PPO、GRPO、DAPO、GSPO、DCPO 对比
PPO(Proximal Policy Optimization)
多采用 off policy 训练
数�据要求
- 原始数据集:只需要准备 prompt。
- 中间采样:需要利用 old model 进行 response 采样。
涉及模型
- reward model [不训、及时奖励]
- reference model [不训、计算 KL 散度、降低训偏风险]
- critic/value model [训练、状态价值,是否生成人类偏好的评估,也是动作的期望估计]
- actor/policy model [训练、目标模型,优化其按照人类偏好生成能力]
采样过程【单一采样】
- 利用 old model 对每个 prompt 采样单个 response,没有特殊要求限制
计算
-
reward: RM 打分,通常用在 last token 的打分 [主流]。也有用所有 token 的平均值作为分值。[模型打分 ] 利用人类偏好数据,提起训练好的 RM 模型,通常为 0-1 分值。分值越大代表生成结果更符合人类偏好
-
Value: [预期收益] critic/value model 对 response 的每一个 token 进行打分,目的是评估每个 token 状态下的价值,同时估计每个 token 生成时的动作价值期望。【模型打分 】
-
优势函数 :表示当前动作产生的实际价值估计 [ ] 与当前状态下执行所有可能动作的期望价值 当大于 0,表明当前动作产生的价值高于平均值,所以当前动作更有价值,更应该鼓励,当小于 0 时,说明当前动作产生的价值低于平均值,所有当前的动作价值不大,不应该鼓励。这样优化下可以在每步朝着最优的动作进行选择
-
return: [实际收益] 采用 AGE 的思想,利用后续 N 步的实际结果反推当前状态的实际收益,而非估计收益。结果更接近当前的收益。 这部分值是不会随着 off policy 过程中改变,主要是为了训练 critic。
-
KL 散度: 防止模型训偏,分为两部分:
-
在采样数据时根据 old model 和 ref model 之间构建 KL,结合 "rewards" 合并,并将其做为 rewards 的 token_level_rewards
-
在 off policy 训练过程中计算 new model 和 ref model 之间的 KL,随着训练进行计算。
注: 可以利用参考比如”use_kl_loss“来控制是否使用 KL。比如 trl 中利用直接使用第一种而不使用第二种。verl 中利用”use_kl_loss“来控制是否使用 [同时使用]。同时利用超参 [如 kl_loss_coef] 控制 KL 的占比
PPO 中需要计算 value、return,常采用第一种方式将其作为 rewards 的一部分
-
-
重要性采样:off policy 训练时,训练时的输入不是当前模型的实时结果,是 old 模型的提前生成的结果,是用 old 的生成来训练新的模型,为了降低训练时 new 的偏差,需要使用重要性采样计算。
-
Clip 处理:重要性采样虽然能解决 new 的偏差问题,但是无法解决采样过程中导致的方差变大问题,为了降低方差,当两者分布差距比较大时,采取丢弃数据��不训练 actor。 [token 维度 clip, 不区分 token,固定对称 clip 范围]
off policy 过程中,只更新对应的 和
经典参数:
Loss
-
critic loss: 优化 critic model. 目的是为了使 critic 对每个状态价值更准确的预测,即使实际价值与预测价值越接近越好,也就是优势函数 A 越小越好。所用 MSE loss 即可。同样为了对 actor 对齐,也会对 value 进行 clip 裁剪处理即
-
actor loss: 优化 actor model。 目的是每次采取的动作能够产生更多的价值,即如果当前的动作价值高于平均期望值,环境话说就是当前产生的实际价值高于期望价值, 即 �时,应该鼓励 actor 模型多产生这样的动作,相反,如果当前的动作价值低于评价期望值,即 ,应该尽量让 actor 模型少产生这样的动作。所以此时比较适用交叉熵作为损失函数。即
注意,这里的 Loss 没有 KL 散度,是因为将 KL 散度放在了 A 中
- 最终 backward 时 loss
- 联合 loss:一种是讲 critic loss 以一定权重 [如 ] 将加入到 actor loss 上进行联合优化,这样 actor loss 也会优化 critic ,同样 critic loss 也会优化 actor。【如 verl 的实现】
