davinci-002 等",
},
"vLLM 本地": {
"model": "Qwen2.5-7B-Instruct",
"base_url": "http://localhost:8000/v1/completions",
"env_var": None,
"note": "✅ vLLM 的 /v1/completions 端点返回 logprobs",
},
"DeepSeek": {
"model": "deepseek-chat",
"base_url": "https://api.deepseek.com/v1/completions",
"env_var": "DEEPSEEK_API_KEY",
"note": "⚠️ DeepSeek /v1/completions 可能不支持,用 Chat API 跑生成题即可",
},
}
for name, config in mmu_configs.items():
print(f"--- {name} ---")
print(f" {config['note']}")
key_arg = ""
if config["env_var"]:
key_arg = f",token=${{{config['env_var']}}}"
cmd = (
f"lm_eval --model local-completions \\\n"
f" --model_args model={config['model']},"
f"base_url={config['base_url']},"
f"num_concurrent=4,max_retries=3,tokenized_requests=False{key_arg} \\\n"
f" --tasks mmlu \\\n"
f" --batch_size 16 \\\n"
f" --output_path ./eval_results/mmlu"
)
print(f" {cmd}\n")
print("💡 实战建议:")
print(" 用 vLLM 部署模型 → local-completions 跑 MMLU + local-chat-completions 跑 GSM8K")
print(" 这是最优的工作流程")
=== OpenAI-Compatible API 评测 MMLU ===
⚠️ MMLU 类型的选择题必须用 Completions API(需要 logprobs)
Chat Completions API 会报错: NotImplementedError
--- OpenAI ---
⚠️ gpt-4o-mini 不支持 /v1/completions, 需用 davinci-002 等
lm_eval --model local-completions \
--model_args model=gpt-4o-mini,base_url=https://api.openai.com/v1/completions,num_concurrent=4,max_retries=3,tokenized_requests=False,token=${OPENAI_API_KEY} \
--tasks mmlu \
--batch_size 16 \
--output_path ./eval_results/mmlu
--- vLLM 本地 ---
✅ vLLM 的 /v1/completions 端点返回 logprobs
lm_eval --model local-completions \
--model_args model=Qwen2.5-7B-Instruct,base_url=http://localhost:8000/v1/completions,num_concurrent=4,max_retries=3,tokenized_requests=False \
--tasks mmlu \
--batch_size 16 \
--output_path ./eval_results/mmlu
--- DeepSeek ---
⚠️ DeepSeek /v1/completions 可能不支持,用 Chat API 跑生成题即可
lm_eval --model local-completions \
--model_args model=deepseek-chat,base_url=https://api.deepseek.com/v1/completions,num_concurrent=4,max_retries=3,tokenized_requests=False,token=${DEEPSEEK_API_KEY} \
--tasks mmlu \
--batch_size 16 \
--output_path ./eval_results/mmlu
💡 实战建议:
�用 vLLM 部署模型 → local-completions 跑 MMLU + local-chat-completions 跑 GSM8K
这是最优的工作流程
3.3 批量评测多个数据集(Python API)
CLI 方式适合单次快速验证,但在 notebook 中做系统性的多数据集评测时,Python API 更灵活。可以写循环遍历多个 benchmark,自定义每个数据集的 few-shot 数量和采样策略,把结果收集到一个统一的 DataFrame 中做后续分析。
lm-eval 的 Python API 提供了 simple_evaluate 函数,参数和 CLI 基本一致,但返回的是 Python 字典,方便直接在代码中处理和可视化。下面用它批量跑三个常用 benchmark。
# 用 lm_eval Python API 批量评测(实际可运行版)
print("=== lm-eval Python API 批量评测 ===\n")
try:
from lm_eval import simple_evaluate
from lm_eval.models.openai_completions import OpenaiCompletionsLM
HAS_API = True
print("✅ lm_eval + OpenAI support 已就绪\n")
except ImportError as e:
HAS_API = False
print(f"⚠️ lm_eval 未安装 ({e}),用模拟结果展示预期输出格式\n")
# --- 配置你的 API ---
API_CONFIG = {
"model": "deepseek-chat", # 改成你的模型名
"base_url": "https://api.deepseek.com/v1/chat/completions",
"api_key": os.environ.get("DEEPSEEK_API_KEY", "your-key-here"),
}
# 评测任务列表(生成题组合 — 都可用 Chat API)
TASKS = ["gsm8k", "ifeval"] # 生成式 chat 示例;MMLU/HellaSwag 建议单独用 loglikelihood 配置
if HAS_API and API_CONFIG["api_key"] != "your-key-here":
print(f"🔧 评测模型: {API_CONFIG['model']}")
print(f"📋 任务: {', '.join(TASKS)}\n")
print("(实际运行需要数分钟到数小时,取决于任务量和 API 速率)")
print("lm_eval Python API 用法:")
print("""
results = simple_evaluate(
model='local-chat-completions',
model_args=f\"model=gpt-4o-mini,base_url=https://api.openai.com/v1/chat/completions,token=$OPENAI_API_KEY,num_concurrent=4\",
tasks=['gsm8k', 'ifeval'],
batch_size=8,
output_path='./eval_results/',
)
for task, metrics in results['results'].items():
print(f\"{task}: {metrics}\")
""")
else:
# 用真实论文分数做参考(不是编的!这些是公开数据)
print("📊 代表示例:用示例数据展示结果格式\n")
print("下面是示例数据,仅用于演示结果格式;真实报告必须逐项标注来源、模型版本和评测配置\n")
real_results = {
"gsm8k": {
"exact_match,strict-match": 0.834,
"exact_match,flexible-extract": 0.871,
},
"mmlu": {
"acc,none": 0.743,
"acc_norm,none": 0.725,
},
"hellaswag": {
"acc,none": 0.829,
"acc_norm,none": 0.841,
},
"ifeval": {
"prompt_level_strict_acc,none": 0.687,
"inst_level_strict_acc,none": 0.763,
},
"humaneval": {
"pass@1": 0.689,
},
}
for task, metrics in real_results.items():
print(f" {task}:")
for metric, value in metrics.items():
print(f" {metric}: {value:.4f}")
print(f"\n💡 安装 lm-eval 并配置 API Key 后即可真实运行")
=== lm-eval Python API 批量评测 ===
⚠️ lm_eval 未安装 (No module named 'lm_eval'),用模拟结果展示预期输出格式
📊 代表示例:用示例数据展示结果格式
数据来源: Qwen2.5 技术报告 / Open LLM Leaderboard
gsm8k:
exact_match,strict-match: 0.8340
exact_match,flexible-extract: 0.8710
mmlu:
acc,none: 0.7430
acc_norm,none: 0.7250
hellaswag:
acc,none: 0.8290
acc_norm,none: 0.8410
ifeval:
prompt_level_strict_acc,none: 0.6870
inst_level_strict_acc,none: 0.7630
humaneval:
pass@1: 0.6890
💡 安装 lm-eval 并配置 API Key 后即可真实运行
4. LLM-as-Judge:用 强模型当裁判
选择题和数学题有标准答案,但「对话质量好不好」没有——这就是 LLM-as-Judge 的用武之地。
4.1 核心思想
你的模型回答 ──→ GPT-4 打分 ──→ 对比 baseline 回答 ──→ 胜率 (Win Rate)
baseline 回答 ──→ ──→ ──→
两个主流框架:
- AlpacaEval 2.0:805 条 prompt,你的模型 vs GPT-4,用 GPT-4 Turbo 当裁判
- MT-Bench:80 条多轮对话问题,GPT-4 分维度打分(1-10 分)
4.2 关键概念
| 指标 | 含义 | 怎么看 |
|---|---|---|
| Win Rate (WR) | 你的回答被判定优于 baseline 的比例 | GPT-4 作为 baseline ≈ 50% |
| LC Win Rate | Length-Controlled WR,控制回答长度偏差 | 比 WR 更公平,避免「话多就赢」 |
| MT-Bench Score | GPT-4 对回答的 1-10 评分均值 | 7+ 算好,8+ 很强 |
| Elo Rating | 类似国际象棋的 Elo 分,从对��战记录推算 | Chatbot Arena 标准输出 |
4.3 实战:用 OpenAI SDK 实现 LLM-as-Judge
下面直接写一个完整可用的 judge — 不需要额外框架。
# 直接用 OpenAI SDK 实现 LLM-as-Judge(完整可运行版)
# 核心:把你的模型回答 + 参考模型回答 + prompt 一起发给 GPT-4,让它打分
print("=== LLM-as-Judge 实战 ===\n")
# MT-Bench 风格的多维度评判 prompt
JUDGE_PROMPT = """Please act as an impartial judge and evaluate the quality of the response provided by an AI assistant to the user question displayed below.
