信息论基础知识
信息论回答了通信理论中的两个基本问题:
- 数据压缩的临界值:熵
- 通信传输速率的临界值:信道容�量
但信息论的内容远不止于此,我们会在许许多多的领域中看见它的身影:通信理论,计算机科学,物理学(热力学),概率论与统计学,科学哲学,经济学等等……。
信息量
信息量是对信息的度量,信息是概率的单调函数.
, 符号保证了非负性. 低概率事件对应了高的信息量. 对数底选择是任意的, 信息论里面常用2, 单位是比特.
熵(entropy)
信息是一个相当宽泛的概念,很难用一个简单的定义将其完全准确地把握。然而对于任意一个概率分布,可以定义一个称为**熵(entropy)**的量,它具有许多符合信息度量的直观要求。
熵是随机变量不确定度的度量,也是平均意义上描述随机变量所需的信息的度量。
设是一个离散型随机变量,其字母表为。概率密度函数记作。则:
定义:熵(entropy)
一个离散型随机变量的熵定义为:
因为时,但在零点处无定义,所以约定。
有时候将上面的量记为。当使用以2为底数的对数时,熵的量纲为比特(bit)。当使用以为底数的自然对数时,熵的量纲为奈特(nat)。
因为是的概率分布函数,所以熵从另一个角度可以视作随机变量的期望值,记作
性质
- :熵非负,因为概率,所以。
- :熵底可变,因为,所以
例子
对于成功概率为的一次伯努利实验,实验结果随机变量为,其熵为:
当时,所得结果随机变量的熵为:1 bit。
直觉
虽然熵的定义可以由几条我们需要的性质推导出来,但其实这个定义背后隐藏着深刻的直觉。举个例子:
我们需要为一个字母表设计二进制编码,从而使得平均信息长度最短。字母出现的概率往往不等,这时候就需要按照字母出现频率越高,编码长度越短的原则进行编码分配。最优化编码要求为每个字母指定一个合适代价,使得总体平均代价最低。什么样的代价是合适的代价?一条简单朴素的原则就是:*每个字母的编码开销(cost),应当正比于其出现概率。
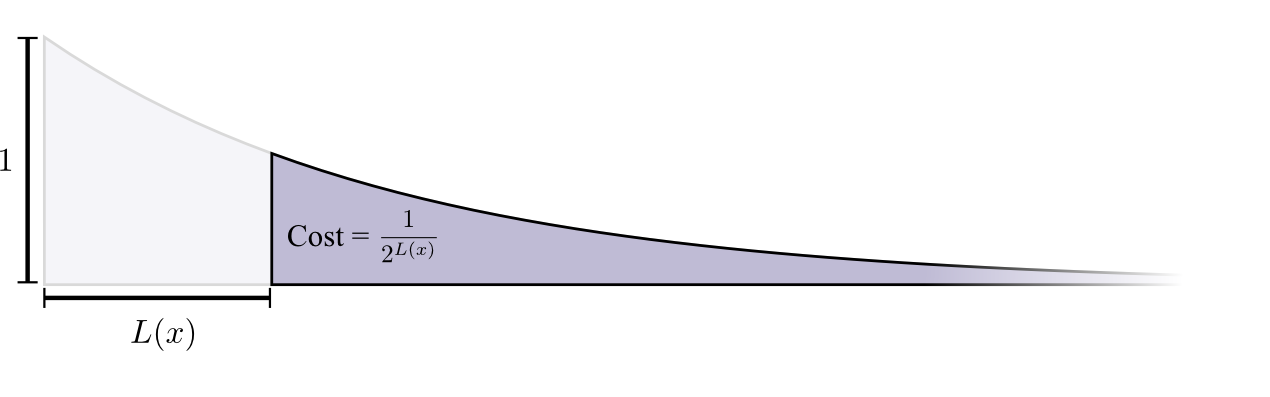
另一方面,我们需要考量字母的最佳编码长度和编码开销的关系。变长编码存在着一个问题:如果要求每个信息串都可以无歧义地进行切分与解码,就要求任意一个单词的编码不能为另一个单词编码的前缀,否则就会出现冲突。对于二进制,可以采用这样的办法,令0作为末尾界定符。因此以四个单词A,B,C,D为例,可以分别编码为0,10,110,111。对于每一个字母,当为它分配了长度的编码时,付出的代价又是什么呢?整个编码空间中,以该字母编码为前缀的所有编码都无法再分配了。例如为B分配了长度为2的编码10后,所有100,101,1000,1001,...都不能用了,也就是整个编码空间的四分之一,作为代价被损失掉了。
所以对于二进制编码长度为的消息,它的代价是,即。反过来,我们可以得知,对于出现概率为的字母,我们为其设置的最佳编码长度应当为:
那么事情就明显了,字母最佳编码长度按照其出现概率加权,得到的就是最佳平均编码长度,也就是熵!
