RAG笔记
0 序言
你知道目前卫星最多的行星是哪个吗?你之前记住的答案可能是错误的哟,让我们来开启RAG之旅吧!
1 简述
Large Model下的AIGC已然是当下最热门的AI研究方向,从language model的ChatGPT到高热度的multimodal model的Sora,把AI的研究带到了一个全新的高度,下面要讨论的是LLM相关技术内容:Retrieval-Augmented Generation(RAG),这是目前最主流的基于LLM的系统应用架构,通过整合外部知识库来增强LLM的范式。如果说LLM的finetune是model内化吸收知识的过程,那么RAG就是给LLM从外部装配上知识,它只需要利用LLM的In-context learning能力,model就可以不再需要进行pre-training和fine-tuning过程就能获得特定domain的知识,并减轻了model的long-tailed memory缺陷,还把这个过程可以做到配置化,为LLM在复杂知识密集型任务中提供了个高效的解决方案,因此RAG对于LLM来说有着诸多优点:
- 不需要去太多的fine tuning。
- 弥补了在知识realtime和long-tailed memory方面的缺陷。
- 减轻hallucination现象出现。
RAG的整体思路是非常简单的,就是Search+LLM Prompt的解决方案,有着清晰的三步流程:
- Text chunk
- Vector recall
- LLM generation
整体逻辑如下图所示:
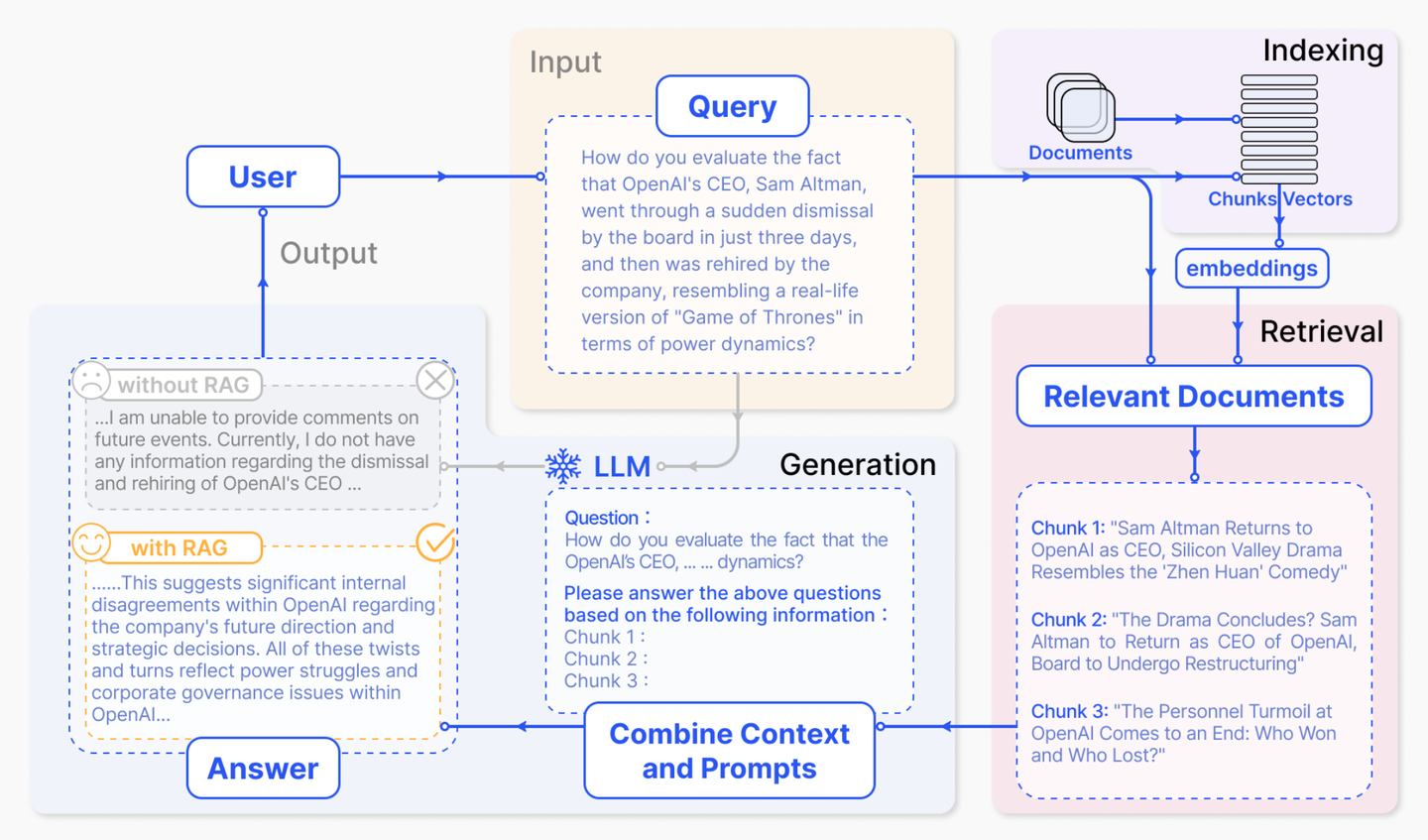
RAG流程示意图
- 输入Query在知识VectorStore检索到Top-k结果。
- 把Chunk结果和Query一起构建Prompt送入LLM。
- LLM总结归纳输出Response。
针对上面系统首要目的就是要构建一个外部知识的语料库,把documents切分成chunks,利用embedding model对chunk进行encode,建立对应的VectorStore,并创建一个LLM的prompt template。当用户query输入时,将文本送入embedding model进行vectorization,然后扔进VectorStore去recall top-k结果,并将这结果和query一起作为context组装成prompt送给LLM,最后由LLM输出response。
虽然在表面上看起来整个base架构是非常简明清晰的逻辑,不需要过多的去fine-tuning model,只靠LLM的归纳总结能力就能完成一个完整且高质量的QA任务,但实际上在这个流程里面还是有许多有趣的技术细节值得深究讨论,e.g. 数据检索、信息增强、AI生成等过程,在实际工程落地复杂度还是有一定挑战,后面章节我就以这个框架为基础把里面一些细节技术展开简单聊聊。
2 技术发展
RAG主要技术包括三个部分Retrieval、Augmentation、Generator,刚好对应了RAG三个首字母简写,其最早由Meta在2020年的NeurIPS上发表的《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中提出,当时提出时还是一个end-to-end的model,是由pre-training的retrieve和generator结合,主要通过fine-tuning来提升model效果,但在2022年12月ChatGPT发布后,随着LLM的爆炸热度,RAG迎来了重要的转折点,研究热度也跟着LLM一路高涨,整个技术树历史可见下图。