- 分别优化: 即��两个 loss 分别进行 backward,将对方的值作为其中的常量处理。即 critic loss 只优化 critic model 参数。 actor loss 只优化 actor model 参数。【如 trl 的实现】
在 off policy 过程中,只更新对应 new 的 p 和 value,其中 A、R、return、KL 都不会变化
GRPO(Group Relative Policy Optimization)
数据要求
- 原始数据集:只需要准备 prompt【同 PPO】
- 中间采样:需要利用 old model 进行 response 采样。每次每条 prompt 在 PPO 只需采样一个,但在 GRPO 每次每条 prompt 要采样更多的 response,用来计算优势函数。
采样过程:【多采样】
- 利用 old model 对每个 prompt 采样一组 G > 1 个 response,没有特殊要求限制。【PPO 是单个 response 即可】
涉及模型
相对 PPO,无需 critic/value model,只需要训练 actor/policy model 即可。
- reward model [不训、及时奖励]、
- reference model [不训、计算 KL 散度、降低训偏风险]、
- actor/policy model [训练、目标模型,优化其按照人类偏好生成能力]
计算
-
reward: 多采取 rule 打分的 reward,同时也可以用 PPO 中 RM 的打分模型。因为涉及到优势函数的计算,所有对 reward 对要求更高。同时采用 多种打分规则加权 获得最终的 reward 结果。【如 trl 中实现】
## Apply weights to each reward function's output and sum
rewards = (rewards_per_func * self.reward_weights.to(device).unsqueeze(0)).sum(dim=1) -
Value【无】: GRPO 作者认为,value 模型的效果好坏制约 critic 的训练效果,也限制模型潜力的发��掘。所有在训练过程中丢弃了 Value model 的使用,所有 GRPO 中不存在 Value 值。
-
return【无】: 没有 Value, 自然没有 return 值
-
优势函数: GRPO 是利用多个采样结果进行投票仲裁的方式进行计算,当前 response 的奖励相对均值的大小进行估计,而不是 PPO 的 value 等反推逻辑进行计算 【只考虑当前 step 生成的 response 簇,当 reward 相同时,优势值为 0, 无效更新模型】
表示每个 prompt 的采样 G 条 response 后对应第 条的 rewards
-
KL 散度: 相对 PPO 有部分存在差异。PPO 中常用的 K1 方式,且 DPO 采用的 K3.
GRPO 中的 KL 散度常加在 new model 和 ref model 上,在 off policy 训练过程中进行计算和更新。
-
重要性采样: 同 PPO
-
clip 处理: 同 PPO。[token 维度 clip, 不区分 token,固定对称 clip 范围]
Loss
GRPO 中不涉及 value model 的训练,所有训练过程中只涉及到 actor loss 计算和更新。
Verl 代码实现中,其实是按照 方式进行计算的 loss,及所谓的”token-level loss“。
Dr.GRPO
进行了大量实验, 在小模型上进行了多个实验,为后续 DAPO 做了实验基础。
-
涉及数据:同 GRPO
-
涉及模型:同 GRPO
-
采样过程:同 GRPO
计算
-
reward: Rule reward 同 GRPO
-
Value【无】: GRPO 作者认为,value 模型的效果好坏制约 critic 的训练效果,也限制模型潜力的发掘。所有在训练过程中丢弃了 Value model 的使用,所有 GRPO 中不存在 Value 值。
-
return【无】: 没有 Value, 自然没有 return 值。
-
clip: 同 PPO、GRPO [token 维度 clip, 不区分 token,固定对称 clip 范围]
-
优势函数: GRPO 是利用多个采样结果进行投票仲裁的方式进行计算,当前 response 的奖励相对均值的大小进行估计,而不是 PPO 的 value 等反推逻辑进行计算。作者认为在当问题过难或过容易时, 会变大,导致相应数据权重被加大,所以取消了 PPO 中常用的 std 归一化操作。【只考虑当前 step 生成的 response 簇,当 reward 相同时,优势值为 0, 无效更新模型】
表示每个 prompt 的采样 G 条 response 后对应第 条的 rewards。
Loss
