Csi-feedback
这个代码仿真实现了Csi_Net,Csi_CNN_Transformer_Net,Csi_Transformer_Net,CS_Net
load data and pre-processing data
import numpy as np
import h5py
import torch
from torch.utils.data import Dataset
img_height = 16
img_width = 32
img_channels = 2
class DatasetFolder(Dataset):
def __init__(self, matData):
self.matdata = matData
def __len__(self):
return self.matdata.shape[0]
def __getitem__(self, index):
return self.matdata[index]
def load_data(
file_path,
shuffle = False,
train_test_ratio=0.8,
batch_size=32,
num_workers=0,
pin_memory=True,
drop_last=True):
print("loading data...")
mat = h5py.File('Hdata.mat', 'r')
data = np.transpose(mat['H_train'])
data = data.astype('float32')
data = np.reshape(data, [len(data), img_channels, img_height, img_width])
# Use only 1/40 of the data
num_samples = len(data)
reduced_size = num_samples // 40
data = data[:reduced_size]
if shuffle:
data_copy = np.copy(data)
data_transpose = data_copy.transpose()
np.random.shuffle(data_transpose)
data_shuffle = data_transpose.transpose()
partition = int(data.shape[0] * train_test_ratio)
x_train, x_test = data[:partition], data[partition:]
x_train_shuffle, x_test_shuffle = data_shuffle[:partition], data_shuffle[partition:]
# dataLoader for training
train_dataset = DatasetFolder(x_train)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size,
shuffle=True, num_workers=num_workers,
pin_memory=pin_memory, drop_last=drop_last)
# dataLoader for validating
test_dataset = DatasetFolder(x_test)
test_loader = torch.utils.data.DataLoader(test_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers, pin_memory=pin_memory)
if shuffle:
train_shuffle_dataset = DatasetFolder(x_train_shuffle)
train_shuffle_loader = torch.utils.data.DataLoader(train_shuffle_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers, pin_memory=pin_memory)
test_shuffle_dataset = DatasetFolder(x_test_shuffle)
test_shuffle_loader = torch.utils.data.DataLoader(test_shuffle_dataset, batch_size=batch_size,
shuffle=False, num_workers=num_workers, pin_memory=pin_memory)
return train_loader, test_loader, train_dataset, test_dataset, train_shuffle_loader, test_shuffle_loader, train_shuffle_dataset, test_shuffle_dataset
return train_loader, test_loader, train_dataset, test_dataset
loss
import torch.nn as nn
def NMSE(x, x_hat):
x_real = np.reshape(x[:, :, :, 0], (len(x), -1))
x_imag = np.reshape(x[:, :, :, 1], (len(x), -1))
x_hat_real = np.reshape(x_hat[:, :, :, 0], (len(x_hat), -1))
x_hat_imag = np.reshape(x_hat[:, :, :, 1], (len(x_hat), -1))
x_C = x_real - 0.5 + 1j * (x_imag - 0.5)
x_hat_C = x_hat_real - 0.5 + 1j * (x_hat_imag - 0.5)
power = np.sum(abs(x_C) ** 2, axis=1)
mse = np.sum(abs(x_C - x_hat_C) ** 2, axis=1)
nmse = np.mean(mse / power)
return nmse
def NMSE_cuda(x, x_hat):
x_real = x[:, 0, :, :].view(len(x), -1) - 0.5
x_imag = x[:, 1, :, :].view(len(x), -1) - 0.5
x_hat_real = x_hat[:, 0, :, :].contiguous().view(len(x_hat), -1) - 0.5
x_hat_imag = x_hat[:, 1, :, :].contiguous().view(len(x_hat), -1) - 0.5
power = torch.sum(x_real ** 2 + x_imag ** 2, axis=1)
mse = torch.sum((x_real - x_hat_real) ** 2 + (x_imag - x_hat_imag) ** 2, axis=1)
nmse = mse / power
return nmse
class NMSELoss(nn.Module):
def __init__(self, reduction='sum'):
super(NMSELoss, self).__init__()
self.reduction = reduction
def forward(self, x_hat, x):
nmse = NMSE_cuda(x, x_hat)
if self.reduction == 'mean':
nmse = torch.mean(nmse)
else:
nmse = torch.sum(nmse)
return nmse
def rho(x, x_hat):
x_real = x[:, 0, :, :].view(len(x), -1) - 0.5
x_imag = x[:, 1, :, :].view(len(x), -1) - 0.5