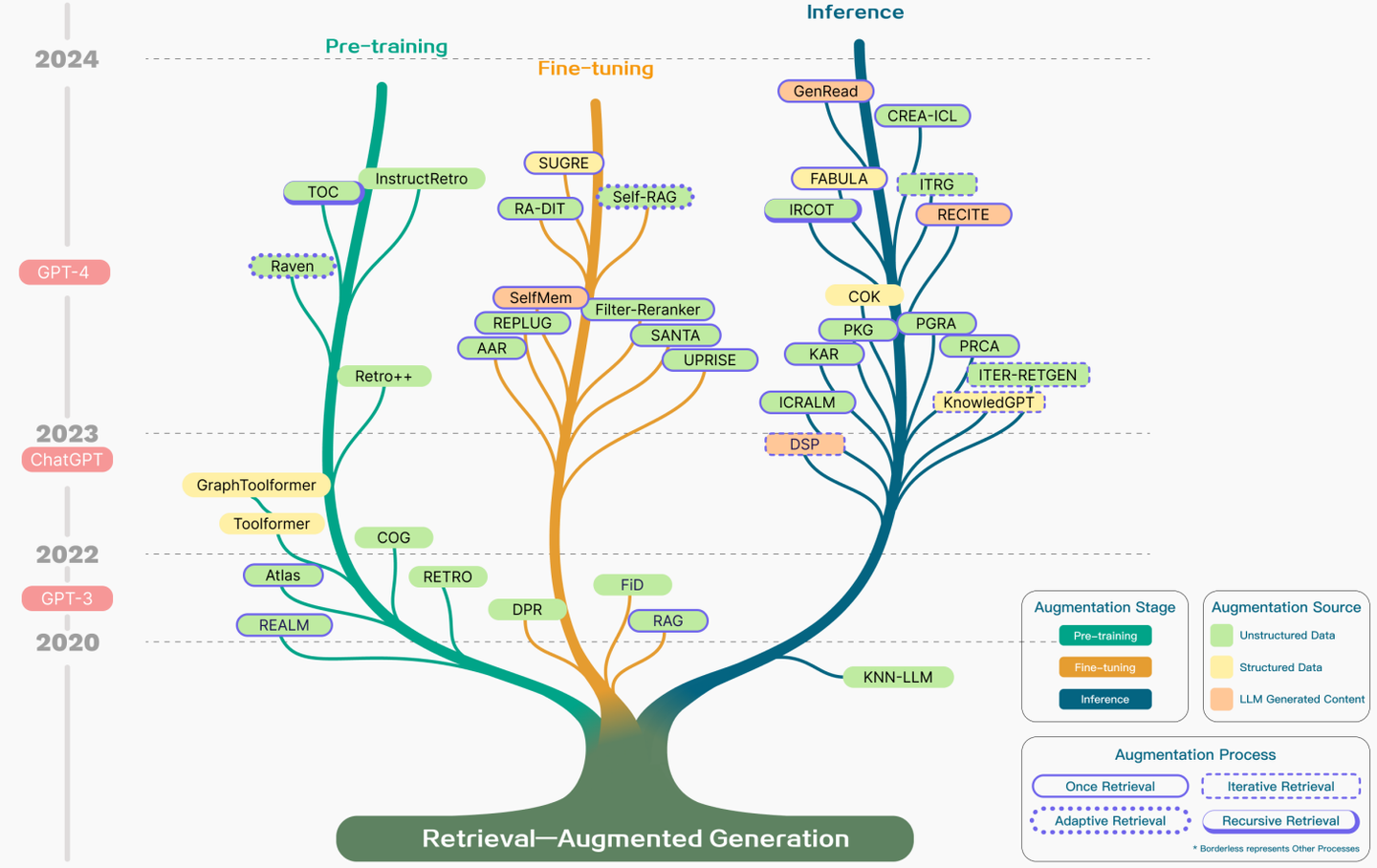
RAG技术树
在最新的review paper 《Retrieval-Augmented Generation for Large Language Models: A Survey》中将RAG技术分为三类:Naive RAG、Advanced RAG、Modular RAG,它们分别进阶代表着不同技术复杂度的RAG。
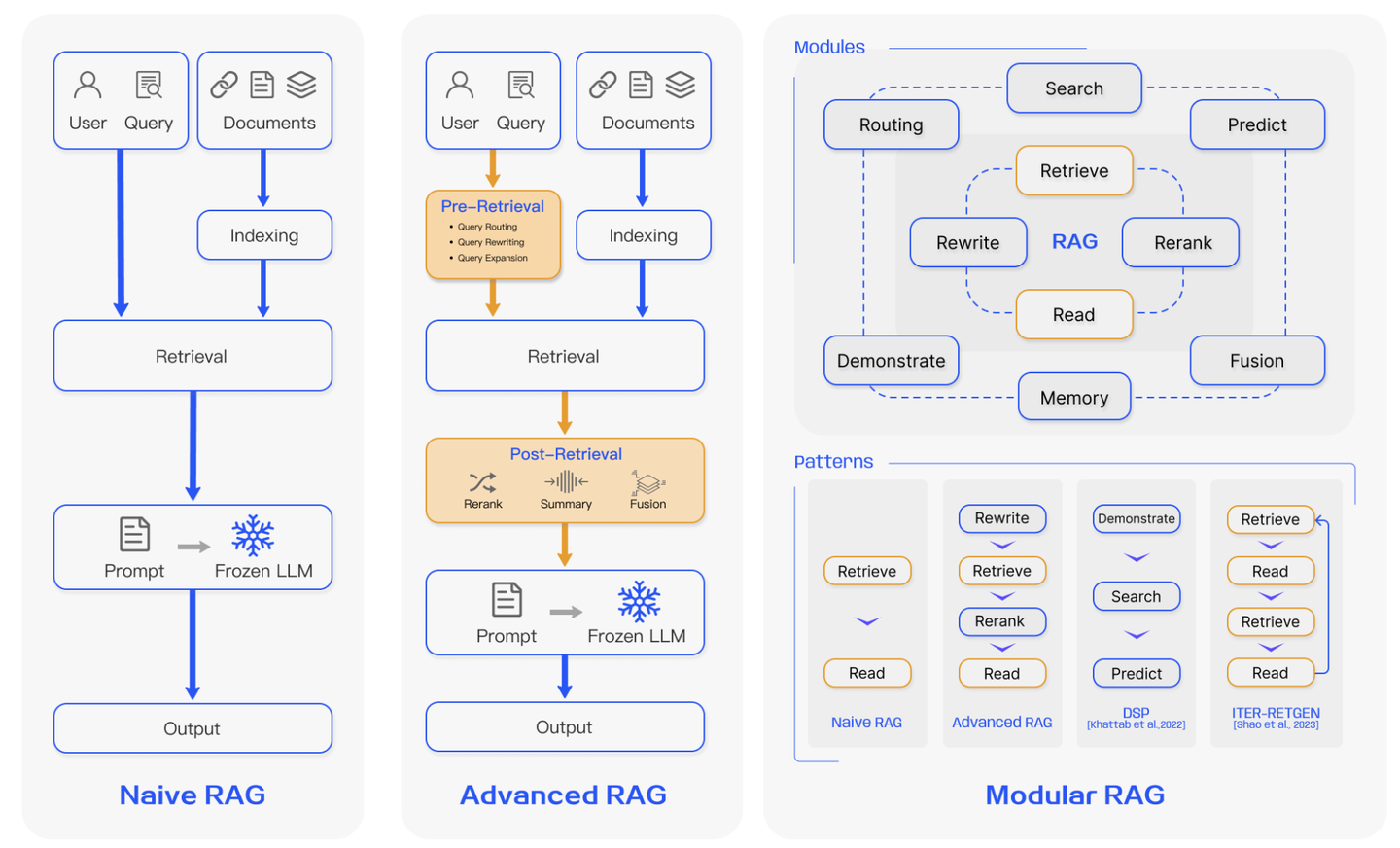
3 技术细节
下面几个图给出了一个较为简单的技术核心步骤。
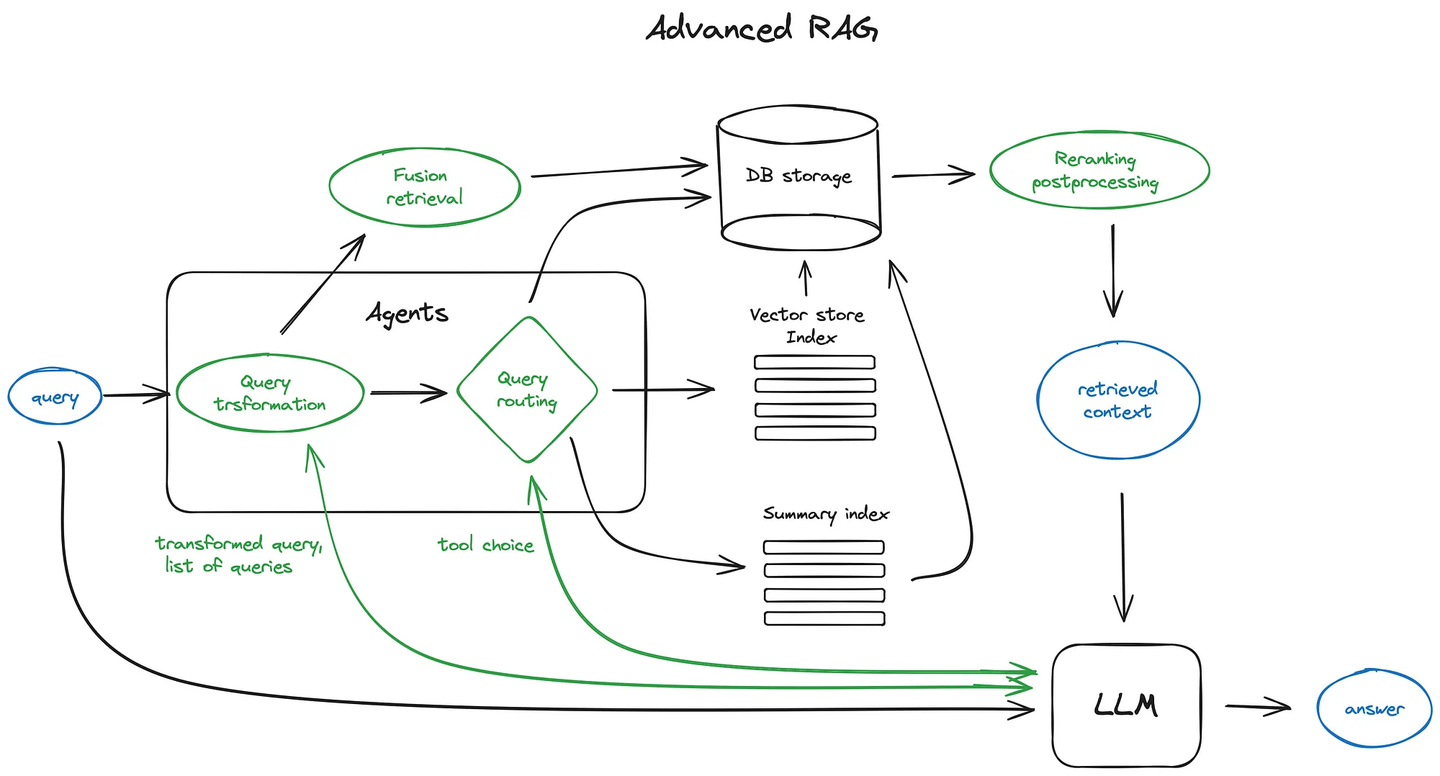
3.1 数据清洗
数据的清洗主要是针对document的预处理,包括文本提取、超链替换、脏数剔除等等。e.g. 获取知识库的原始document格式很多,有doc、ppt、excel、pdf等等,包含的信息也是多模态的,要对其中的图文混排、标题段落、表格、图片、结构数据等进行处理,若只是单纯抽取文本就很容易丢失其它模态信息,也会丢失文本结构信息,导致document知识内容碎片化以及不完整,因此如何在最开始对数据进行清洗是需要仔细考虑的工作且有着不小的工作量。
3.2 Vectorization和Chunk
vectorization的意义在于创建vector索引来表示document语义信息,在检索时候能找到语义最相近的文本。由于transformer encoder有固定尺寸的输入,那么就需要对documents切分成chunk来处理。对于如何进行chunk切分来保持语义信息,里面是着有诸多细节值得探讨,e.g. 如何定义分割器、处理元数据、处理chunk之间关联、如何体现文本中标题重要性、如何保证chunk的topic语义显著性等等。而且还涉及chunk size选择问题,而这个参数主要是决定于选取的embedding model及其token容量,而embedding model的选取又基本上都是transformer encoder,大都是搜索优化的model,e.g. bge-large等等。
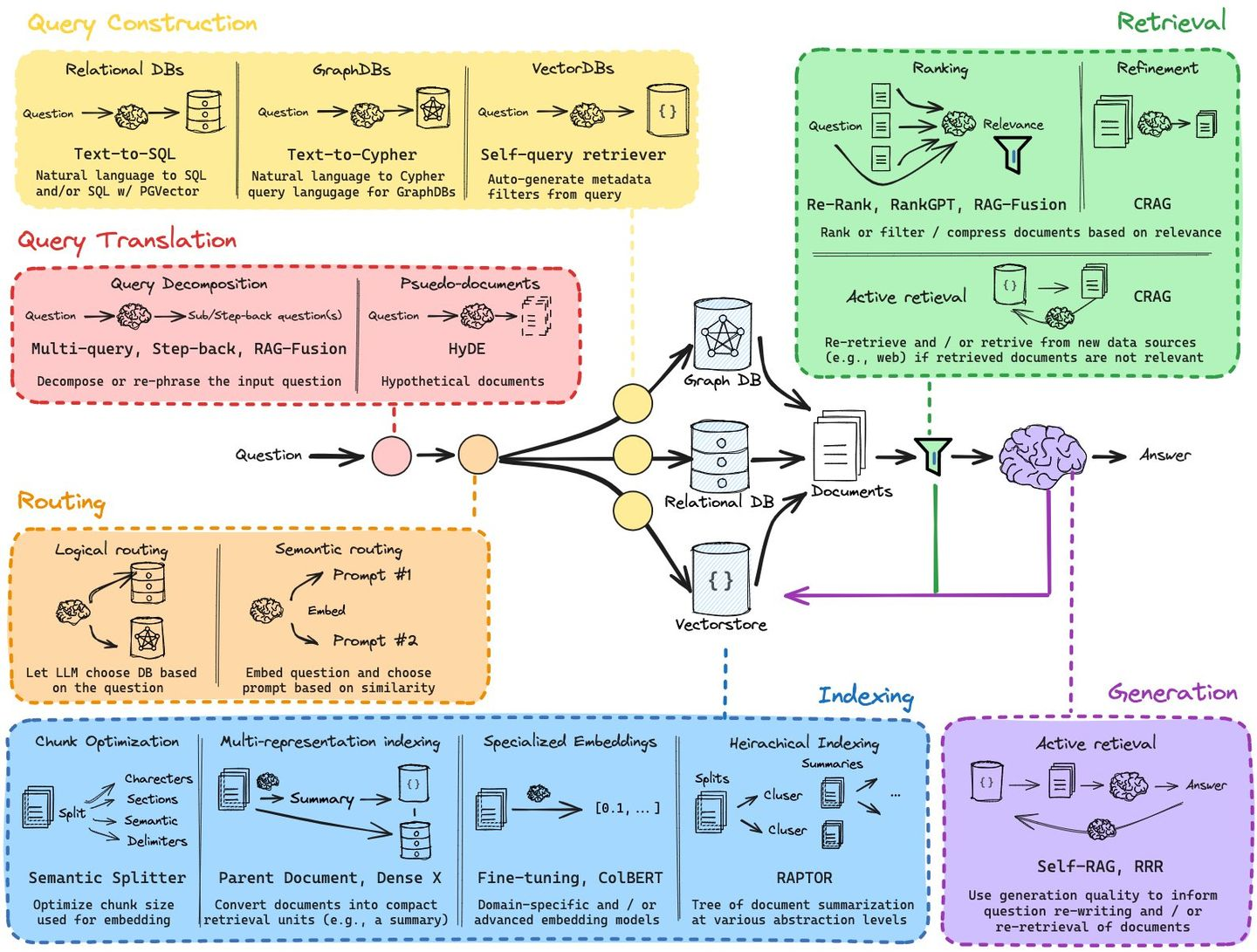
3.3 Search index
如何对前面存储chunk的VectorStore进行索引,最简单的思路就是一个平铺索引,在query embedding和chunks embedding之间进行遍历计算距离,但这种方法效率低,在面对大量数据时就不行了。因此要更换搜索策略,需要对在大型VectorStore中进行检索优化,e.g. 链式索引、树索引、图索引等等,而在faiss,nmslib和annoy等中也使用一些近似最近邻方式实现,如聚类、树或HNSW算法来处理。在LlamaIndex框架中支持许多向量存储索引,也支持其他更简单的索引实现,如列表索引、树索引和关键字表索引,当然如何更好的在VectorStore中进行vector索引,这些更多的就是具体工程实现问题了。
对于提高搜索效率,有一些trick可以使用,一种方法是通过LLM为每个chunk反向生成一个query,并将这些query变换成embedding,在正常运行时执行query和chunk生成query的embedding运算,然后再routing回原始chunk上找到对应文本,这种方法的motivation是认为query之间的语义相似性是高于query于chunk之间的,通过这种逻辑思路提高了搜索质量。