相对 GRPO,认为序列的 token 平均,会受到不同长度 response 的长度影响,导致出现每个 token 的作用在整体 loss 中会有不同的权重,进而弱化或强调 token 的影响,所有将 去掉,利用最大 response 长度 M 进行统一加权平均。
DAPO(Decoupled Clip and Dynamic sAmPling Policy Optimization)
结合 Dr.GRPO, 在 GPRO 的基础上进行改进
-
涉及数据:同 GRPO
-
涉及模型:同 GRPO
-
采样过程:【动态采样】
-
【动态采样】利用 old model 对每个 prompt 采样一组 G > 1 [DAPO = 16] 个 response,同时要求 G 个 response 中必须同时包含正负样本且根据 Reward 方式进行丢弃或加权,否则对应 prompt 重新采样 [限定次数] 或被直接丢弃 [DAPO 做法],候补其他 prompt 进行采样。【PPO 是单个 response 即可\GRPO 没有特殊要求】
表示 G 个采样中第 i 个的 response
a 表示对应 prompt 的 global label
"is_equivalent" 表示是 response 结果和 global label 相同,即是否为正确的 response
, 表示在 G 个采样 response 中,response 为正确结果的个数。
该公式表示,G 个采样 response 不能全部是 True,也不能全部是 False 的 response。否则需要进行“丢弃 prompt 替补新 prompt”。
计算
-
reward: 在 GRPO 的基础上,增加对长度惩罚项或超长过滤。
- overlong filter: 超过最大长度的 response 直接丢弃,或在训练计算 loss 时利用 mask 方式将其设置为 0 [常用的隐形丢弃方法,好处可以保持 batch_size 稳定]。
- Soft Overlong Punishment [软超长惩罚机制]:对过长内容进行惩罚,作为 reward 的一部分。 详情看:
- : response 生成长度。
- : 最大生成长度。比如 DAPO 中设置为 2024*20
- : 完全惩罚为-1 的缓冲长度。比如 DAPO 中设置为 2024*4
-
KL 惩罚: 删除 KL 惩罚,也就是 verl 设置为 use_kl_loss = False, 且 kl_coef [ ] = 0.0。
base 模型的分布和期待具有思考能力的模型分布存在明显差异,KL 不应该限制其模型的探索空间。
-
Clip 处理:[Clip-high] 扩大上限,增加低分区间上限多样性的探索空间。[token 维度 clip, 不区分 token,固定非对称 clip 范围]
PPO、GPRO 中常将 上下限等宽,常设置 ,也就是上下限分别为 0.8 和 1.2。
- 低分时,假如 时, 对应不截取的下限为 0.008 和 上限为 0.012。此时 低分时,对模型分值区间有明显限制,也就是模型在低分段探索空间上限被限制明显,即限制了低分段的“多样性”探索空间。
- 高分时,假如 时, 对应不截取的上限为 0.09 和 上限为 1.08。此时 高分时,对分值大小没有明显约束,所有探索空间更大。
可以看出 从 0.01 到增加到 0.9 时,下限 一直在 0.09 下面徘徊,也就是对应 低分值比较友好,但是 上限 却从 0.012 跨度到 1.08。也就是当 越低时,允许模型在低分值的探索空间上限过小。所以 有必要提升 clip 的上限,增加低分段的探索空间上限。
所以采用 分别设定限制的方式,即 ,DAPO 中
- 与 PPO、GRPO 保持相同 [因为 clip 下限对探索空间影响不大[值非常小],所有无需变大]
- 提高 clip 的上限,提升低分空间的多样性探索空间
-
其他同 GRPO,如无 value、无 return、优势函数计算、重要性采样都相同
优于动态采样中已经将 reward 相同的 response 簇丢弃,所有采样后参与模型更新的 advantage 绝大多数非零(当 reward 定于复杂时,可能簇中部分 response 将归为 0)
Loss:token-level loss
论文中提到 GAPO 是 token-level loss 计算,GRPO 是 sample-level loss 计算,但在 VERL 代码中实际上 GRPO、PPO 也是 token level 计算。
GSPO(Group Sequence Policy Optimization)
在单一模型上进行验证,与 PPO、GRPO、DAPO、Dr.GRPO 主要区别在于 clip 从 token 维度转换为 sequence 维度,并针对 MOE 做了 router.