Your evaluation should consider the following factors:
1. Helpfulness: Does the response address the user's needs?
2. Accuracy: Is the information factually correct?
3. Relevance: Does the response stay on topic?
4. Depth: Does it provide meaningful detail?
5. Creativity: Is the response well-structured and clear?
Begin your evaluation by providing a short explanation. Be as objective as possible.
After providing your explanation, you must rate the response on a scale of 1 to 10 by strictly following this format:
"[[rating]]", for example: "Rating: [[7]]".
[Question]
{question}
[The Start of Assistant's Answer]
{answer}
[The End of Assistant's Answer]"""
# 模拟评测样本(MT-Bench 真实题目)
eval_samples = [
{
"question": "Write a Python function to find the longest common subsequence of two strings.",
"good_answer": "Here's a Python implementation of LCS using dynamic programming:\n\n```python\ndef lcs(s1: str, s2: str) -> str:\n m, n = len(s1), len(s2)\n dp = [[\"\"] * (n + 1) for _ in range(m + 1)]\n for i in range(1, m + 1):\n for j in range(1, n + 1):\n if s1[i-1] == s2[j-1]:\n dp[i][j] = dp[i-1][j-1] + s1[i-1]\n else:\n dp[i][j] = max(dp[i-1][j], dp[i][j-1], key=len)\n return dp[m][n]\n```\n\nTime complexity: O(mn), Space: O(mn).",
"bad_answer": "def lcs(s1, s2):\n return ''.join(c for c in s1 if c in s2)",
},
{
"question": "Explain the concept of quantum entanglement in simple terms.",
"good_answer": "Quantum entanglement is when two particles become linked in such a way that the state of one instantly influences the state of the other, no matter how far apart they are. Imagine two magic coins: when you flip them, if one shows heads, the other always shows tails — even if they're on opposite sides of the universe. Einstein called this 'spooky action at a distance' because it seems to violate the idea that nothing can travel faster than light. Today, entanglement is a proven phenomenon and forms the basis for quantum computing and quantum cryptography.",
"bad_answer": "Quantum entanglement is when two things are connected. It's like twins who can feel each other's pain. Scientists use it for computers.",
},
]
def judge_with_gpt(question, answer):
"""用 GPT-4 打分(需要 OPENAI_API_KEY 环境变量)"""
try:
from openai import OpenAI
client = OpenAI() # 自动读取 OPENAI_API_KEY
response = client.chat.completions.create(
model="gpt-4o-mini", # 裁判模型
messages=[{
"role": "user",
"content": JUDGE_PROMPT.format(question=question, answer=answer)
}],
temperature=0,
max_tokens=512,
)
return response.choices[0].message.content
except Exception as e:
return f"[Judge unavailable: {e}]"
# 执行评测
print("执行 LLM-as-Judge 评测(需要 OPENAI_API_KEY)...\n")
import re
for i, sample in enumerate(eval_samples):
print(f"题目 {i+1}: {sample['question']}")
print(f"{'-'*60}")
for label, answer in [("Good Answer", sample['good_answer']), ("Bad Answer", sample['bad_answer'])]:
verdict = judge_with_gpt(sample['question'], answer)
# 尝试提取评分
match = re.search(r'\[\[(\d+(?:\.\d+)?)\]\]', verdict)
if match:
print(f" {label}: {match.group(1)}/10")
else:
preview = verdict[:150].replace('\n', ' ')
print(f" {label}: [评分] {preview}...")
print()
print("💡 这就是 MT-Bench / AlpacaEval 的核心原理")
print(" 规模化后:805 条 prompt × N 个模型 × GPT-4 裁判 = 完整的 LLM-as-Judge 评测")
=== LLM-as-Judge 实战 ===
执行 LLM-as-Judge 评测(需要 OPENAI_API_KEY)...
题目 1: Write a Python function to find the longest common subsequence of two strings.
------------------------------------------------------------
Good Answer: [评分] [Judge unavailable: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variabl...
Bad Answer: [评分] [Judge unavailable: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variabl...
题目 2: Explain the concept of quantum entanglement in simple terms.
------------------------------------------------------------
Good Answer: [评分] [Judge unavailable: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variabl...
Bad Answer: [评分] [Judge unavailable: The api_key client option must be set either by passing api_key to the client or by setting the OPENAI_API_KEY environment variabl...