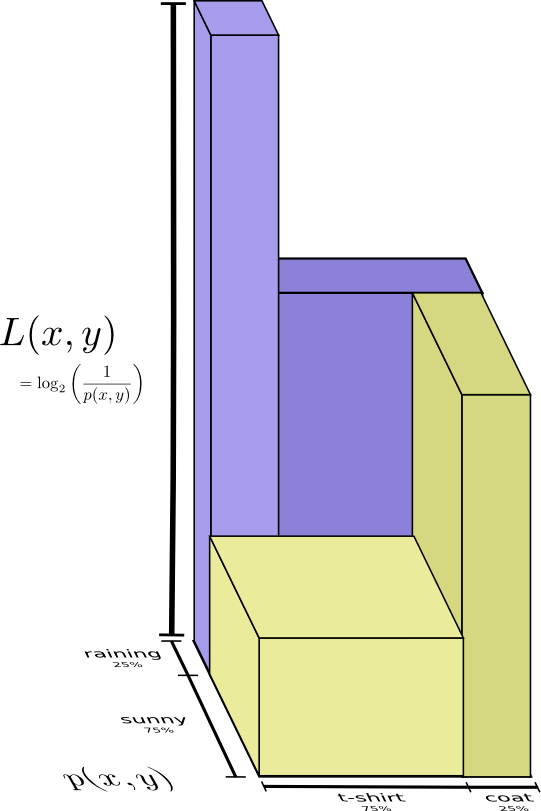
联合熵(joint entropy)(相当于并集)
将单个随机变量的熵推广到两个随机变量的情形即可得到联合熵的概念。
如果和独立同分布,联合概率分布
定义:联合熵(joint entropy)
对于服从联合概率分布为的一对离散随机变量,其联合熵定义为:
简写为:
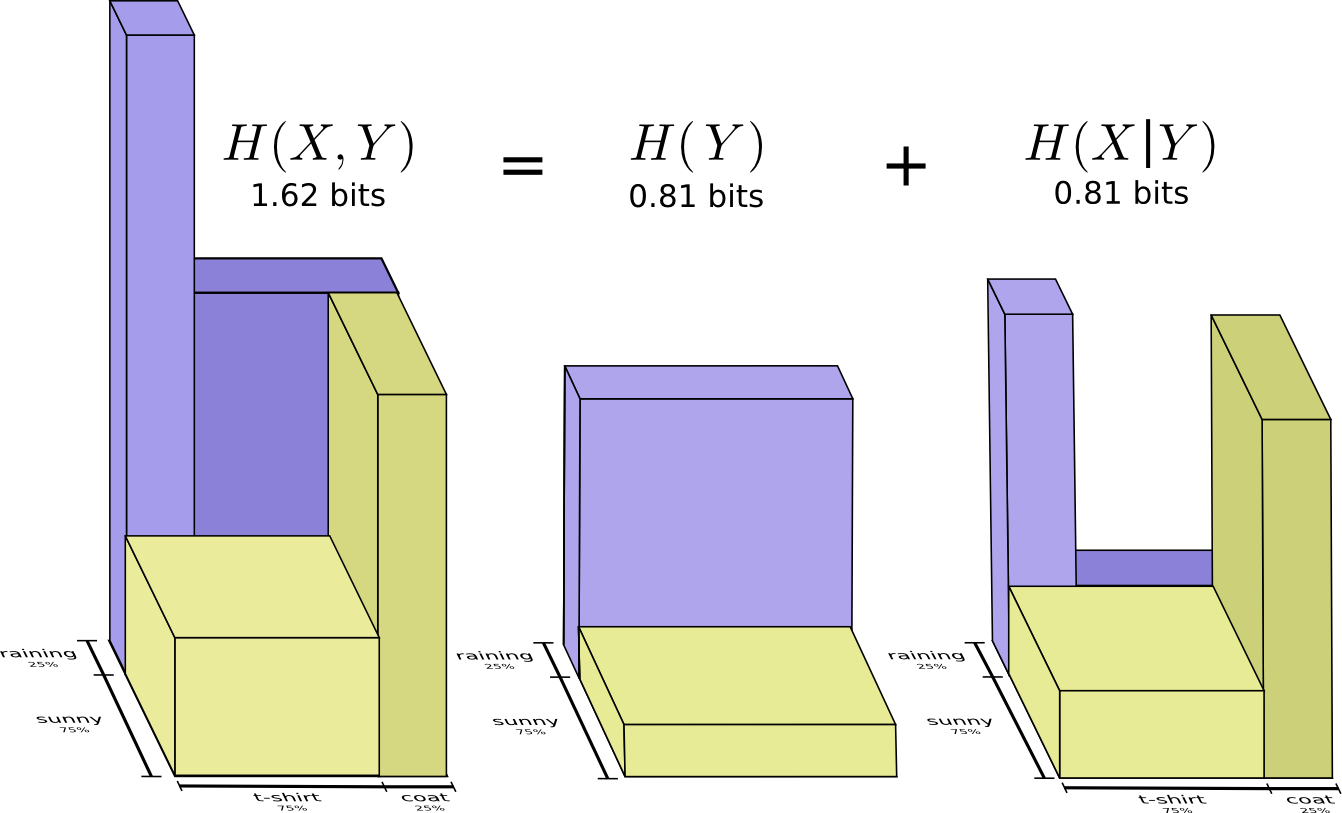
条件熵(conditional entropy)
一个随机变量在给定另一随机变量下的熵称为条件熵。
条件熵衡量了条件概率分布的均匀性,最大熵,就是最大这个条件熵
定义:条件熵(conditional entropy)
若,条件熵定义为:
性质
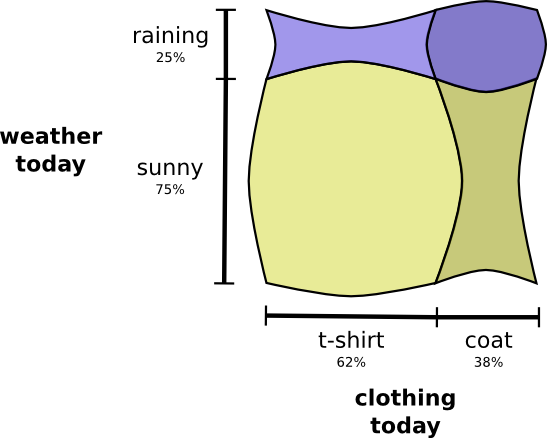
互信息(mutual information)
互信息,对应熵里面的交集,常用来描述差异性
一般的,熵与条件熵之差称为互信息。注意一下, 可以对应理解下。
- Feature Selection
- Feature Correlation,刻画的是相互之间的关系。 相关性主要刻画线性,互信息刻画非线性
考虑两个随机变量,它们的联合概率密度函数为,其边际概率密度函数分别为。互信息定义为其联合分布与乘积分布之间的相对熵:
将互信息表示为联合分布对分布之积的相对熵,衡量了两个随机变量之间有多么独立。
作为一种极端情况,当时,两个随机变量完全相关,这时候。所以有时候,熵又称为自信息(self-infomation)
| 独立变量 | 非独立变量 |
|---|---|
 |  |
当然实际上, 互信息量还可以用另一种更为直观的方式表示出来。如果随机各自的熵为,联合熵为,则互信息可表示为:
这是很好理解的,因为中包含了两份共有的信息,而中只有一份。
互信息和条件熵之间的关系
可以把互信息看成由于知道值而造成的的不确定性的减小(反之亦然)。这个就是信息增益那部分的解释。
性质
对任意的两个随机变量
且当且仅当相互独立时等号成立。
这说明知道任意其他随机变量只会降低的不确定度。
相互关系
互信息I(X;Y),自信息H(X),联合信息H(X,Y),条件信息H(Y|X)之间的关系
一图以蔽之,关系如下:
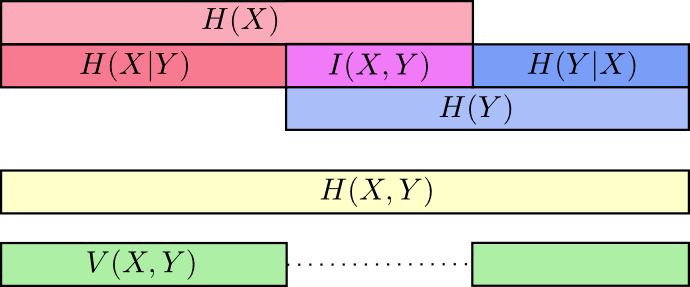
交叉熵(cross entropy)与相对熵(relative entropy)
对于一个随机分布,如果使用针对分布优化的编码,则平均的消息长度为
这时可以证明,平均编码长度是最优的。但如果使用了针对另一个随机分布优化的编码,就会出现一定程度的无效性。这时候消息的平均长度就需要个比特来表示。
这里实际分布是,但编码为字母设置的代价却是按照分布进行优化的。
称为分布相对于分布的交叉熵(cross entropy)
p对q的交叉熵本身可以分为两部分之和:分布本身的熵,以及相对的相对熵

相对熵,又称为KL散度(Kullback-Leibler divergence, KLD),信息散度,信息增益,KL距离。是两个随机分布之间距离的度量。相对熵度量当真实分布为而假定分布为时的无效性度量。
定义:相对熵
两个概率密度函数为和之间的相对熵定义为:
性质
- 相对熵总是非负的,当时,的最优编码就是的最优编码,所以。
- 相对差并不是对称的:
应用
交叉熵作为两个分布之间差异的度量,广泛应用于机器学习中。例如在作为神经网络代价函数时有:
其中,是样本的标签,是评价的基准分布,是神经网络的推断输出,是实际工作时的结果分布。