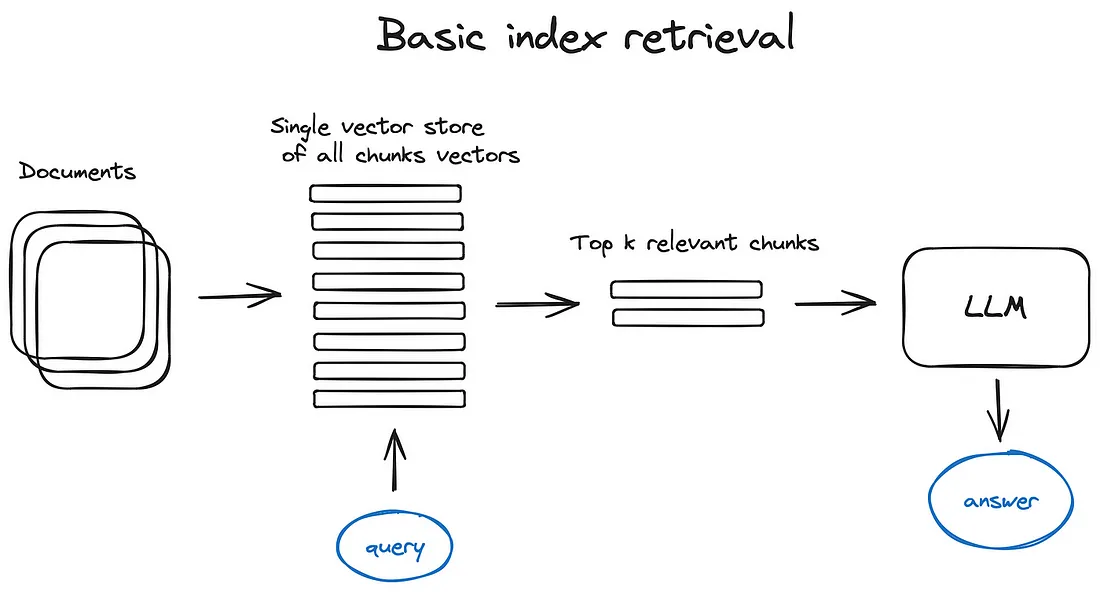
Hierarchical index retrieval:
对大型数据库中许多document进行chunk,可以考虑采用分层索引的方法,创建两个索引,一个由summary documents组成,另一个由document chunks组成,然后分两个步进行搜索,首先通过summary粗滤掉相关document,然后再对相关document chunks进行细搜索。
Sentence window retrieval:
如何获得更高质量的chunk是一个尤为重要的问题,需要让LLM获得更完整的语义信息,那么就需要丰富context信息,通过添加chunk周围更多context文本灌给LLM,目前有两种思路,一个思路是sentence窗口检索,即在检索到的chunk周围按sentence展开context,document中的每个sentence都是单独embedding,文本上的距离也在一定程度上决定了每个sentence的的高度语义相关性,在获得chunk对应的sentence后,将对应的context窗口扩展成k个sentence,再将扩展的context传给LLM。

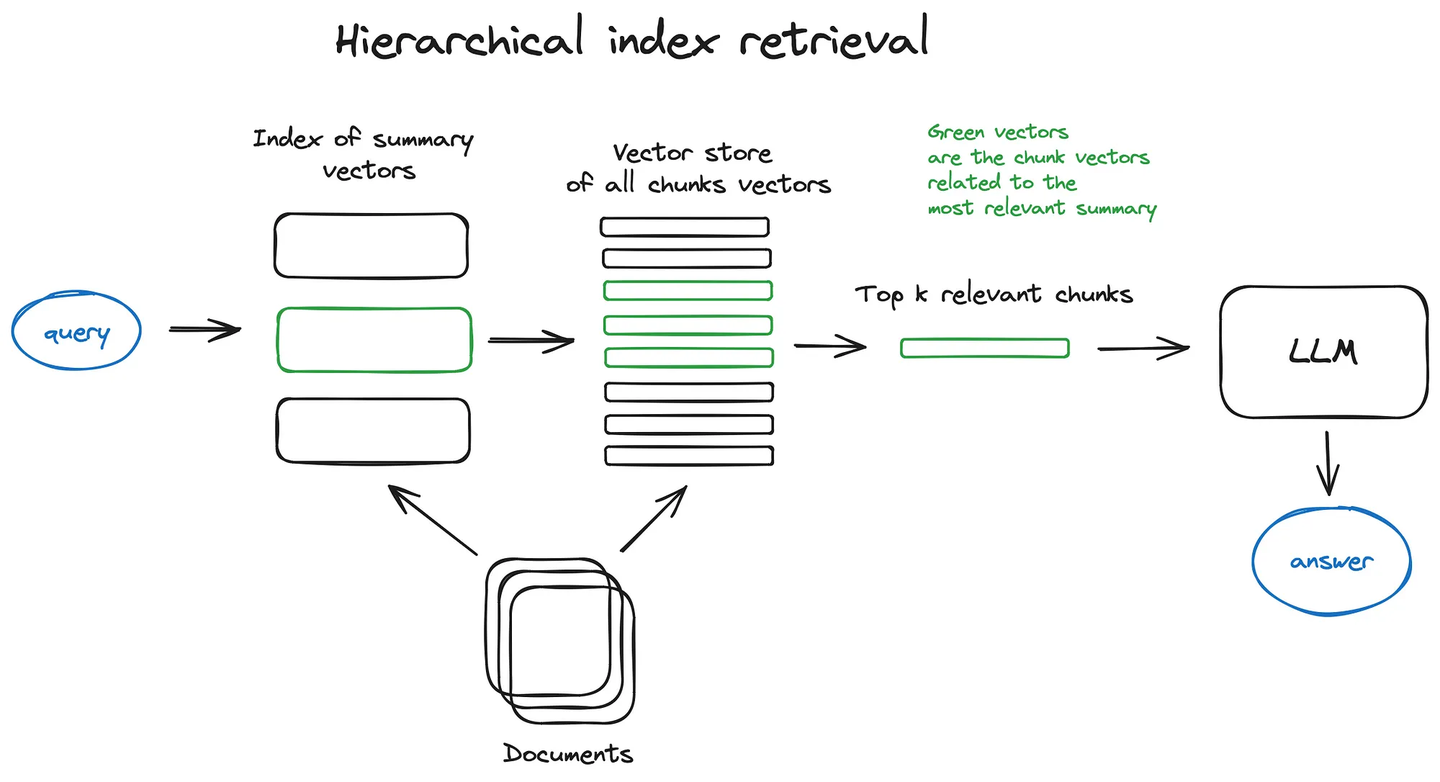
Parent-child chunks retrieval:
另一个思路是父chunk检索,也叫自动合并检索,即递归地将document分割成若干较大的父chunk,其中包含较小的子chunk,能搜索更细粒度的信息,将document分割成层次chunk结构,最终索引的是叶子chunk的embedding,将top-k结果中超过n个叶子chunk的父chunk进行替换,以获得更完整的文本语义信息。
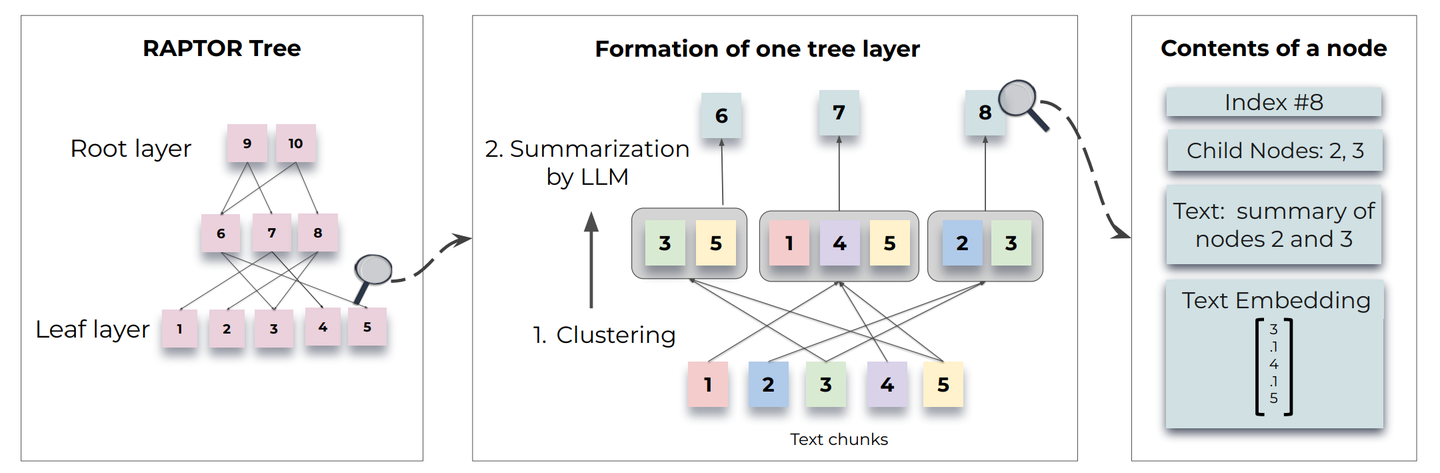
RAPTOR
另外Stanford最近提出一种新的树层次检索:RAPTOR,针对解决当前chunk方法限制了RAG对于整个document的理解,因此对文本chunks采用了recursively embedding、clustering、summarizing操作,自下而上构建具有不同summarization的分层次树结构,inference时,RAPTOR通过采用树遍历或折叠树,在不同抽象级别聚集冗长document中的信息,从而提升性能,使得检索性能更佳,报告结果显示该方法相对其它方法有着20%的性能提升。
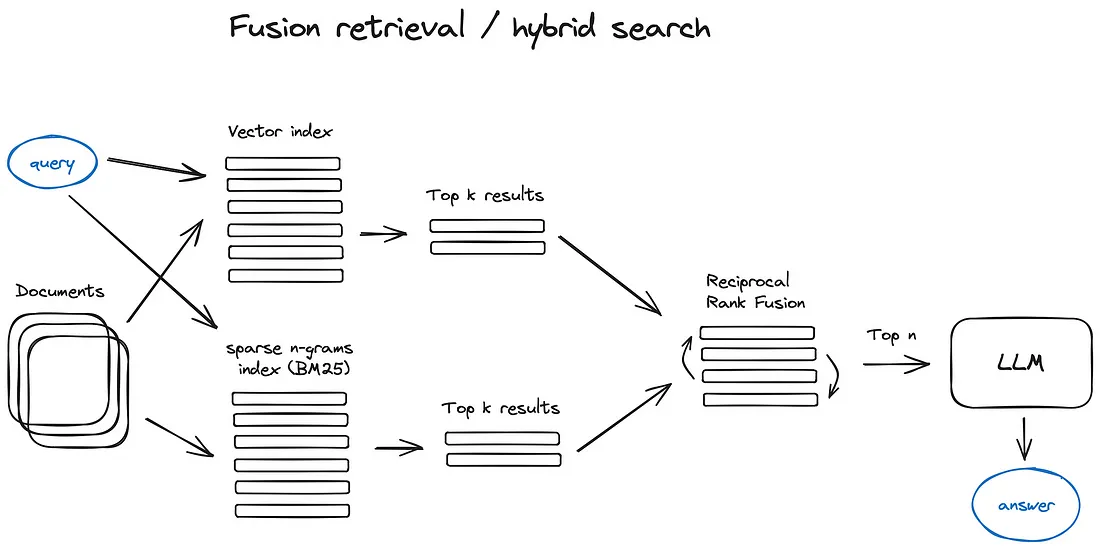
Fusion retrieval:
除了上面这些基于DL的检索方案之外,实际像经典的统计学检索方法TF-IDF和BM25这些稀疏检索算法也仍然有使用,在语料稀缺的垂直领域下甚至更为简单和高效,这种混合搜索策略能从互补的角度去recall chunk,基于DL方法从语义上recall,基于稀疏检索方法从关键字和文本上recall,然后将多路recall结果进行融合,弥补各自的优势和不足,能够提高整体的检索准确性和效率。而在这种多路recall方法的最后一步常常使用Reciprocal Rank Fusion(RRF)算法对每个chunk在不同recall方法中的排名进行加权求和,来解决不同路不同相似度之间score的融合问题,计算得到融合后的总score。
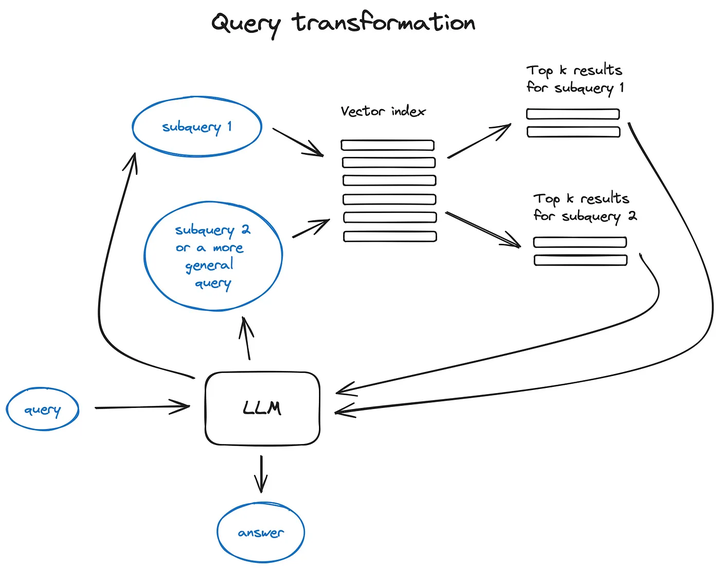