x_hat_real = x_hat[:, 0, :, :].contiguous().view(len(x_hat), -1) - 0.5
x_hat_imag = x_hat[:, 1, :, :].contiguous().view(len(x_hat), -1) - 0.5
cos = nn.CosineSimilarity(dim=1, eps=0)
out_real = cos(x_real,x_hat_real)
out_imag = cos(x_imag, x_hat_imag)
result_real = out_real.sum() / len(out_real)
reault_imag = out_imag.sum() / len(out_imag)
return 0.5*(result_real + reault_imag)
class CosSimilarity(nn.Module):
def __init__(self, reduction='sum'):
super(CosSimilarity, self).__init__()
self.reduction = reduction
def forward(self, x_hat, x):
cos = rho(x, x_hat)
# if self.reduction == 'mean':
# cos = torch.mean(cos)
# else:
# cos = torch.sum(cos)
return cos
Modules
import torch.nn.functional as F
from collections import OrderedDict
def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=True)
class ConvBN(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, groups=1):
if not isinstance(kernel_size, int):
padding = [(i - 1) // 2 for i in kernel_size]
else:
padding = (kernel_size - 1) // 2
super(ConvBN, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
('bn', nn.BatchNorm2d(out_planes)),
('LeakyReLU', nn.LeakyReLU(negative_slope=0.3, inplace=False))
]))
class ConvBN_linear(nn.Sequential):
def __init__(self, in_planes, out_planes, kernel_size, stride=1, groups=1):
if not isinstance(kernel_size, int):
padding = [(i - 1) // 2 for i in kernel_size]
else:
padding = (kernel_size - 1) // 2
super(ConvBN_linear, self).__init__(OrderedDict([
('conv', nn.Conv2d(in_planes, out_planes, kernel_size, stride,
padding=padding, groups=groups, bias=False)),
('bn', nn.BatchNorm2d(out_planes))
]))
class ResBlock(nn.Module):
def __init__(self, ch, nblocks=1, shortcut=True):
super().__init__()
self.shortcut = shortcut
self.module_list = nn.ModuleList()
for i in range(nblocks):
resblock_one = nn.ModuleList()
resblock_one.append(ConvBN(ch, 8, 3))
resblock_one.append(ConvBN(8, 16, 3))
resblock_one.append(ConvBN_linear(16, ch, 3))
self.module_list.append(resblock_one)
def forward(self, x):
for module in self.module_list:
h = x
for res in module:
h = res(h)
x = x + h if self.shortcut else h
return x
class PatchEmbed(nn.Module):
def __init__(self, H=16, W=32, patch_size=4, in_chans=2, embed_dim=32):
super().__init__()
num_patches = H * W / patch_size ** 2
self.img_size = [H, W]
self.patch_size = [patch_size, patch_size]
self.num_patches = num_patches
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
def forward(self, x):
x = self.proj(x).flatten(2).transpose(1, 2)
return x
class FixedPositionalEncoding(nn.Module):
def __init__(self, embedding_dim, max_length=5000):
super(FixedPositionalEncoding, self).__init__()
pe = torch.zeros(max_length, embedding_dim)
position = torch.arange(0, max_length, dtype=torch.float).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, embedding_dim, 2).float()
* (-torch.log(torch.tensor(10000.0)) / embedding_dim)
)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0).transpose(0, 1)
self.register_buffer('pe', pe)
def forward(self, x):
x = x + self.pe[: x.size(0), :]
return x
class TransformerEncoder(torch.nn.Module):
def __init__(self, embed_dim, num_heads, dropout, feedforward_dim):
super().__init__()
self.attn = torch.nn.MultiheadAttention(embed_dim, num_heads, dropout=dropout)
self.linear_1 = torch.nn.Linear(embed_dim, feedforward_dim)
self.linear_2 = torch.nn.Linear(feedforward_dim, embed_dim)
self.layernorm_1 = torch.nn.LayerNorm(embed_dim)
self.layernorm_2 = torch.nn.LayerNorm(embed_dim)
def forward(self, x_in):
attn_out, _ = self.attn(x_in, x_in, x_in)
x = self.layernorm_1(x_in + attn_out)