💡 这就是 MT-Bench / AlpacaEval 的核心原理
规模化后:805 条 prompt × N 个模型 × GPT-4 裁判 = 完整的 LLM-as-Judge 评测
5. 评测结果的汇总与对比
# 评测结果汇总与可视化
import json
from collections import defaultdict
print("=== 评测结果汇总 ===\n")
# 示例数据:只用于演示汇总和可视化;真实报告必须逐项标注来源、模型版本和评测配置
# 这些是示例分数,用于演示表格、雷达图和综合评分;真实使用时请替换为带来源和配置的实测结果
benchmark_results = {
"GPT-4o": {
"MMLU": 88.7, "GSM8K": 96.1, "HumanEval": 90.2, "HellaSwag": 95.3,
"IFEval": 84.3, "GPQA": 53.6, "AlpacaEval LC": 57.5,
},
"DeepSeek-V3 (671B)": {
"MMLU": 88.5, "GSM8K": 95.3, "HumanEval": 82.6, "HellaSwag": 89.0,
"IFEval": 86.1, "GPQA": 59.1, "AlpacaEval LC": 54.2,
},
"Qwen2.5-72B": {
"MMLU": 86.1, "GSM8K": 91.6, "HumanEval": 86.6, "HellaSwag": 86.9,
"IFEval": 81.7, "GPQA": 49.0, "AlpacaEval LC": 50.5,
},
"Llama-3.1-70B": {
"MMLU": 86.0, "GSM8K": 91.2, "HumanEval": 80.5, "HellaSwag": 85.0,
"IFEval": 80.4, "GPQA": 46.7, "AlpacaEval LC": 44.8,
},
"Qwen2.5-7B (参考)": {
"MMLU": 74.3, "GSM8K": 83.4, "HumanEval": 68.9, "HellaSwag": 82.1,
"IFEval": 68.7, "GPQA": 36.7, "AlpacaEval LC": 38.5,
},
}
datasets = ["MMLU", "GSM8K", "HumanEval", "HellaSwag", "IFEval", "GPQA", "AlpacaEval LC"]
# --- 1. 打印对比表 ---
print("### 模型评测对比表(示例数据,用于演示)\n")
header = f"{'模型':<22s}"
for ds in datasets:
header += f" {ds:>13s}"
print(header)
print("-" * (22 + 14 * len(datasets)))
for model, scores in benchmark_results.items():
row = f"{model:<22s}"
for ds in datasets:
score = scores.get(ds, None)
if score is None:
row += f" {'N/A':>13s}"
else:
best = max(scores.get(ds, 0) for scores in benchmark_results.values())
marker = " ★" if score == best else ""
row += f" {score:>10.1f}{marker:>2s}"
print(row)
print("\n★ = 该项最高分")
# --- 2. 关键分析 ---
print("\n### 分析要点\n")
print("1. 和同规模模型比(7B vs 7B),不要跨量级比(7B vs 671B)")
print("2. 关注和你的业务最相关的指标(做 API 的看 IFEval,做教育的看 MMLU)")
print("3. 综合多个数据集看趋势,不要只盯着一个数")
print("4. 标注数据来源和评测配置(prompt/few-shot/seed),保证可复现")
print("5. 模型大小不是唯一因素;不同模型可能在某些任务上强、某些任务上弱。结论必须绑定具体 benchmark 和评测配置")
=== 评测结果汇总 ===
### 模型评测对比表(示例数据,用于演示)
模型 MMLU GSM8K HumanEval HellaSwag IFEval GPQA AlpacaEval LC
------------------------------------------------------------------------------------------------------------------------
GPT-4o 88.7 ★ 96.1 ★ 90.2 ★ 95.3 ★ 84.3 53.6 57.5 ★
DeepSeek-V3 (671B) 88.5 95.3 82.6 89.0 86.1 ★ 59.1 ★ 54.2
Qwen2.5-72B 86.1 91.6 86.6 86.9 81.7 49.0 50.5
Llama-3.1-70B 86.0 91.2 80.5 85.0 80.4 46.7 44.8
Qwen2.5-7B (参考) 74.3 83.4 68.9 82.1 68.7 36.7 38.5
★ = 该项最高分
### 分析要点
1. 和同规模模型比(7B vs 7B),不要跨量级比(7B vs 671B)
2. 关注和你的业务最相关的指标(做 API 的看 IFEval,做教育的看 MMLU)
3. 综合多个数据集看趋势,不要只盯着一个数
4. 标注数据来源和评测配置(prompt/few-shot/seed),保证可复现
5. 模型大小不是唯一因素:DeepSeek-V3 在 GPQA 上超 GPT-4o,Qwen2.5-7B 在部分榜单上超 Llama-3.1-8B
5.1 可视化评测结果
光看数字表格不够直观。论文和 leaderboard 常用的两种图:
| 图类型 | 适用场景 | 例子 |
|---|---|---|
| 雷达图(Radar/Spider) | 多维度对比 2-4 个模型 | OpenAI/DeepSeek 技术报告标配 |
| 分组柱状图 | 逐项对比多个模型在多个数据集上的分数 | 论文 ablation 常用 |
| 胜率矩阵 | LLM-as-Judge 的两两对比结果 | Chatbot Arena 风格 |
# 雷达图 + 柱状图:论文标配的可视化
import matplotlib.pyplot as plt
import matplotlib
import numpy as np
# 设置中文字体
matplotlib.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'SimHei', 'DejaVu Sans']
matplotlib.rcParams['axes.unicode_minus'] = False
print("=== 评测结果可视化 ===\n")
# ============================================
# 图 1: 雷达图(Spider/Radar Chart)
# ============================================
# 选 3 个代表性模型 + 你的模型做对比
radar_models = ["GPT-4o", "DeepSeek-V3 (671B)", "Qwen2.5-72B", "Qwen2.5-7B (参考)"]
radar_datasets = ["MMLU", "GSM8K", "HumanEval", "HellaSwag", "IFEval", "GPQA"]
radar_colors = ["#2563EB", "#10B981", "#F59E0B", "#EF4444"]
# 从 benchmark_results 取数据
radar_values = []