3.4 Query transformation
query transformation:
在使用query进行数据库检索时,如果想得到更好的检索质量就不能仅仅很简单的把query直接扔给数据库,如何提高对未知query输入后的variability robust,那么就需要进行query transformation以提高query的检索质量。经常使用方法是引入LLM作为inference engine进行query transformation,e.g. 将复杂的query利用LLM分解成几个sub-query,以transformation成更有意义的细粒度query,更方便在语料库进行检索,同时还可以将分解得到的sub-query进行并行运算提高效率,再在最后把分别检索到的context进行组合成prompt输入给LLM。
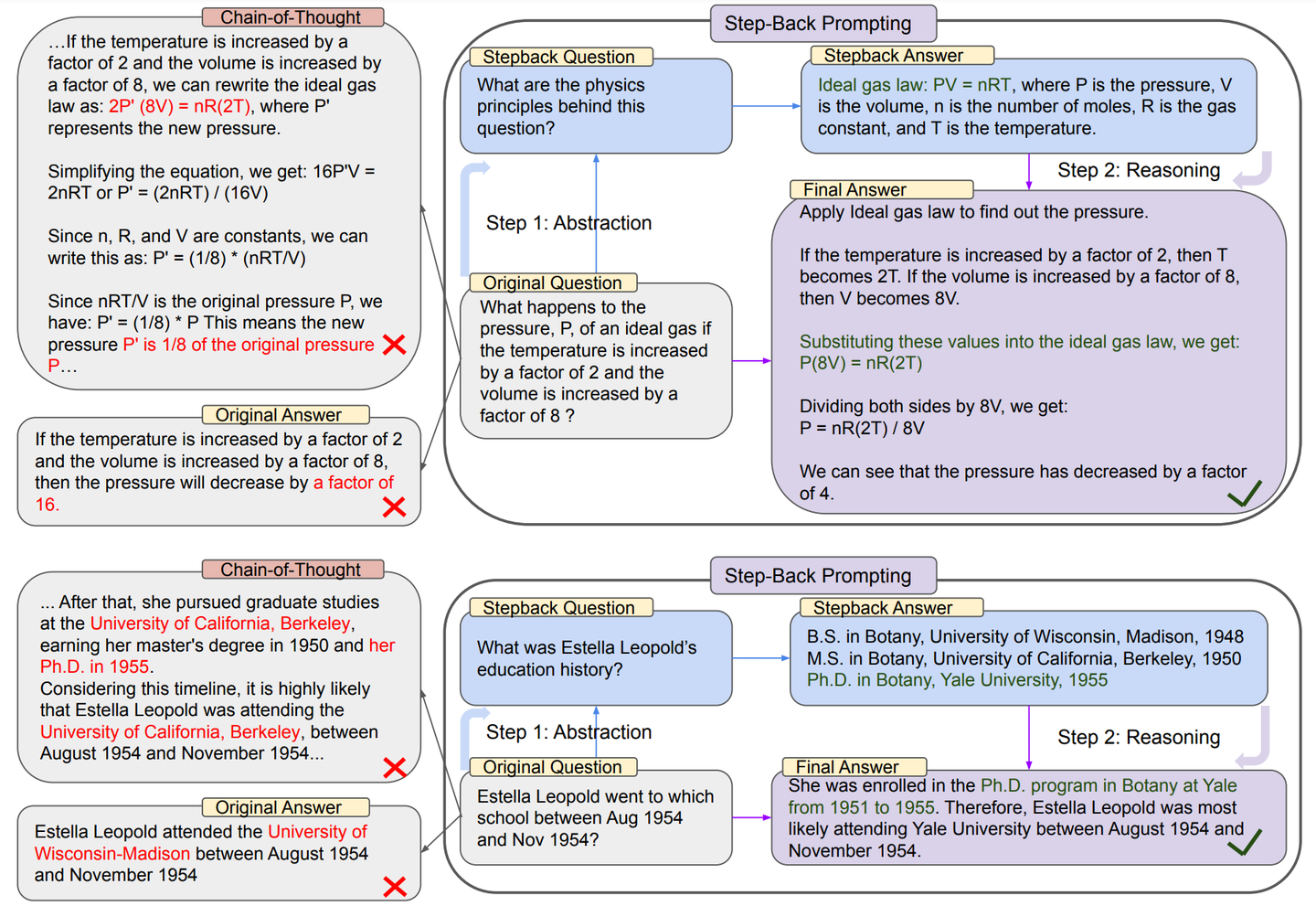
Step-back prompting:
此外还有一种Step-back prompting的方法,除了原始query的检索结果之外,还通过利用 LLM 生成一个更宽泛的query检索得到更高层次的context,然后将两个context融合得到包含不同层级信息的context提供给LLM。此外利用LLM进行query重写以改善query质量,以及将query对话context进行压缩也是不错的方法。
此外在系统中还有一个概念是参考引用,即在对于RAG我们需要准确地回溯response的来源document id是哪个,那么就需要系统支持这项能力。目前下面几个思路可以做到这一点:
- 将引用任务插入我们的prompt中,并要求LLM提及使用的来源的id。
- 将生成的response部分与我们索引中的原始文本chunk匹配,然后反向找到id。
3.5 Filtration和Re-Rank
在得到了检索结果后,还需要通过filtration和re-rank,因为大多数VectorStore为了计算效率会牺牲一定程度的准确性,这使其检索结果存在一定随机性,原始返回的top-k不一定是最相关的,因此需要得到相关度更高、更准确的知识chunk。对于filtration和re-rank有多种可用的后处理方法,e.g. 可以根据相似度score、关键词、元数据来filtration掉结果,或者用cross-encoder model对结果进行re-rank,以及根据元数据内聚re-rank等等,都可以得到最终context。
3.6 Chat engine
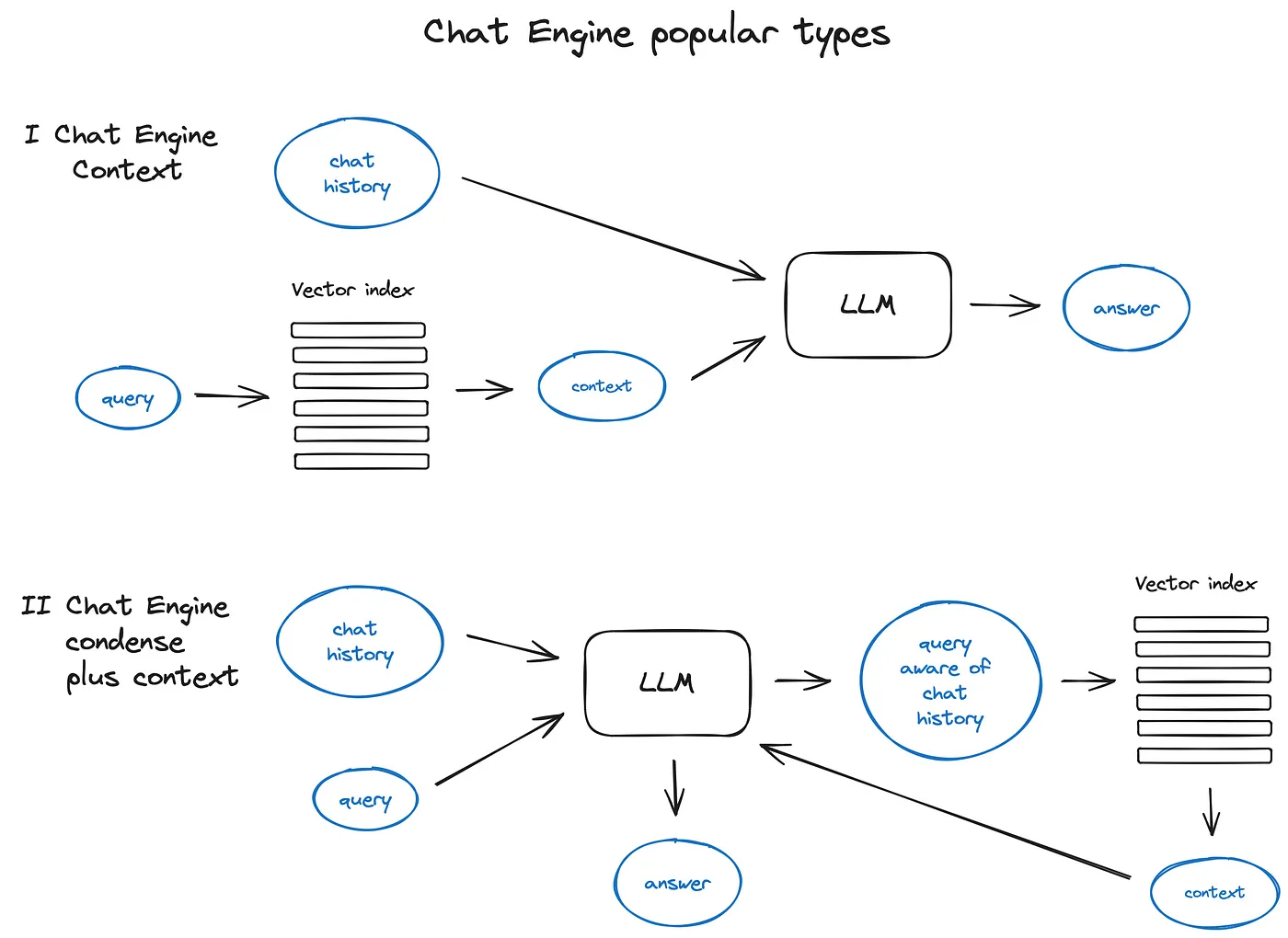
优化对话逻辑是RAG系统在用户感知方面很重要的东西了,需要系统能感知到用户对话内容的context信息,那么驱动这种上下文对话引擎的方法有两种简单有效的方法,一个是ContextChatEngine将历史对话存放在系统缓存中,在每次对话时都读取历史对话从缓存与query检索到的context和query信息一起送给LLM,由LLM总结归纳得到response。另一个方法是CondensePlusContextMode,它在建立历史对话缓存上与第一个一致,但是不同的是将历史缓存信息和query送给LLM压缩得到新的query,再进行检索,检索得到的context和query传递给 LLM生成response。
3.7 Query routing