-
涉及数据:同 GRPO、Dr.GRPO、DAPO
-
涉及模型:同 GRPO、Dr.GRPO、DAPO
-
采样过程:同 GRPO、Dr.GRPO, 区别于 DAPO 动态采样
计算
-
reward,advantage 与 GRPO、Dr.GRPO 等相同,未像 DAPO 对长度进行惩罚,无 value、无 return。[advantage 计算仍只考虑当前 step 的 reward,会出现 advantage 为零的 response 簇。进而进行无效模型更新。]
-
clip: [sequence 维度 clip, 不区分 response,固定非对称 clip 范围], 两个变型:
-
以 sequence 为单位,整体进行 clip 剪切
对应的 loss:
-
以 token 为单位,就是将对应的 剔除梯度,并将 token 自身对大小做归一。
可以看出这里面只是将其 sequence 的重要权重等价分发到每个 token 上。对应 loss 也是采取 sequence-level
对应 相对 token-level 切割会非常小,可以等价于 token-level/response 长度的平均。
sequence-level clip 从 sequence 维度进行切割,避免高熵 sequence 参与模型训练,提高训练的稳定性。笔者认为 RL 是为了充分发挥模型自身多样性探索的自身能力,而高熵 sequence 携带的信息有利于模型多样性的探索,更激进高熵的 sequence 更有利 RL 训练。所以 GSPO 在一定程度上能够提高稳定性,但限制模型训练的能力。
DCPO(Dynamic Clipping Policy Optimization)
在 qwen2.5 系列上四个模型进行验证,并对比了 GRPO\DAPO\GSPO, DCPO 更加有效。
主要解决主流 RL 中普遍存在的问题:
1)固定 CLIP 范围对低概率 token 不友好,导致模型在高熵”rare token“上探索能力不足;
2)现有 advantage 计算只考虑当前生成的 response 簇,而生成过程中存在很大随机性,导致相同 reward 时梯度为零以及随机性生成的 response 归一化后的 advantage 会波动更大,对模型训练稳定性不友好问题。
-
涉及数据:同 GRPO、Dr.GRPO、DAPO
-
涉及模型:同 GRPO、Dr.GRPO、DAPO
-
采样过程:同 GRPO、Dr.GRPO, 区别于 DAPO 动态采样
计算
-