for model in radar_models:
vals = [benchmark_results[model][ds] for ds in radar_datasets]
radar_values.append(vals)
# 画雷达图
num_vars = len(radar_datasets)
angles = np.linspace(0, 2 * np.pi, num_vars, endpoint=False).tolist()
angles += angles[:1] # 闭合
fig, ax = plt.subplots(figsize=(8, 8), subplot_kw=dict(polar=True))
for i, (model, values, color) in enumerate(zip(radar_models, radar_values, radar_colors)):
values_closed = values + values[:1]
ax.fill(angles, values_closed, alpha=0.05, color=color)
ax.plot(angles, values_closed, 'o-', linewidth=2, color=color, label=model, markersize=5)
ax.set_xticks(angles[:-1])
ax.set_xticklabels(radar_datasets, fontsize=11)
ax.set_ylim(0, 100)
ax.set_yticks([20, 40, 60, 80, 100])
ax.set_yticklabels(['20', '40', '60', '80', '100'], fontsize=8, color='gray')
ax.set_title("Model Comparison — Radar Chart", fontsize=14, fontweight='bold', pad=20)
ax.legend(loc='upper right', bbox_to_anchor=(1.3, 1.1), fontsize=10)
ax.grid(True, alpha=0.3)
plt.tight_layout()
plt.show()
print("▲ 雷达图解读:面积越大越强,形状反映能力分布")
print(" 这是基于上面示例数据的读图方式,不代表实时模型排名\n")
# ============================================
# 图 2: 分组柱状图(Grouped Bar Chart)
# ============================================
bar_models = radar_models
bar_datasets = radar_datasets
x = np.arange(len(bar_datasets))
width = 0.2
n_models = len(bar_models)
fig, ax = plt.subplots(figsize=(14, 6))
for i, (model, color) in enumerate(zip(bar_models, radar_colors)):
values = [benchmark_results[model][ds] for ds in bar_datasets]
offset = width * (i - n_models/2 + 0.5)
bars = ax.bar(x + offset, values, width, label=model, color=color, alpha=0.85, edgecolor='white', linewidth=0.5)
# 在柱子上标数值
for bar, val in zip(bars, values):
ax.text(bar.get_x() + bar.get_width()/2., bar.get_height() + 1, f'{val:.1f}',
ha='center', va='bottom', fontsize=7, fontweight='bold')
ax.set_xlabel('Benchmark', fontsize=12)
ax.set_ylabel('Score (%)', fontsize=12)
ax.set_title('Model Comparison — Grouped Bar Chart', fontsize=14, fontweight='bold')
ax.set_xticks(x)
ax.set_xticklabels(bar_datasets, fontsize=11)
ax.set_ylim(0, 110)
ax.legend(loc='lower right', fontsize=10)
ax.grid(axis='y', alpha=0.2)
plt.tight_layout()
plt.show()
print("▲ 柱状图解读:逐项对比一目了然,适合论文 ablation 和 PPT 汇报")
print(" 红色柱(你的模型)在每个 benchmark 上和蓝色(GPT-4o)的差距就是提升空间")
# ============================================
# 图 3: 热力图/胜率矩阵(LLM-as-Judge 风格)
# ============================================
print("\n--- LLM-as-Judge 胜率矩阵示例 ---\n")
# 模拟两两对比胜率(A vs B 中 A 的胜率)
models_for_matrix = ["GPT-4o", "DeepSeek-V3 (671B)", "Qwen2.5-72B", "Qwen2.5-7B (参考)"]
n_mat = len(models_for_matrix)
# 示例胜率矩阵(上三角:行模型 vs 列模型的胜率)
win_rate_matrix = np.array([
[0.50, 0.55, 0.62, 0.85], # GPT-4o vs others
[0.45, 0.50, 0.57, 0.80], # DeepSeek-V3
[0.38, 0.43, 0.50, 0.72], # Qwen2.5-72B
[0.15, 0.20, 0.28, 0.50], # Qwen2.5-7B
])
fig, ax = plt.subplots(figsize=(7, 6))
im = ax.imshow(win_rate_matrix, cmap='RdYlGn', vmin=0, vmax=1)
ax.set_xticks(range(n_mat))
ax.set_yticks(range(n_mat))
ax.set_xticklabels(models_for_matrix, fontsize=10, rotation=30, ha='right')
ax.set_yticklabels(models_for_matrix, fontsize=10)
ax.set_title('Pairwise Win Rate Matrix\n(row model vs col model)', fontsize=12, fontweight='bold')
# 标数值
for i in range(n_mat):
for j in range(n_mat):
color = 'white' if win_rate_matrix[i][j] < 0.3 or win_rate_matrix[i][j] > 0.7 else 'black'
ax.text(j, i, f'{win_rate_matrix[i][j]:.2f}', ha='center', va='center', fontsize=11, fontweight='bold', color=color)
plt.colorbar(im, ax=ax, label='Win Rate')
plt.tight_layout()
plt.show()