Query routing是由 LLM 驱动的决策步骤,在给定用户query的情况下,来决策下一步操作,通常是总结、数据索引、其它routing等等,也可以用于选择索引或者数据存储等,e.g. 将query分发到vector数据库还是relational数据库更或者是graph数据库进行检索。routing选择通常是通过调用LLM来执行的,它以预定义的格式返回结果,用于将query routing到给定的索引。如果采用了agent的方式,则将query路由到子链甚至其他agent。
3.8 Agent
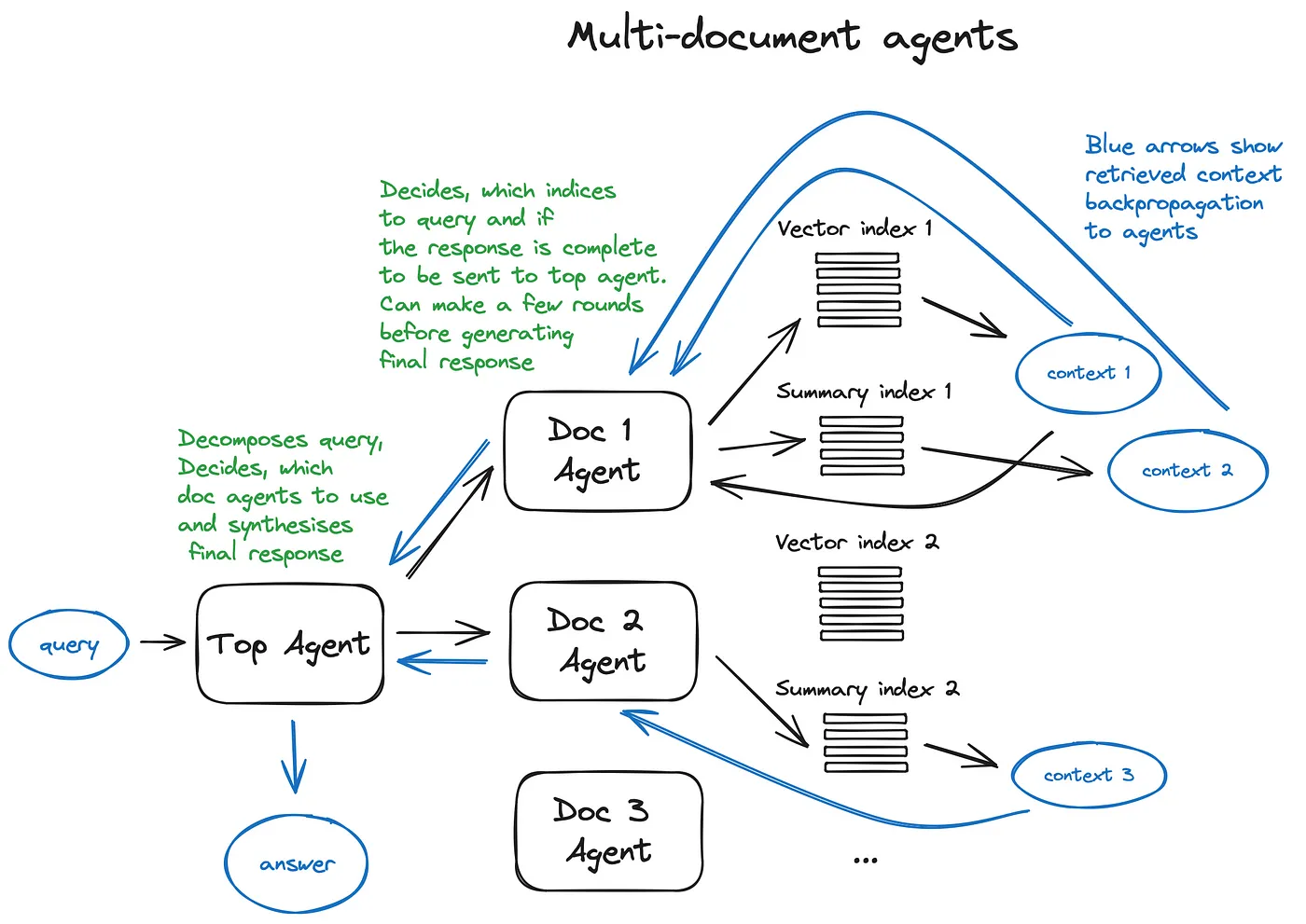
Agent是伴随着LLM诞生之初开始就一直存在的话题,如何构建一个智能agent是一个很值得研究的subject,这样的体系结构会由每个相关agent做出大量的routing决策,下面我们以multi-document agents举例来简单说下agent可以在RAG中的应用情况。
首先是针对每个document都会初始化个document agent,能够进行文本摘要和QA,以及在这些之外提供一个top agent,负责将query routing到document agent以及进行合成最终的response。每个document agent都具有vector索引和summary索引两个tools,并根据routing的query来决定使用哪个tool。该方案由于在内部使用 LLM 会进行多次来回迭代,因此速度会有点慢,所以LLM 调用通过 RAG pipeline中最长的搜索操作来优化速度,而对于大型multi-document存储,可以对该方案进行一些简化,使其系统scalable。
Multi-document agents
3.9 Response synthesiser
Response synthesiser是RAG pipeline的最后一步,根据检索的所有context和原始query生成一个答案。最简单的方法就是将所有获取的context与query一起concat提供给 LLM。但是往往没那么容易,因为还有其他更复杂的选项涉及多个 LLM 调用,以细化检索到的context并生成更好的答案。响应合成的主要方法有:
- 通过逐个chunk向LLM发送检索到的context来迭代地细化答案。
- 总结检索到的context以适应prompt。
- 根据不同的context chunks生成多个response,然后将其concat或summarize。
4 Fine-tuning
在pipeline中对涉及deep model的部分进行fine-tuning,主要包括Embedding Encode Model和LLM。
4.1 Fine-tuning Embedding Encode Model
这里的更多的是采用Transformer Encoder,通过提升embedding质量来提升检索context能力,改善语义表达,e.g. UAE、Voyage、BGE等,它们在大规模语料库上进行了pre-training,只需要对base model采用特定domain的data来优化参数即可,做到针对性处理垂类专业场景。此外对于使用sentence transformer来说,在粗粒度的recall chunk后,采取cross-encoder是个不错的选择,能对检索到的结果re-rank,虽然cross-encoder运行速度较慢且占用内存较多,但是结果却是更加准确,它的fine-tuning过程就是通过对recall的chunk结果标记分割,进行相关性二分类即可。