无 value、无 return。同 RLVR 系列 [GRPO\DAPO\Dr.GRPO\GSPO]
-
reward: 区分引起答案错误原因:是格式错误还是答案错误。【多个实验表明其实这个影响不大】
-
advantage 【 Smooth Advantage Standardization 】: 针对当前 reward 相同导致 advantage 为零以及随机采样对相同 reward 在不同 step 中抖动问题,考虑累计生成 reward 的归一化进行平滑
对于同一个 prompt,基于当前 reward 计算 advantage 和基于累计 reward 计算 advantage。利用步数加权。
为稳定 advantage 波动性,参与模型训练的 advantage 取其绝对值最小值。
好处是:当 reward 相同时,将以 权重参与模型更新过程中,即保留了 response 参与模型更新,又限制了其以很小的权重参与模型更新。
-
CLIP(Dynamic-Adaptive Clipping): 从动态采样方差的偏差出发,推到出对应不同概率的上下限范围,使 clip 剪切范围随着概率的变化成反比变化,在低旧概率时,可参与模型训练的新概率范围越大,这对模型在低概率高熵域有极大的探索空间。即有理论支持,同时更符合实际使用意义。具体推到可参考 LLMs-RL 中 off-policy 为什么要 clip 以及常见变体?(PPO\GRPO\DAPO\DC... 和 零梯度、零剪枝!DCPO 带你玩转强化学习。 【token 维度,动态区间,更好学习 rare token 的信息】
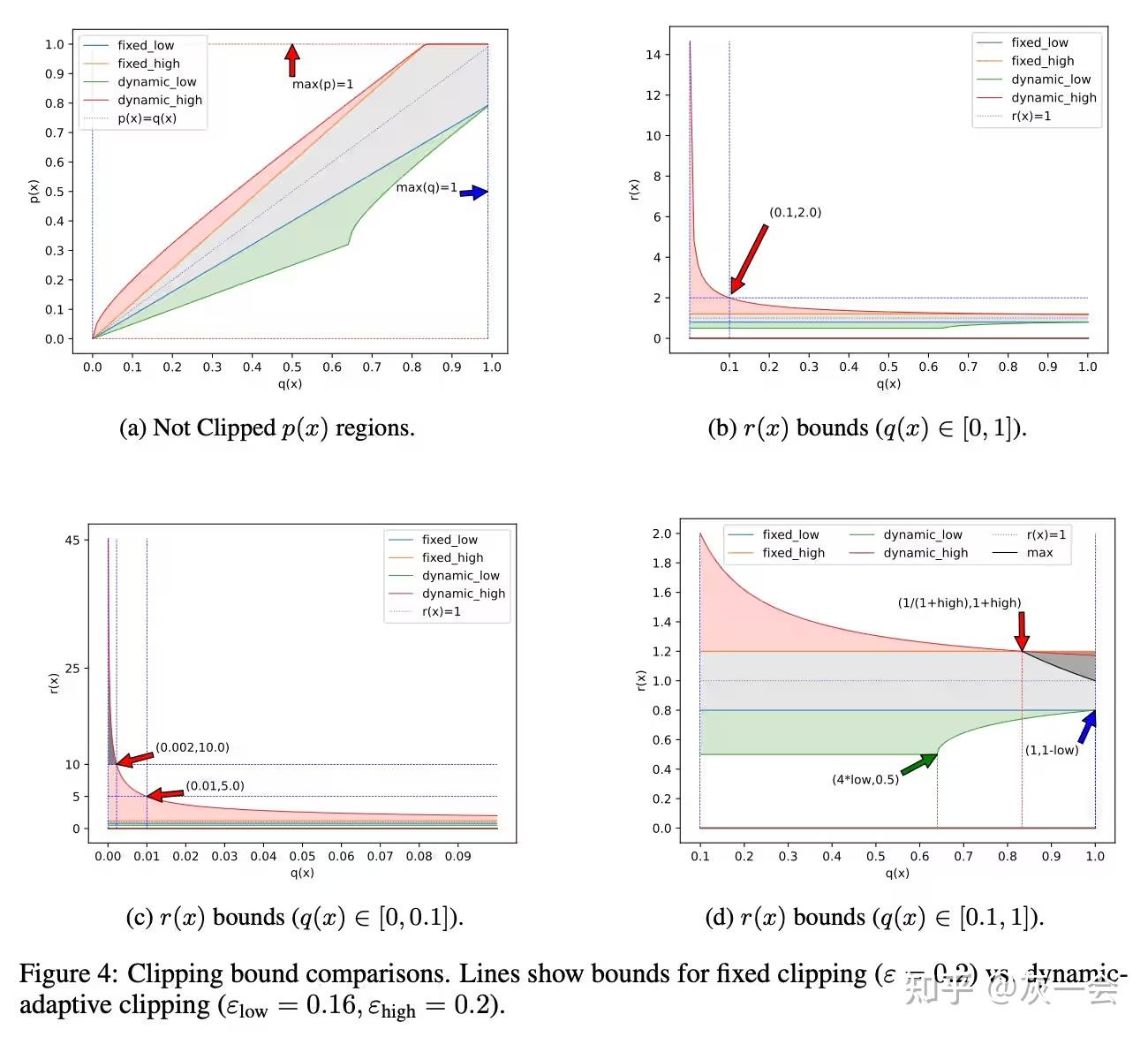
经典设置:
从图中可以看出,q(x)越小,可用的更新范围越大。比如:q(x)= 0.9 和 q(x)= 0.01 时
固定的 clip 时, p(x)对应的上下限为 0.72-1.08,和 0.008-0.012
动态的 clip 时,p(x)对应的上下限为 0.69-1.06, 和 0.005, 0.05. 在概率小的位置,上限更大
-
loss: 在 GRPO 的 sequence-level loss 基础上删除 batch 之间的平均,因为在计算 Advantage 标准化时已经获得了标准化关系,所有 response 如果进行 batch 平局,相应的标准化结果将被削弱,在模型更新时未充分发挥。【维持 advantage 的关系,充分发挥其作用】
DCPO 从 clip\advantage\loss 三个方面对前面对算法进行改进,且具有理论支持和通用性。效果更加。