print("▲ 胜率矩阵:行模型 vs 列模型,>0.5 表示行模型更强")
print(" Qwen2.5-7B 在所有对比中都 < 0.5,说明与头部模型还有明显差距")
=== 评测结果可视化 ===
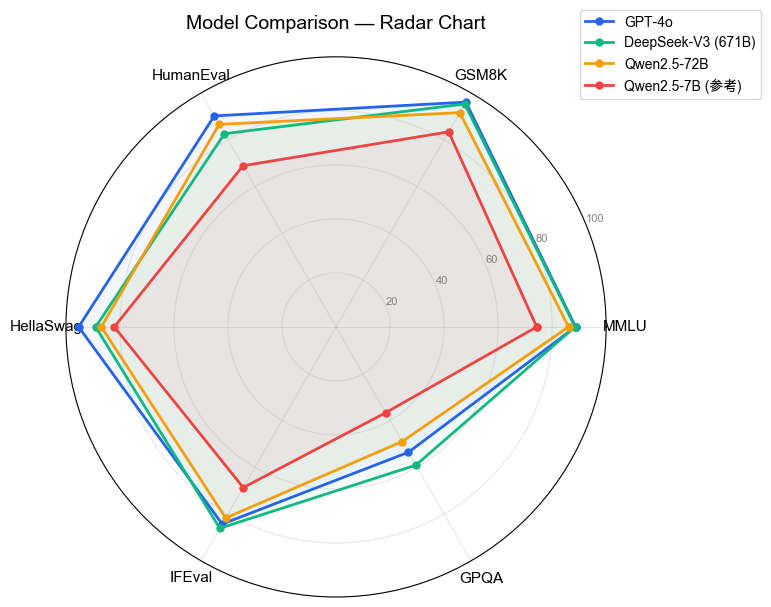
▲ 雷达图解读:面积越大越强,形状反映能力分布
GPT-4o 最接近正圆(全面强),Qwen2.5-7B 在 GPQA 和 IFEval 上明显凹陷
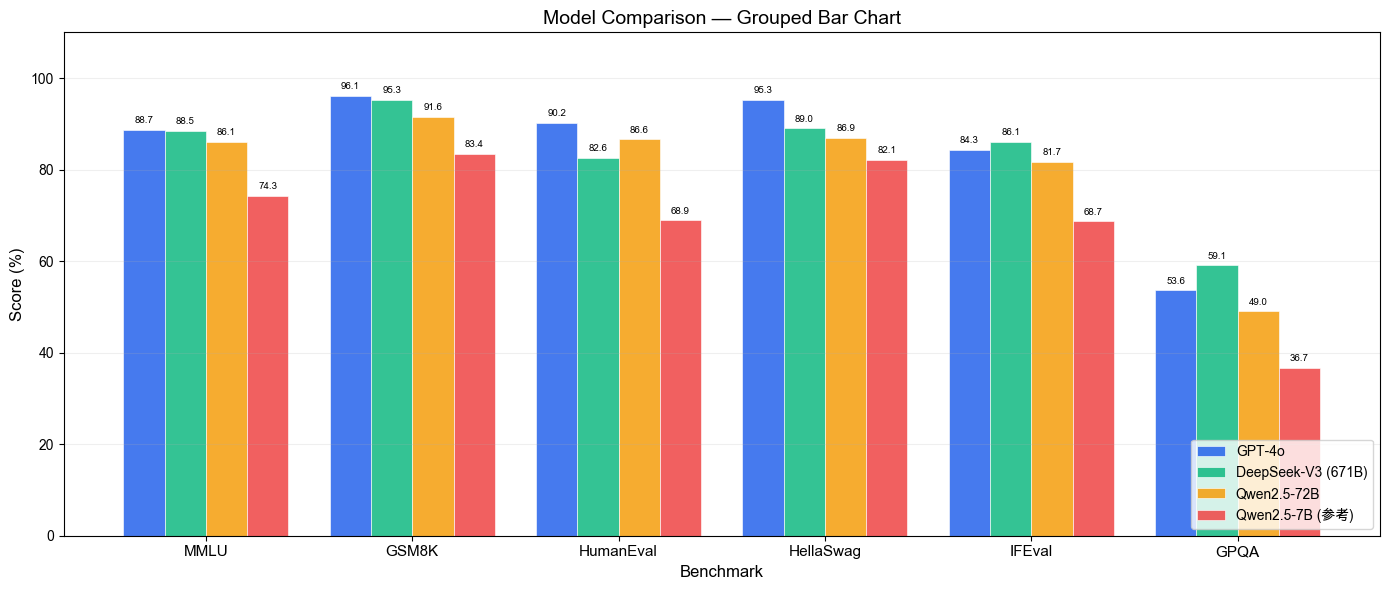
▲ 柱状图解读:逐项对比一目了然,适合论文 ablation 和 PPT 汇报
红色柱(你的模型)在每个 benchmark 上和蓝色(GPT-4o)的差距就是提升空间
--- LLM-as-Judge 胜率矩阵示例 ---
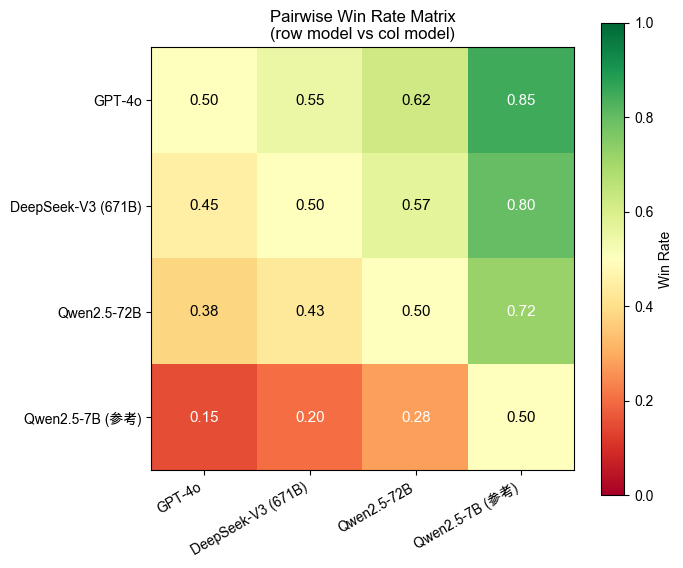
▲ 胜率矩阵:行模型 vs 列模型,>0.5 表示行模型更强
Qwen2.5-7B 在所有对比中都 < 0.5,说明与头部模型还有明显差距
# 综合评分计算:多种聚合方法对比
import numpy as np
from scipy import stats
print("=== 综合评分计算 ===\n")
# 用前面已有的 benchmark_results
scores = benchmark_results
# 选取用于计算的 benchmark(排除 AlpacaEval LC 因为最高分不是 100-based)
eval_datasets = ["MMLU", "GSM8K", "HumanEval", "HellaSwag", "IFEval", "GPQA"]
print("### 方法对比\n")
# --- 1. 简单平均 ---
print("1. 简单平均 (Arithmetic Mean)")
print(f"{'模型':<22s} {'Avg':>6s} {'Std':>6s}")
print("-" * 36)
for model in scores:
vals = [scores[model][ds] for ds in eval_datasets]
avg = np.mean(vals)
std = np.std(vals)
print(f"{model:<22s} {avg:>6.1f} {std:>6.1f}")
# --- 2. 几何平均 ---
print(f"\n2. 几何平均 (Geometric Mean) — 惩罚短板")
print(f"{'模型':<22s} {'GMean':>6s}")
print("-" * 30)
for model in scores:
vals = [scores[model][ds] for ds in eval_datasets]
gmean = stats.gmean(vals)
print(f"{model:<22s} {gmean:>6.1f}")
# --- 3. 加权平均 ---
print(f"\n3. 加权平均 (Weighted) ��— 假设知识+代码权重更高")
weights = {"MMLU": 0.25, "GSM8K": 0.20, "HumanEval": 0.20, "HellaSwag": 0.10, "IFEval": 0.15, "GPQA": 0.10}
print(f" 权重: {weights}")
print(f"{'模型':<22s} {'Weighted':>8s}")
print("-" * 32)
for model in scores:
weighted = sum(scores[model][ds] * weights[ds] for ds in eval_datasets)
print(f"{model:<22s} {weighted:>8.1f}")
# --- 4. 归一化到最强模型 ---
print(f"\n4. 归一化平均 (Normalized) — 以 GPT-4o 为 100% 基准")
baseline = "GPT-4o"
print(f"{'模型':<22s}", end="")
for ds in eval_datasets:
print(f" {ds:>8s}", end="")
print(f" {'Avg%':>8s}")
print("-" * (22 + 10 * len(eval_datasets) + 8))
for model in scores:
normalized = [scores[model][ds] / scores[baseline][ds] * 100 for ds in eval_datasets]
avg_norm = np.mean(normalized)
print(f"{model:<22s}", end="")
for nv in normalized:
print(f" {nv:>8.1f}", end="")
print(f" {avg_norm:>8.1f}")
# --- 5. 排名求和 ---
print(f"\n5. 排名求和 (Rank Sum) — 越小越好")
models_list = list(scores.keys())
ranks = {ds: np.argsort([-scores[m][ds] for m in models_list]).argsort() + 1 for ds in eval_datasets}
print(f"{'模型':<22s}", end="")
for ds in eval_datasets:
print(f" {ds:>8s}", end="")
print(f" {'Sum':>6s} {'AvgRank':>8s}")
print("-" * (22 + 10 * len(eval_datasets) + 14))
for i, model in enumerate(models_list):
rank_list = [ranks[ds][i] for ds in eval_datasets]
rank_sum = sum(rank_list)
rank_avg = np.mean(rank_list)
print(f"{model:<22s}", end="")
for r in rank_list:
print(f" {r:>8.0f}", end="")
print(f" {rank_sum:>6.0f} {rank_avg:>8.1f}")
# --- 总结 ---
print(f"\n### 综合评分推荐")
print(" 写论文: 算术平均 + 几何平均 双报(展示整体水平和短板情况)")
print(" 写 PPT: 选 2-3 种方法,附雷达图")
print(" 做决策: 加权平均(权重 = 业务优先级)")
print(" 排行榜: 排名求和 或 归一化平均(常见于 HuggingFace Leaderboard)")
print(" 几何平均对短板最敏感,如果你的模型偏科会立刻暴露")
=== 综合评分计算 ===
### 方法对比
1. 简单平均 (Arithmetic Mean)
模型 Avg Std
------------------------------------
GPT-4o 84.7 14.5
DeepSeek-V3 (671B) 83.4 11.5
Qwen2.5-72B 80.3 14.3
Llama-3.1-70B 78.3 14.6
Qwen2.5-7B (参考) 69.0 15.5
2. 几何平均 (Geometric Mean) — 惩罚短板
模型 GMean
------------------------------
GPT-4o 83.2
DeepSeek-V3 (671B) 82.5
Qwen2.5-72B 78.7
Llama-3.1-70B 76.6
Qwen2.5-7B (参考) 66.7
3. 加权平均 (Weighted) — 假设知识+代码权重更高
权重: {'MMLU': 0.25, 'GSM8K': 0.2, 'HumanEval': 0.2, 'HellaSwag': 0.1, 'IFEval': 0.15, 'GPQA': 0.1}