也可以通过插入adapter来进行model alignment,采用对pre-training model的fine-tuning来轻量级替代,一般思路是将adapter插入到pre-training model的layer之间的小型forward-NN中,位置在embedding之后和检索之前,所以fine-tuning adapter的目标是更改原始embedding质量,以便为特定任务得到更好的检索结果。e.g. PRCA在context提取阶段和reward-driven阶段训练adapter,并通过基于token的autoregressive策略来优化检索器的输出。而TokenFiltering通过计算cross-attention分数,挑选出得分最高的输入token,有效地进行token过滤。以及还有RECOMP和PKG的方法也是相似adapter策略。
4.2 Fine-tuning LLM
对于LLM的这方面处理就很多了,这是个高热度的task,相关研究paper就非常多,有LoRA、Adapters、Prefix-tuning、P-tuning以及AdaLoRA等等(后面可以出期单独讲讲LLM的fine-tuning技术)。至于dataset可以是基于高阶LLM去生成高质量的QA data,再在这个dataset基础上进行fine-tuning,以优化LLM性能。此外Meta提出的RA-DIT也是一种有趣的方法,同时去对LLM和retriever进行优化,最大化answer的正确可能性,最小化retriever分数分布和LLM偏好分布之间的KL散度。

RA-DIT
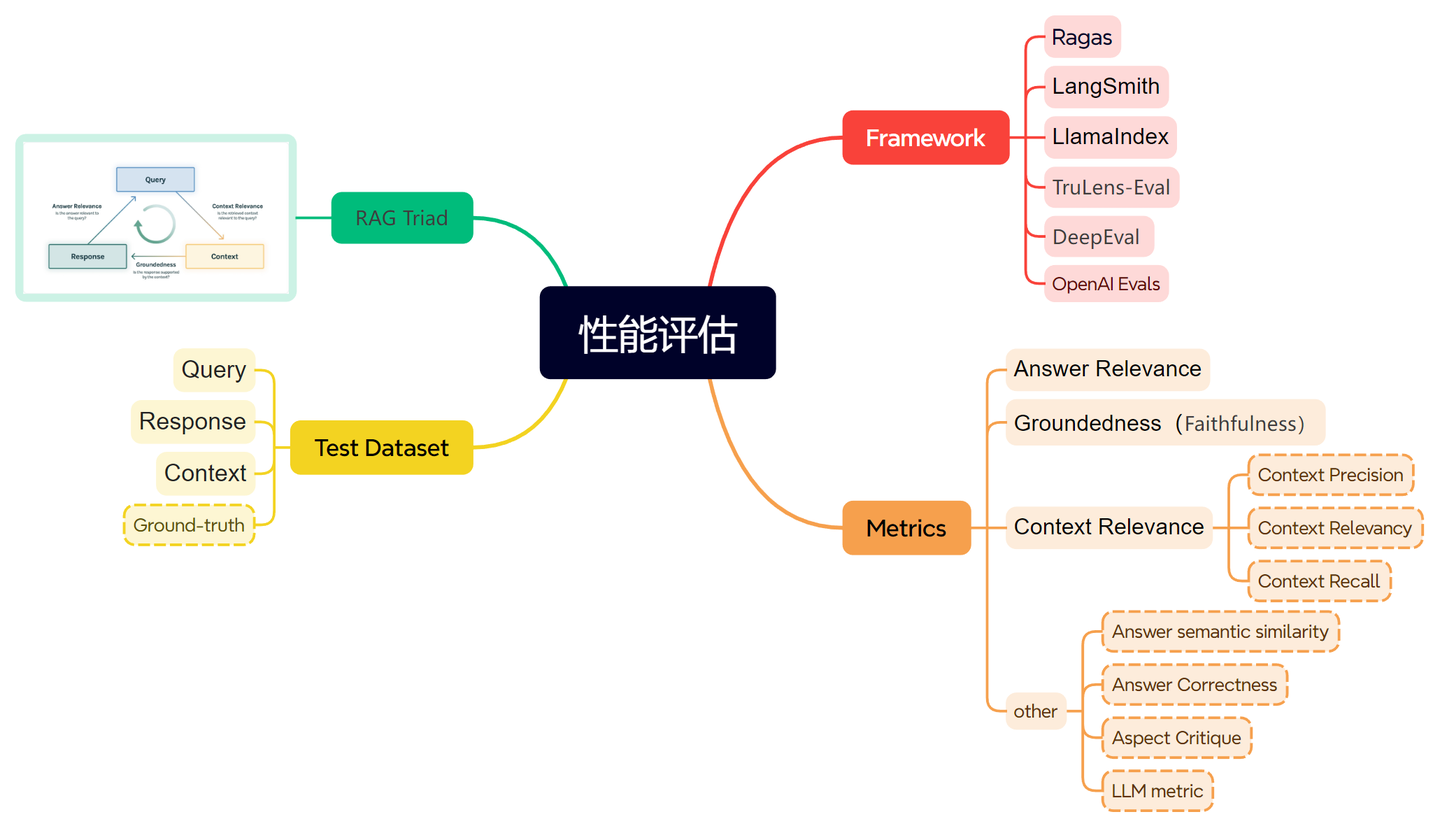
5 性能评估
能评估RAG系��统的framework还挺多,主要包括Ragas、LangSmith、LlamaIndex、TruLens-Eval、DeepEval、OpenAI Evals等等。
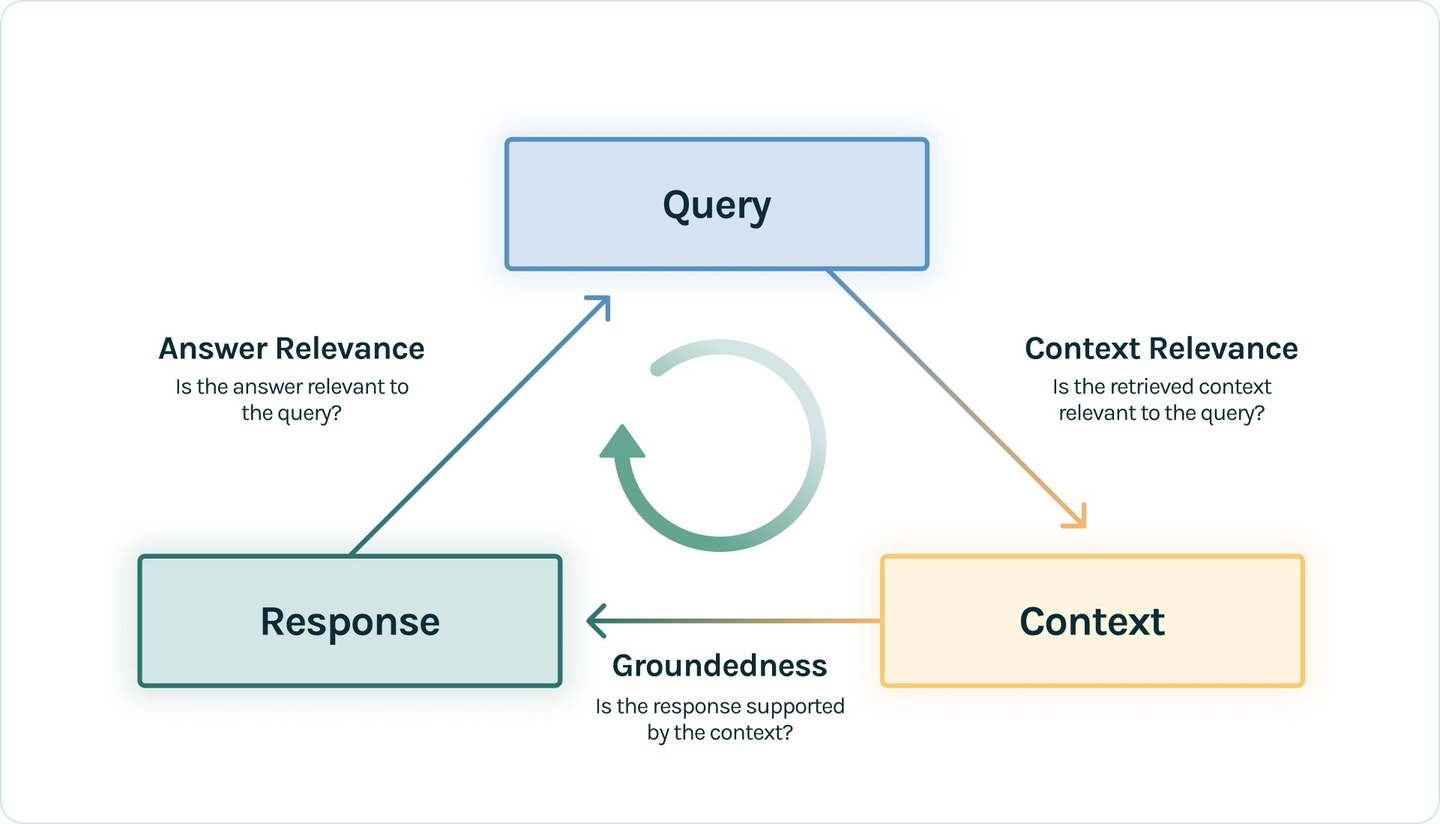
其中TruLens提出了RAG三元组,将Query、Context、Response作为三元组,构建test dataset,这种避免了基于ground-truth的评价,并将三元组之间的关联作为评估的metrics:
- Answer Relevance: 衡量Response与Query的相关度。
- Groundedness:衡量 Response 遵从recall的Context 的程度。又叫Faithfulness。
- Context Relevance: 衡量recall的Context 能够支持 Query 的程度。
RAG triad
此外在Ragas中,在三元组之外引入了ground-truth,可以是标准answer也可以是document中的chunk等等,那么在Ragas体系下也引入了新的metrics,e.g. 将前面的Context Relevance细分成Context Precision、Context Relevancy、Context Recall三者,也新引入了Answer semantic similarity、Answer Correctness、Aspect Critique等。剩下的其它framework基本就是基于这些指标进行变种,大同小异吧,但是除这些之外也还有个有趣的metric:利用LLM自身能力来评估query和response。
性能评估
6 Framework