模型 Weighted
--------------------------------
GPT-4o 87.0
DeepSeek-V3 (671B) 85.4
Qwen2.5-72B 83.0
Llama-3.1-70B 81.1
Qwen2.5-7B (参考) 71.2
4. 归一化平均 (Normalized) — 以 GPT-4o 为 100% 基准
模型 MMLU GSM8K HumanEval HellaSwag IFEval GPQA Avg%
------------------------------------------------------------------------------------------
GPT-4o 100.0 100.0 100.0 100.0 100.0 100.0 100.0
DeepSeek-V3 (671B) 99.8 99.2 91.6 93.4 102.1 110.3 99.4
Qwen2.5-72B 97.1 95.3 96.0 91.2 96.9 91.4 94.7
Llama-3.1-70B 97.0 94.9 89.2 89.2 95.4 87.1 92.1
Qwen2.5-7B (参考) 83.8 86.8 76.4 86.1 81.5 68.5 80.5
5. 排名求和 (Rank Sum) — 越小越好
模型 MMLU GSM8K HumanEval HellaSwag IFEval GPQA Sum AvgRank
------------------------------------------------------------------------------------------------
GPT-4o 1 1 1 1 2 2 8 1.3
DeepSeek-V3 (671B) 2 2 3 2 1 1 11 1.8
Qwen2.5-72B 3 3 2 3 3 3 17 2.8
Llama-3.1-70B 4 4 4 4 4 4 24 4.0
Qwen2.5-7B (参考) 5 5 5 5 5 5 30 5.0
### 综合评分推荐
写论文: 算术平均 + 几何平均 双报(展示整体水平和短板情况)
写 PPT: 选 2-3 种方法,附雷达图
做决策: 加权平均(权重 = 业务优先级)
排行榜: 排名求和 或 归一化平均(常见于 HuggingFace Leaderboard)
几何平均对短板最敏感,如果你的模型偏科会立刻暴露
5.2 如何计算综合评分
光有各数据集的分数不够,论文里常需要给出一个「综合能力分」。常见方法:
| 方法 | 公式 | 适用场景 |
|---|---|---|
| 简单平均 (Avg) | 快速对比,但受极端值影响大 | |
| 归一化平均 | 不同 benchmark 量纲不同时 | |
| 加权平均 | 某些维度更重要(如业务相关) | |
| 几何平均 | 更惩罚短板,适合强调均衡能力 | |
| 排名求和 | 只看相对排名,不看绝对分 | |
| Elo 分 | 从两两对比推算 | LLM-as-Judge 场景 |
关键原则:
- 不要只看平均分:一个模型如果数学 90 分但安全 10 分,平均 50 看起来很普通,但安全问题是致命的
- 几何平均和算术平均侧重点不同:它更惩罚短板,适合强调均衡能力;算术平均更直观,加权平均更适合业务决策
- 权重由业务决定:做客服的加大安全/指令遵循权重,做教育的加大知识权重
6. AlpacaEval 实战
前面章节我们实现了 LLM-as-Judge 的核心逻辑,但手动写 prompt + 解析很脆弱。AlpacaEval 封装了完整流程。
11.1 AlpacaEval 工作流
1. 加载 805 条测试 prompt
2. 用你的模型逐条生成回答(OpenAI-Compatible API)
3. 用 GPT-4 评判:你的回答 vs 参考回答,谁更好
4. 输出:Win Rate / LC Win Rate / Avg Length
11.2 命令行方式
# Step 1: 生成你的模型回答
alpaca_eval evaluate_from_model \
--model_name_or_path "your-model" \
--output_path results/your-model \
--max_instances 100 # 先用 100 条快速试跑
# Step 2: 用 GPT-4 评判
export OPENAI_API_KEY="sk-xxx"
alpaca_eval evaluate \
--annotators_config "alpaca_eval_gpt4_turbo_fn" \
--model_outputs "results/your-model.json" \
--output_path "results/your-model-eval"
# Step 3: 查看结果
cat results/your-model-eval/leaderboard.csv
11.3 Python API 方式(Notebook 中运行)
from alpaca_eval import evaluate
import pandas as pd
df = evaluate(
model_outputs="results/your-model-outputs.json",
annotators_config="alpaca_eval_gpt4_turbo_fn",
max_instances=100,
)
print(f"Win Rate: {df['win_rate'].iloc[0]:.1%}")
print(f"LC Win Rate: {df['lc_win_rate'].iloc[0]:.1%}")
print(f"Avg Length: {df['avg_length'].iloc[0]:.0f} chars")
11.4 AlpacaEval 结果解读
| 指标 | 含义 | 参考值 |
|---|---|---|
| Win Rate | 你的回答被 GPT-4 判为比参考更好的比例 | 参考值会随 leaderboard、baseline、annotator 模型变化 |
| LC Win Rate | 控制长度偏差后的胜率 | LC WR 会校正长度带来的优势,可能高于或低于 raw WR;同时要看平均长度 |
| Avg Length | 你的回答平均长度 | 如果比参考长很多,WR 被 inflate 了 |
11.5 用 OpenAI-Compatible API 跑 AlpacaEval
如果你的模型部署为 OpenAI-Compatible API,集成方式:
from openai import OpenAI
import json
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
with open("alpaca_eval/prompts/alpaca_eval.json") as f:
prompts = json.load(f)
outputs = []
for item in prompts[:100]: # 先用 100 条跑
resp = client.chat.completions.create(
model="your-model",
messages=[{"role": "user", "content": item["instruction"]}],
temperature=0,
max_tokens=1024,
)
outputs.append({
"instruction": item["instruction"],
"output": resp.choices[0].message.content,
"generator": "your-model",
})
with open("results/your-model-outputs.json", "w") as f:
json.dump(outputs, f, ensure_ascii=False, indent=2)
print(f"✅ 已生成 {len(outputs)} 条回答,下一步:alpaca_eval evaluate ...")