目前有两个基于LLM的应用框架可以很容易实现RAG pipeline,分别是LangChain和LlamaIndex,它们都是为了简化LLM应用开发而出现的工具链,LangChain是使用LLM开发应用程序的通用框架,而LlamaIndex是专门用于构建RAG系统的框架,对于前面提到的技术细节部分在各自Github仓库都有源码实现(后面抽空看看他们源码学习下),大家可根据具体的业务需求、易用性考虑以及个人熟悉程度来选择适合的框架。
- Langchain ️
- https://github.com/langchain-ai/langchain
- LlamaIndex
- https://github.com/run-llama/llama_index
7 Trick
除了前面细节部分提到很多trick之外,这里我们再补充一些trick。
CMU提出了一种HyDE的反向逻辑方法,主要去做zero-shot场景下的稠密检索,即对于query通过LLM生成虚构的response,然后对其进行encode,将它和query的embedding一起用于在语义空间检索,基于最近邻从语料库中找到相似的chunk,提高搜索质量。它的motivation是希望去检索看起来更像答案的document,感兴趣的是它的结构和表述,所以可以将虚构的response视为帮助识别embedding空间中相关邻域的template。
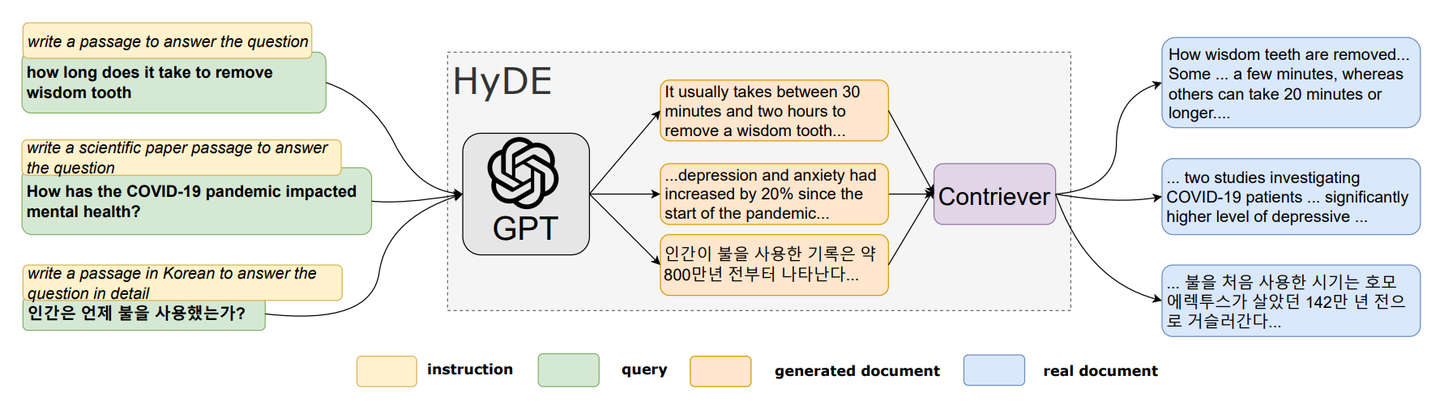
HyDE
RAG-Fusion,对query进行扩展,利用LLM生成与原始query相关的N个query,将他们一起全部发送进行检索,这样可以从VectorStore中recall更多chunk。它的motivation是针对对于不完整以及不明确的原始query,通过扩展的方式去recall更多可能相关和互补的结果,但是这样也会引入更多重复和冗余的chunk,因�此就需要后面进行Re-Rank和filtration。
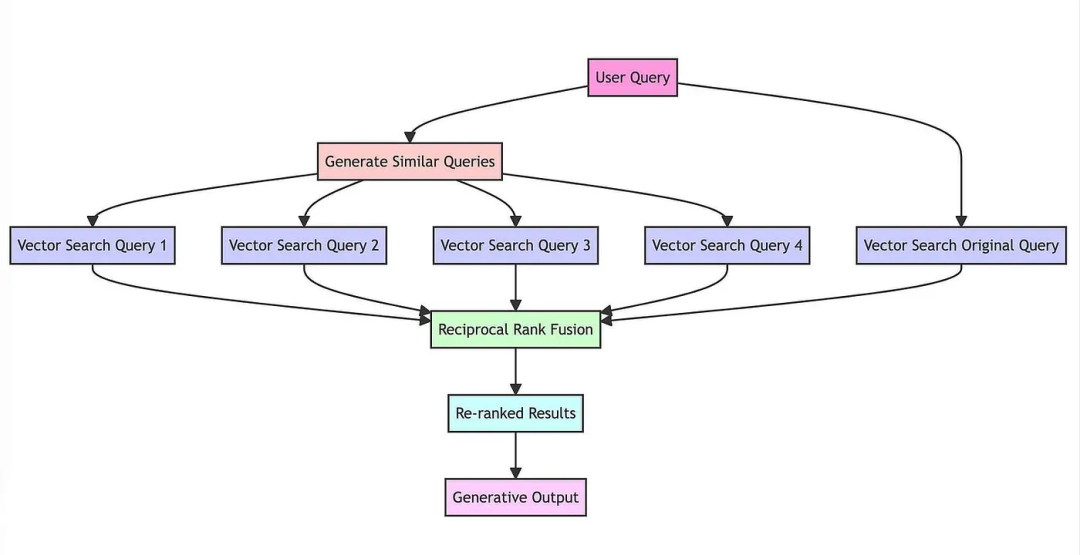
RAG-Fusion
此外除了利用LLM重写query,也可以重新去train一个rewriter来保证更好的效果,首先利用LLM对原始query生成N个新query,在数据库中recall更多chunk,进一步的为了使得将query与frozen module对齐,利用small-LM作为rewriter,通过LLM的离散反馈信息利用RL技术来持续迭代优化rewriter。
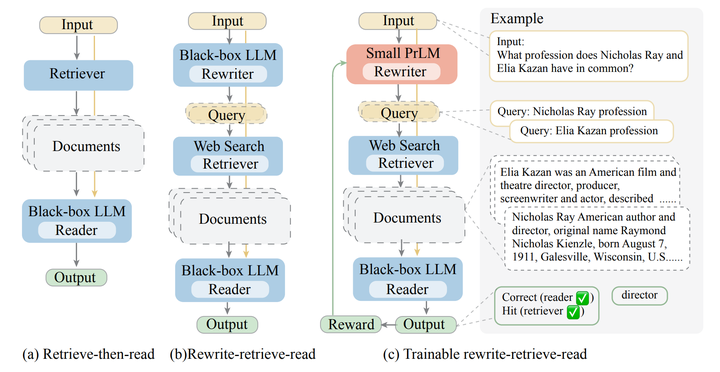
Rewrite-Retrieve-Read
如果用户的query信息过于偏离,model是难以理解用户intent的,那么仅仅靠RAG Fusion也难以从根本上去解决这个问题,因此可以在系统中通过添加追问机制,对LLM添加prompt信息,让model自行判断是否需要对用户进行追问逐步引导用户的query走向正常。
8 新的研究
这里提供下综述paper中一个很好的技术图和两篇最新的paper信息扩展下。
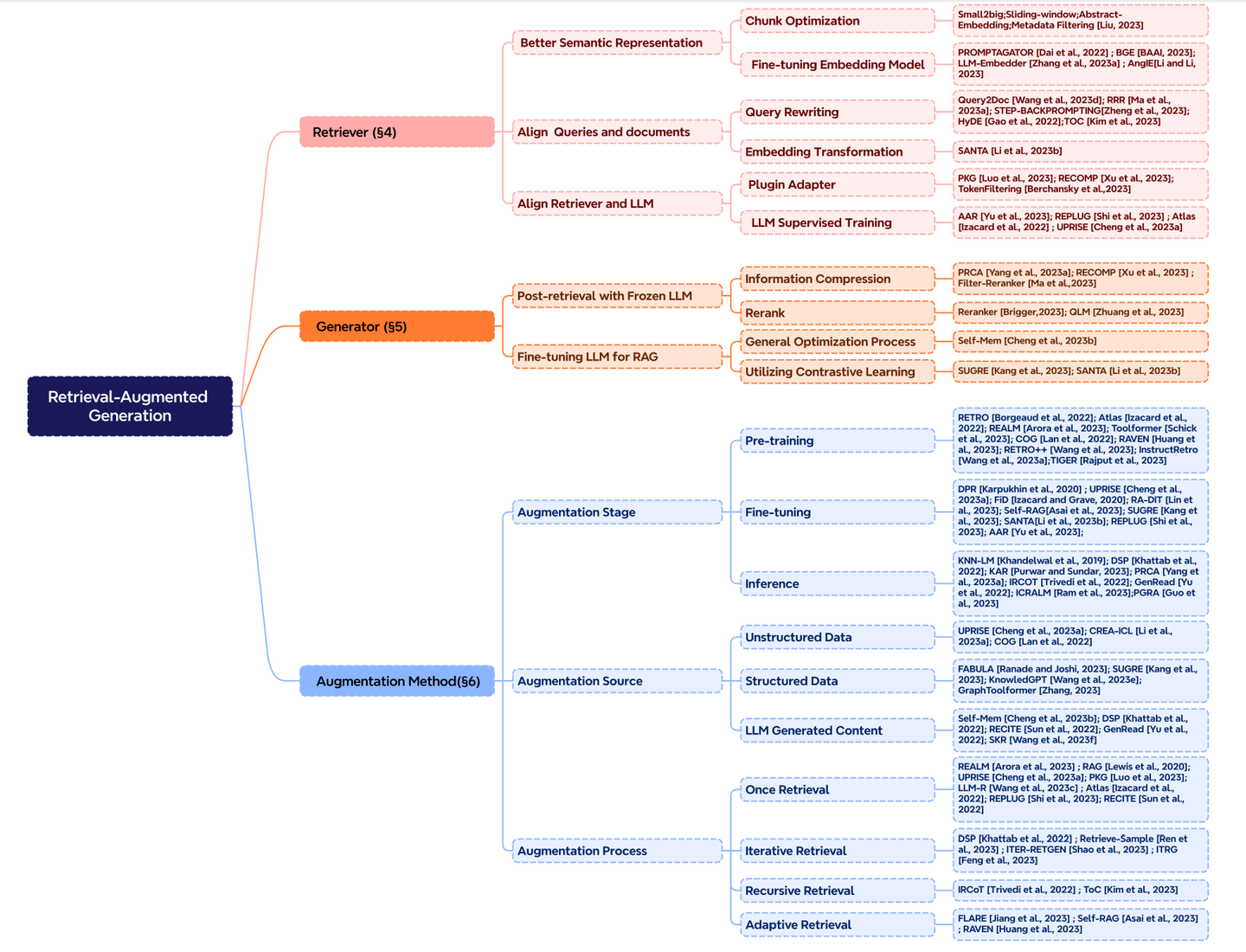
RAG技术图
《G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering》提出的G-Retriever旨在处理现实世界文本graph任务,如场景graph理解、常识推理和知识图谱推理。该模型结合了GNN、LLM和RAG,通过软提示进行fine-tuning以增强graph理解。G-Retriever通过将任务构建为奖赏收集斯坦纳树优化问题,解�决了LLM的幻觉问题,并可扩展至大型graph。