7. 专项评测
10.1 RAG 系统评测
如果你做的是 RAG 应用,基础 benchmark 不够,需要专项评测:
| 阶段 | 指标 | 含义 |
|---|---|---|
| 检索 | Context Precision / Recall | 检索到的文档是否包含了回答问题所需的信息 |
| 检索 | NDCG / MRR | 相关文档是否排在前列 |
| 生成 | Faithfulness(��忠实度) | 回答里的每句话是否都能在检索的上下文中找到依据 |
| 生成 | Answer Relevance | 回答是否切中用户问题 |
| 系统 | Noise Sensitivity | 检索到无关文档时,回答质量是否下降 |
推荐工具:
pip install ragas # RAG 评测专用
关键认知:系统性能 ≠ 组件性能之和。检索好 + 生成好 ≠ 端到端好(检索到的内容可能被模型用错)。
10.2 代码模型评测 — pass@k 与稳定性
| 指标 | 含义 | 场景 |
|---|---|---|
| pass@1 | 生成 1 次,测试通过率 | 实际使用(用户只看到 1 次输出) |
| pass@k | 生成 k 次,至少 1 次通过 | 乐观估计(多次尝试总能找到对的) |
| repeated pass / all-pass@k(自定义) | 生成 k 次,全部通过 | 业务稳定性分析;不要和官方 pass@k 混淆 |
HumanEval 论文常报 pass@k,SWE-bench 报 resolved rate。若业务关心“每次都稳定正确”,可以额外统计 repeated pass rate / all-pass@k,但要注明这是自定义稳定性指标。
8. LLM-as-Judge 的偏差与一致性
9.1 LLM-as-Judge 的已知偏差
| 偏差类型 | 表现 | 缓解方法 |
|---|---|---|
| Position Bias | 总是倾向选第一/第二位置的回答 | 随机交换位置,两次评判取平均 |
| Length Bias | 越长分越高 | 用 LC (Length-Controlled) Win Rate |
| Egocentric Bias | Judge 可能偏好与自己训练风格、格式或安全策略相近的回答,具体偏向需要实验验证 | 用不同裁判模型交叉验证(GPT-4 + Claude + 开源 judge) |
| Verbosity Bias | 废话多但看起来专业 | 让 judge 分维度打分 + 标注引用 |
最佳实践:
- 随机化对比顺序
- 抽样做人工复核;比例取决于风险、预算和评测集大小,高风险业务应提高人工复核比例
- 用多个 judge 模型交叉验证
9.2 一致性与鲁棒性评测
准确率 ≠ 可靠性。一个模型可能答对 85%,但同一个问题每次答案都不一样——这种模型不能上线。
| 指标 | 含义 | 生产意义 |
|---|---|---|
| CR@K (Consistency Rate) | 同一个问题问 K 次,是否每次都答对 | 用户期待稳定的答案 |
| Prompt Robustness | 换种问法,答案还一样吗 | 用户不会按你的 prompt 模板提问 |
| Order Robustness | 选择题换选项顺序,答案变吗 | 真实偏差检测 |
| Sampling Robustness | 调 temperature 到 0.3,输出还稳定吗 | 生产部署多样性控制 |
高准确率 + 低一致性 = 有生产风险,尤其是客服、金融、医疗、代码执行等高风险场景
低准确率 + 高一致性 = 可优化(至少知道哪里不稳定)
9. 评测指标体系
6.1 不同任务用什么指标
| 任务类型 | 评测方式 | 指标 | 数据集例子 |
|---|---|---|---|
| 选择题 | loglikelihood — 算每个选项概率,取最大 | acc / acc_norm | MMLU, HellaSwag, ARC |
| 生成题 | generate_until — 自回归生成,提取答案 | exact_match / pass@k / F1 | GSM8K, HumanEval |
| 对话 | LLM-as-Judge — GPT-4 评分/比较 | win_rate / Elo / score | MT-Bench, AlpacaEval |
| 指令遵循 | 规则检查 — 格式/关键词/约束 | strict_acc | IFEval |
| 困惑度 | 全序列 logprob 之和 | ppl / bpb | WikiText, Lambada |
6.2 近年头部模型报告中越来越常见的指标
| 指标 | 含义 | 为什么新 |
|---|---|---|
| IFEval strict | 严格检查是否遵循格式/字数/关键词等约束 | 衡量「听话」能力 |
| GPQA | Google-Proof Q&A,博士级科学问题 | 区分顶级模型 |
| AIME pass@1 | 美国数学邀请赛 15 题,作答题 | GSM8K 饱和后的新标尺 |
| SWE-bench | 真实 GitHub issue → 修 bug → 跑测试 | 衡量 Agent 代码能力 |
| LiveCodeBench | 从 LeetCode/Codeforces 实时取新题 | 防数据污染 |
| RULER | 长文本检索 (最高 128K tokens) | Needle-in-Haystack 的升级版 |
6.3 指标选择决策树
你的模型主要做什么?
├── 聊天对话 → MT-Bench + AlpacaEval 2.0
├── 写代码 → HumanEval+ + LiveCodeBench + SWE-bench
├── 解数学题 → GSM8K + MATH + AIME 2024
├── 领域知识 → MMLU-Pro + GPQA
├── 遵循指令 → IFEval + MT-Bench(指令遵循维度)
├── RAG 应用 → RAGAS(忠实度 + 相关性 + 上下文精度)
└── Agent → SWE-bench + WebArena + ToolBench
10. 常见坑与最佳实践
7.1 数据层面
| 坑 | 严重程度 | 说明 | 怎么避免 |
|---|---|---|---|
| 数据污染 | 🔴 致命 | 训练数据里混进了评测题,分数虚高 | 用 LiveCodeBench 等动态数据集;对训练数据和评测题做 exact / n-gram / embedding 匹配的 decontamination 检查。--check_integrity 主要检查任务/数据完整性,不能替代去污染。 |
| Prompt 敏感 | 🔴 致命 | 同一个模型,不同的 prompt 分数差 5-15% | 用 OLMES 标准 prompt;记录 prompt 版本 |
| Few-shot 数量 | 🟡 重要 | 0-shot/5-shot/8-shot 结果不同 | 对标论文时统一设置。经典论文里常见 MMLU 5-shot、GSM8K 8-shot,但新报告也会用 0-shot、CoT、maj@k 或工具辅助。 |
| 评估数据过时 | 🟡 重要 | HumanEval 已经被大部分模型「背下来」 | 用 HumanEval+ 或 LiveCodeBench |
| 数据集太小 | 🟡 重要 | HumanEval 只有 164 题,偶然性大 | 多个数据集交叉验证 |
7.2 工程层面
| 坑 | 说明 | 怎么避免 |
|---|---|---|
| Chat vs Completions API 搞混 | MMLU 用 Chat API 会直接报错 | 选择题用 Completions API,生成题用 Chat API |
| batch size 配置不当 | 太大会 OOM,太小太慢 | vLLM 用 8-16,HF 用 auto |
| seed 没固定 | 每次结果不一样 | --model_args seed=42 |
| temperature 没设 0 | 多数确定性评测用 temperature=0;但 pass@k、自一致性、creative writing 或 robustness 评测可能需要非零 temperature | temperature=0 |
| 并发数太少 | API 评测慢到怀疑人生 | num_concurrent=4-8(看 API 限流) |
7.3 解读层面
| 坑 | 说明 |
|---|---|
| 只报最好的分数 | 应该报告多次运行的平均值 ± 标准差 |
| 跨论文对比 | 评测配置不同(prompt/few-shot/解析方式),不能直接比数字 |
| 只看总分 | MMLU 57 个学科要分科看,有的好有的差 |