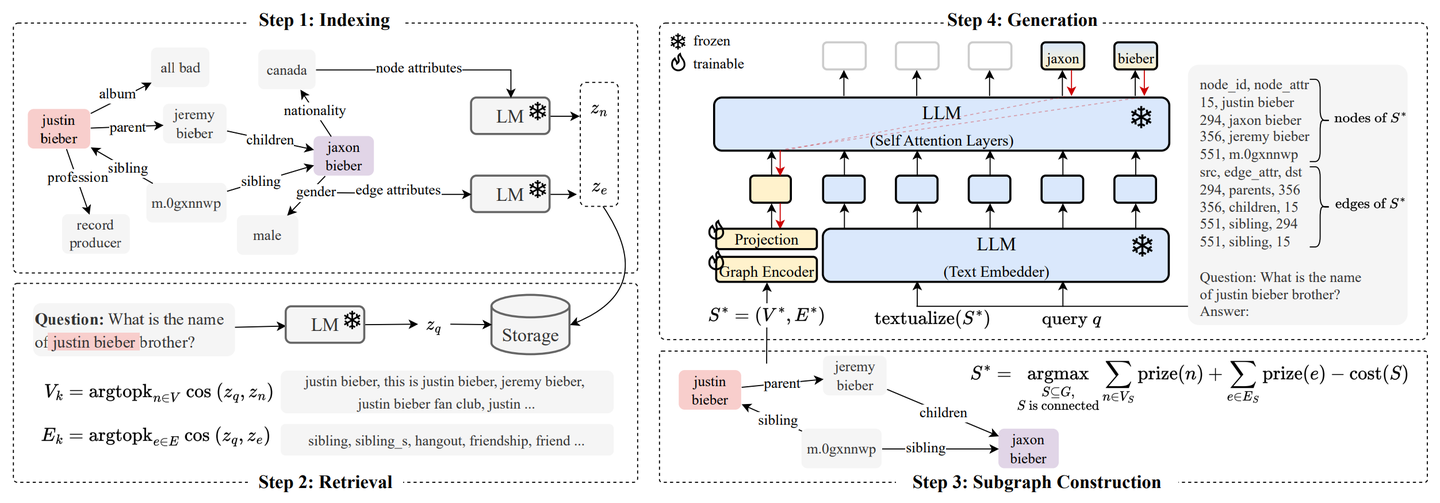
G-Retriever
《Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection》提出的Self-RAG通过检索和自我反思来提高LM的质量和真实性,LM自适应地按需检索段落,自主决定对当前query是否需要recall,把recall内容拼接进输入,再生成一段下文,自主判断recall文档是否与输入问题相关、自己借此生成的一段下文是否合理、是否有用,对recall的top-k 内容进行排序,把 top-1 加进最后的输入以尽量生成正确答案。
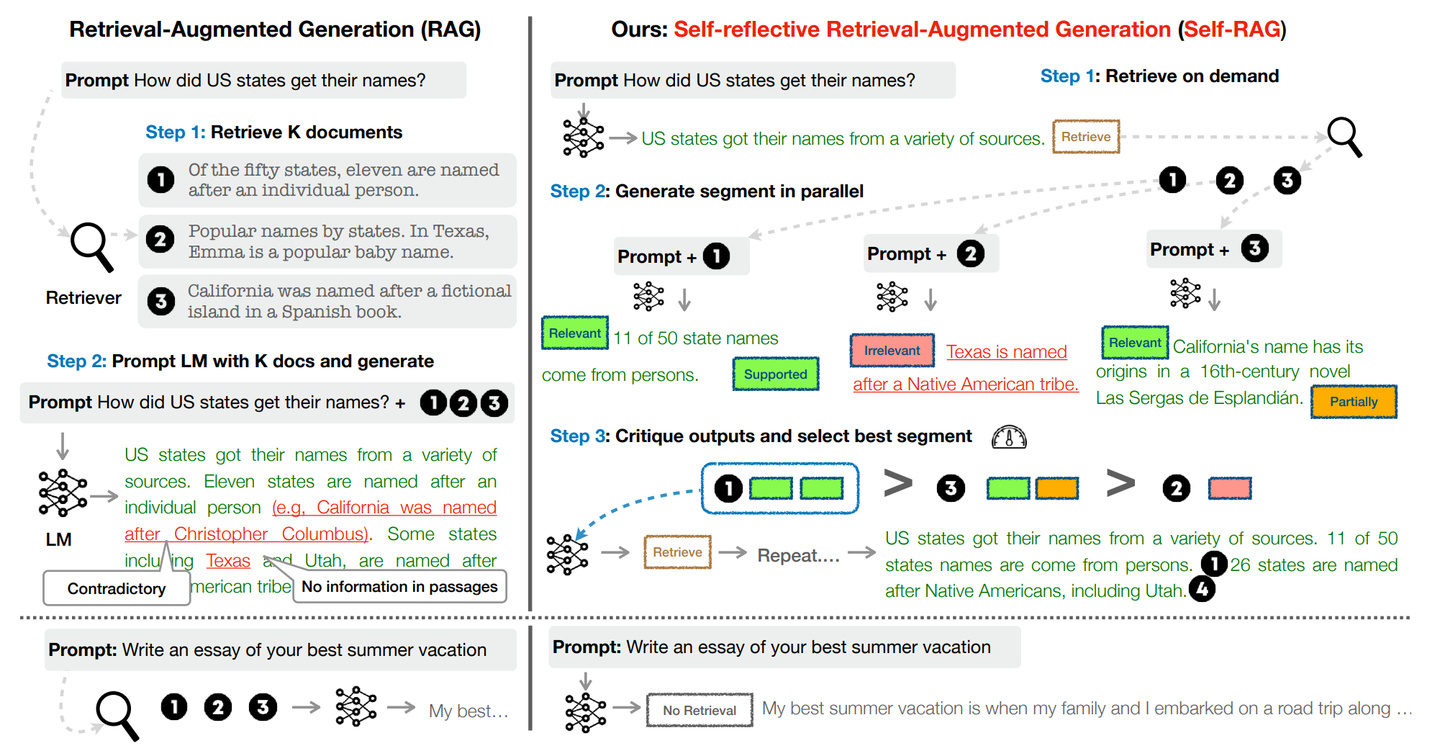
Self-RAG
9 结束语
关于RAG还有很多细节部分可以探讨,目前RAG技术仍然还在快速发展中,去年一年已经涌现了很多新思路出来,商用落地也还没有完全技术收敛,所以对RAG来说任重道远,对我来说我挺看好RAG在multimodal domain的扩展,以及与Agent架构的深度融合。最后给出一张RAG的整体图和两张RAG的技术细节问题图,挺值得学习和思考。
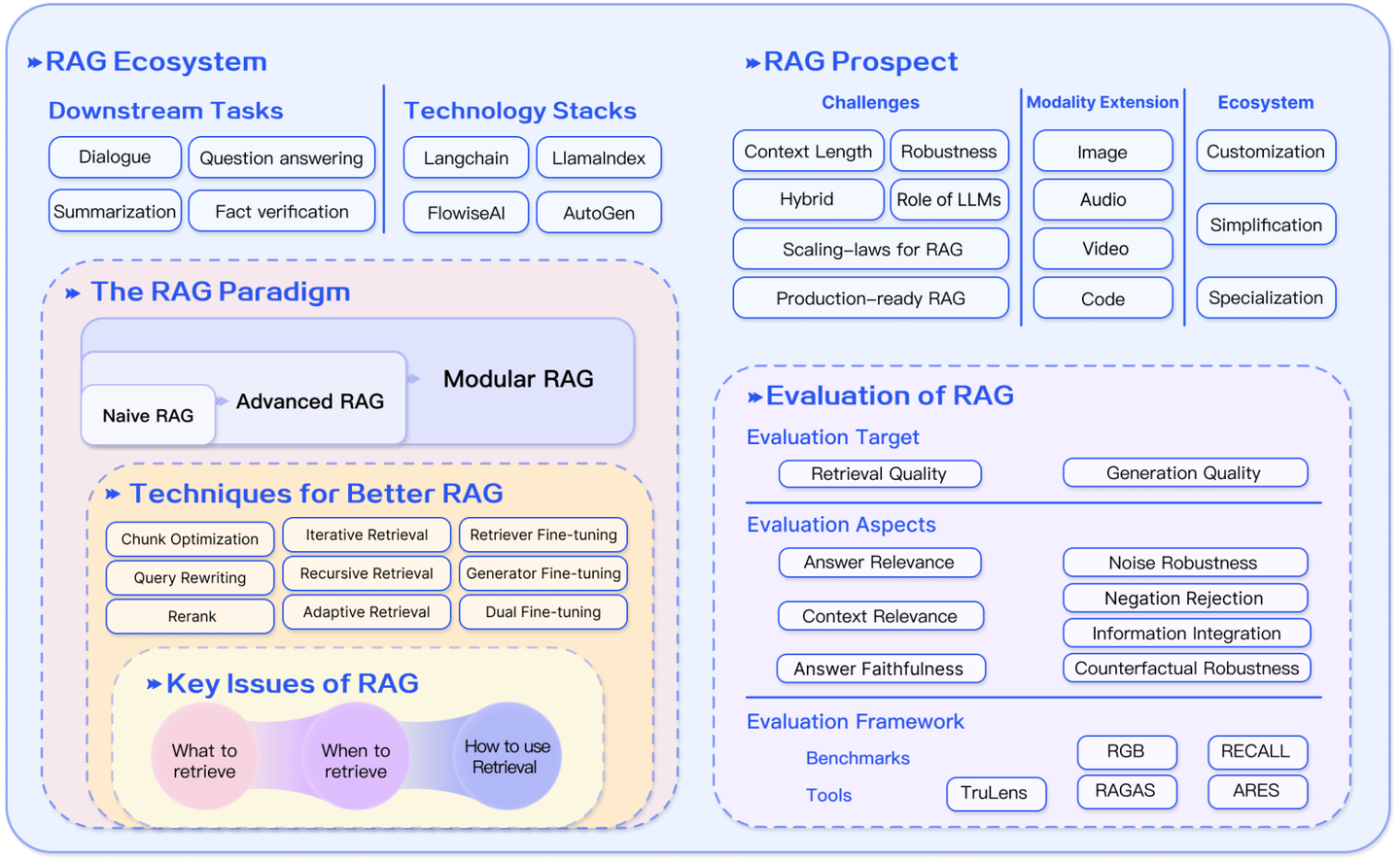
RAG
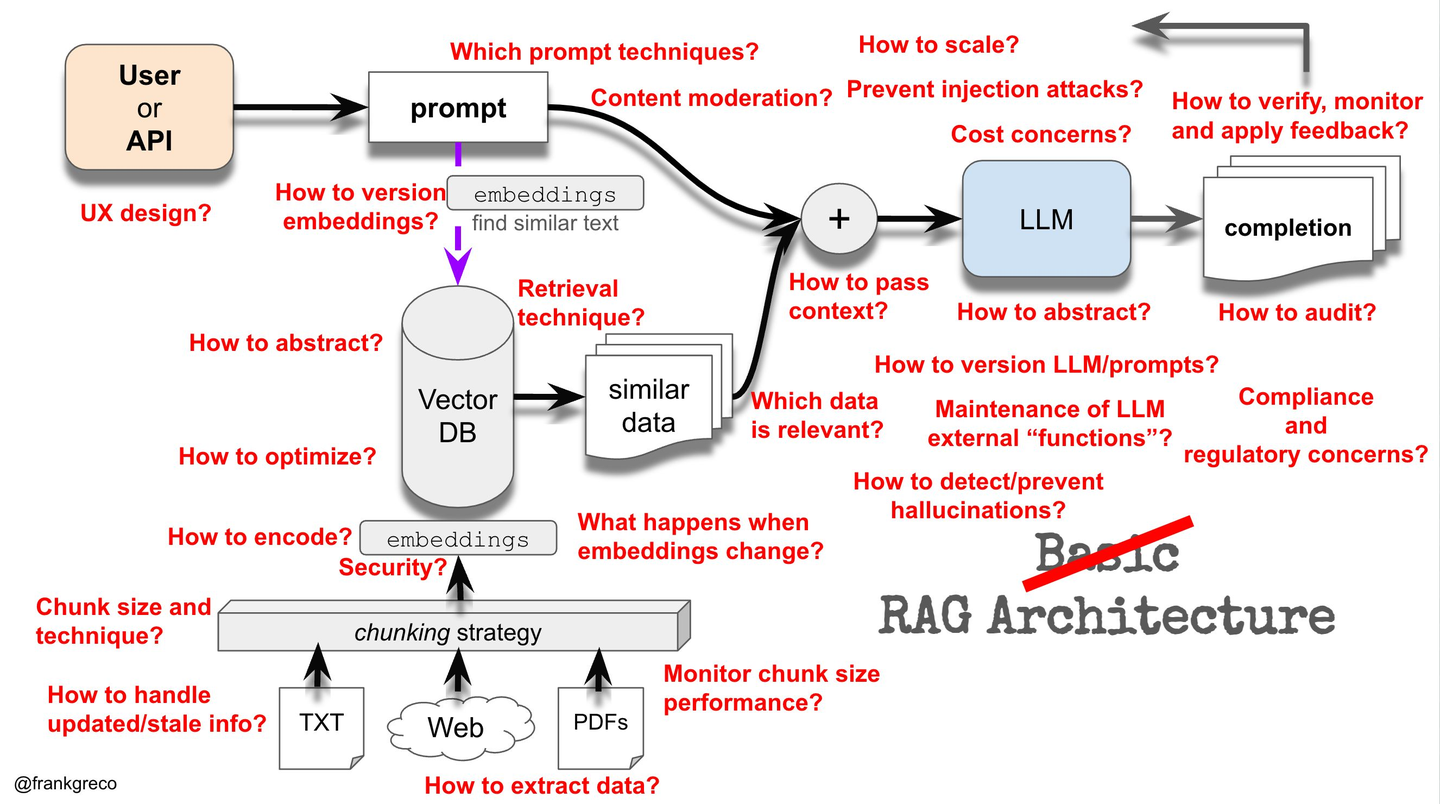
RAG
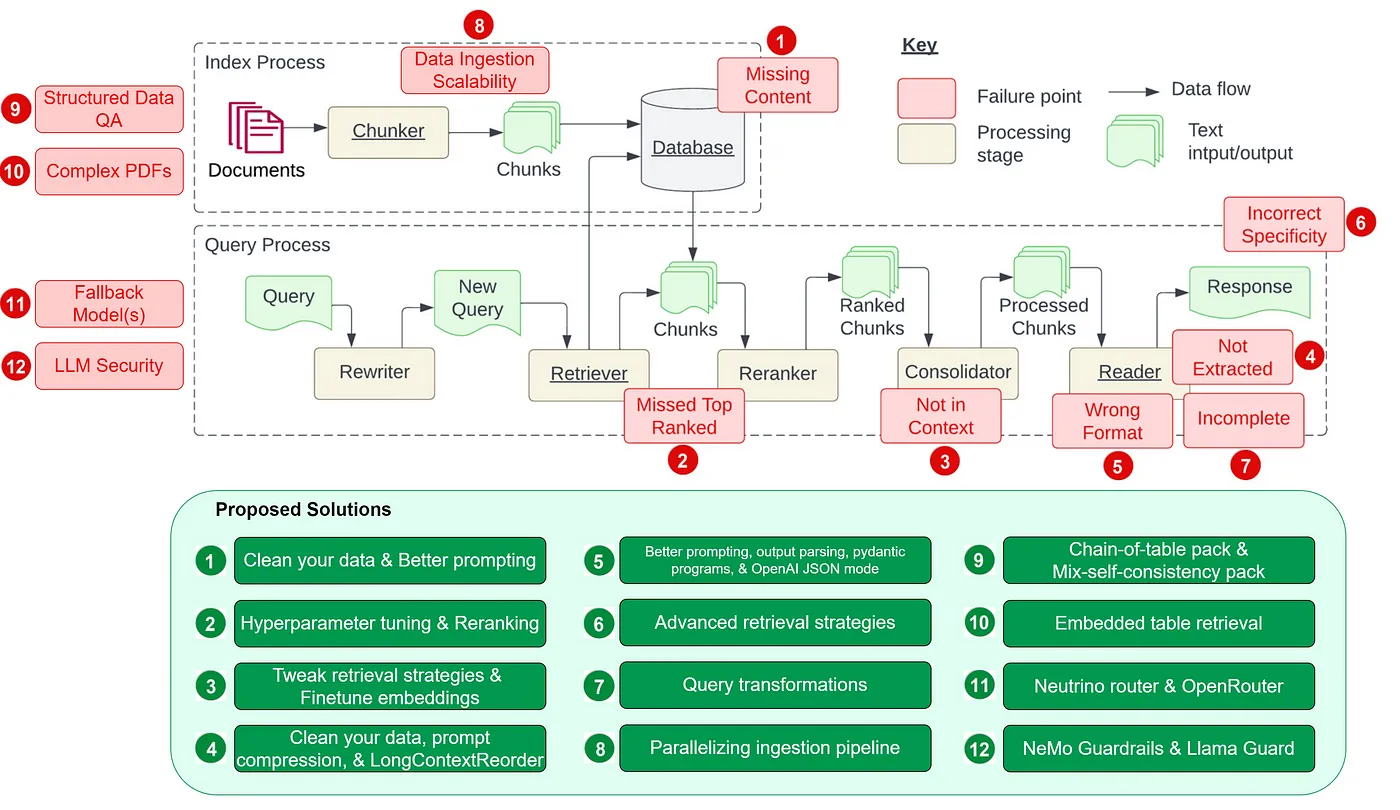
RAG
10 参考链接
- Retrieval-Augmented Generation for Large Language Models: A Survey
- RAPTOR: Recursive Abstractive Processing for Tree-Organized Retrieval
- Precise Zero-Shot Dense Retrieval without Relevance Labels
- G-Retriever: Retrieval-Augmented Generation for Textual Graph Understanding and Question Answering
- Self-RAG: Learning to Retrieve, Generate, and Critique through Self-Reflection
- Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
- Take a Step Back: Evoking Reasoning via Abstraction in Large Language Models
- Query Rewriting for Retrieval-Augmented Large Language Models
- https://github.com/run-llama/llama_index
- https://github.com/langchain-ai/langchain
- 12 RAG Pain Points and Proposed Solutions
- Advanced RAG Techniques: an Illustrated Overview
编辑于 2024-02-21 19:21・美国
赞同 41 条评论
分享
喜欢收藏申请转载