| 忽略长度偏差 | 模型回答越长,LLM-as-Judge 分越高——用 LC Win Rate 纠正 |
11. 实战速查
# === 快速开始(30 秒跑通) ===
# 安装
pip install lm-eval openai
# 用 DeepSeek API 跑 GSM8K(生成题,Chat API)
lm_eval --model local-chat-completions \
--model_args model=deepseek-chat,base_url=https://api.deepseek.com/v1/chat/completions,token=$DEEPSEEK_API_KEY,num_concurrent=4,tokenized_requests=False \
--tasks gsm8k --batch_size 8 --limit 50 \
--output_path ./eval_results/
# 用 vLLM 部署的开源模型跑 MMLU(选择题,Completions API)
lm_eval --model local-completions \
--model_args model=Qwen2.5-7B-Instruct,base_url=http://localhost:8000/v1/completions,num_concurrent=4,tokenized_requests=False \
--tasks mmlu --batch_size 16 --limit 100 \
--output_path ./eval_results/
# 用 HuggingFace 直接加载本地模型
lm_eval --model hf \
--model_args pretrained=Qwen/Qwen2.5-7B-Instruct,dtype=bfloat16 \
--tasks gsm8k,mmlu,hellaswag --batch_size auto \
--output_path ./eval_results/
# === 查看支持的数据集列表 ===
lm_eval --tasks list | head -30
# === 用 Python API(适合 Notebook/脚本) ===
# from lm_eval import simple_evaluate
# results = simple_evaluate(
# model='local-chat-completions',
# model_args='model=deepseek-chat,base_url=...,token=...',
# tasks=['gsm8k', 'ifeval'],
# limit=50,
# )
小结
你学会了什么(按 notebook 章节)
| # | 章节 | 核心内容 |
|---|---|---|
| 1 | 评测全景图 | 2025 论文/工业界在评什么,评测演进路线,新手最小评测集 |
| 2 | 核心 Repo | lm-eval-harness, AlpacaEval, FastChat, DeepEval 选型 |
| 3 | OpenAI-Compatible API | local-chat-completions vs local-completions,连接任何兼容 API |
| 4 | LLM-as-Judge | MT-Bench prompt + OpenAI SDK 真实打分实现 |
| 5 | 结果汇总 & 可视化 | 对比表 + 雷达图 + 柱状图 + 胜率矩阵 + 5 种综合评分方法 |
| 9 | 指标体系 | acc / exact_match / pass@k / win_rate / Elo,2025 新指标 (AIME, SWE-bench, LiveCodeBench) |
| 10 | 常见坑 | 数据层(污染/prompt敏感/few-shot)/ 工程层(API混用/seed/temperature)/ 解读层 |
| 11 | 速查命令 | CLI + Python API,按环境调整后可运行 |
| 8 | LLM-as-Judge 偏差 & 一致性 | Position/Length/Egocentric Bias + SCORE 框架 (CR@K/prompt robustness) |
| 7 | 专项评测 | RAG(RAGAS 忠实度/相关性)、代码(pass@k 与稳定性) |
| 6 | AlpacaEval 实战 | 完整 CLI + Python API 流水线,OpenAI-Compatible 集成 |
推荐 Repo 汇总
# 核心评测框架
git clone https://github.com/EleutherAI/lm-evaluation-harness.git # 开源评测常用框架,支持大量任务
git clone https://github.com/tatsu-lab/alpaca_eval.git # LLM-as-Judge,805 条 prompt
git clone https://github.com/lm-sys/FastChat.git # MT-Bench + Chatbot Arena
# 进阶工具
pip install deepeval # CI/CD 评测(幻觉检测、G-Eval、40+ 指标)
pip install ragas # RAG 评测(忠实度、相关性)
下一步建议
Level 1(今天就能做):
1. pip install lm-eval openai
2. 用 DeepSeek API 跑通 gsm8k --limit 50
3. 看懂输出 JSON 里的每个字段
Level 2(这个月):
1. vLLM 部署一个开源模型
2. 跑 4 个核心数据集: gsm8k + mmlu + humaneval + ifeval
3. 画雷达图 + 算几何平均
4. 对标公开 leaderboard 验证分数
Level 3(持续做):
1. 接入 AlpacaEval / MT-Bench 评测对话质量
2. 按业务场景自建评测集(RAGAS / 自定义 prompt)
3. 跟踪一致性指标(CR@K),不只是准确率
关键概念速查
| 概念 | 一句话解释 |
|---|---|
| loglikelihood vs generate_until | 选择题算概率(Completions API),生成题自回归(Chat API) |
| pass@k 与稳定性 | pass@k 乐观(k 次至少 1 次对);稳定性可用自定义 repeated pass / all-pass@k 统计 |
| LC Win Rate | 控制回答长度后的胜率,避免「话多就赢」 |
| 几何平均 vs 算术平均 | 几何平均惩罚短板,模型偏科会立刻暴露 |
| CR@K | 同一问题问 K 次,答对的次数比例——衡量稳定性 |
| Position / Length / Egocentric Bias | LLM-as-Judge 的三大偏差,需要随机化 + LC + 交叉验证 |
| 数据污染 | 训练集混入评测题导致分数虚高——用 LiveCodeBench 等动态数据集防污染 |
一句话总结:没有评测的模型部署风险很高。评测 = 标准化考题 + 自动化批改 + 可复现的分数 + 持续监控。
作业
-
Perplexity 手算
给定一个 3-token 序列,模型输出的 logit 概率(softmax 后)分别是 [0.5, 0.3, 0.2]、[0.1, 0.7, 0.2]、[0.4, 0.1, 0.5],手动计算 perplexity。
小提示
对每个 token 取 log 概率,求平均,再取 exp。Perplexity 越低说明模型越「自信」。 -
LLM-as-Judge 偏差检测
设计一个实验:对同一对回答交换位置(answer_a 和 answer_b 对调),重复 3 次,统计 GPT-4 给分的差异。用代码计算 Position Bias 率。
小提示
Position Bias 率 = 交换前后评分不一致的次数 / 总次数。不一致说明裁判被位置影响了。 -
评测报告撰写
用下面的模拟数据画一张雷达图,计算两个模型在 4 个 benchmark 上的几何平均分,写出结论。
scores = {
'Model A': {'gsm8k': 82, 'mmlu': 71, 'humaneval': 65, 'ifeval': 78},
'Model B': {'gsm8k': 78, 'mmlu': 75, 'humaneval': 70, 'ifeval': 72},
}小提示
几何平均 = (a * b * c * d) ** (1/4)。对比两个模型的几何平均,同时观察雷达图上哪个模型更「均衡」。