ff_out = self.linear_2(torch.nn.functional.relu(self.linear_1(x)))
x = self.layernorm_2(x + ff_out)
return x
class Csi_Encoder(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Encoder, self).__init__()
self.convban = nn.Sequential(OrderedDict([
("conv3x3_bn", ConvBN_linear(1, 2, 1)),
]))
self.fc = nn.Linear(2048, int(feedback_bits))
def forward(self, x_in):
x_in = x_in.view(32,1,32,32)
out = self.convban(x_in)
out = out.view(32,-1)
out = self.fc(out)
return out
class Csi_Decoder(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Decoder, self).__init__()
self.feedback_bits = feedback_bits
self.fc = nn.Linear(int(feedback_bits), 1024)
decoder = OrderedDict([
("decoder1",ResBlock(1)),
('LeakyReLU', nn.LeakyReLU(negative_slope=0.3, inplace=False)),
("decoder2",ResBlock(1))
])
self.decoder_feature = nn.Sequential(decoder)
self.out_cov = ConvBN_linear(1,1,3)
self.sig = nn.Sigmoid()
def forward(self, x):
out = x
out = self.fc(out)
out = out.view(32, 1, -1, 32)
out = self.decoder_feature(out)
out = self.out_cov(out)
out = self.sig(out)
out = out.view(32,2,16,32)
return out
class Csi_Attention_Encoder(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Attention_Encoder, self).__init__()
# with positional encoding
# self.patch_embedding = nn.Sequential(OrderedDict([
# ("patch_embedding", PatchEmbed(H=16, W=32, patch_size=4, in_chans=2, embed_dim=32))
# ]))
# self.positional_encoding = nn.Sequential(OrderedDict([
# ("positional_encoding", FixedPositionalEncoding(32,32))
# ]))
# self.transformer_layer = nn.Sequential(OrderedDict([
# ("transformer_encoder1", TransformerEncoder(32,8,0,512)) # after [32, 512, 32]
# ])) # for added positional encoding
# without positional encoding
self.conv_layer = ConvBN_linear(1,2,1)
self.transformer_layer = nn.Sequential(OrderedDict([
("transformer_encoder1", TransformerEncoder(64,8,0,512))
])) # without positional encoding
self.fc = nn.Linear(2048, int(feedback_bits))
def forward(self, x_in):
# with pos encoding
##x_in = self.patch_embedding(x_in)
##x_in = self.positional_encoding(x_in)
# without pos encoding
x_in = x_in.view(32,1,32,32)
x_in = self.conv_layer(x_in)
x_in = x_in.view(32,32,64)
out = self.transformer_layer(x_in)
#out = out.contiguous().view(32,-1) with pos encoding
out = out.contiguous().view(-1, 2048) # without pos encoding
out = self.fc(out)
return out
class Csi_Attention_Decoder(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Attention_Decoder, self).__init__()
self.feedback_bits = feedback_bits
self.fc = nn.Linear(int(feedback_bits), 2048)
decoder = OrderedDict([
("transformer_decoder1",TransformerEncoder(64,8,0,feedforward_dim=128))
])
self.decoder_feature = nn.Sequential(decoder)
self.conv_linear = ConvBN_linear(2,1,1)
self.sig = nn.Sigmoid()
def forward(self, x):
out = x
out = self.fc(out)
out = out.view(32, -1, 64)
out = self.decoder_feature(out)
out = out.view([32,2,32,32])
out = self.conv_linear(out)
out = self.sig(out)
out = out.view(32,2,16,32)
return out
class Csi_Net(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Net, self).__init__()
self.encoder = Csi_Encoder(feedback_bits)
self.decoder = Csi_Decoder(feedback_bits)
def forward(self, x):
feature = self.encoder(x)
out = self.decoder(feature)
return out
class Csi_Transformer_Net(nn.Module):
def __init__(self, feedback_bits):
super(Csi_Transformer_Net, self).__init__()
self.encoder = Csi_Attention_Encoder(feedback_bits)
self.decoder = Csi_Attention_Decoder(feedback_bits)
def forward(self, x):
feature = self.encoder(x)
out = self.decoder(feature)
return out
class CS_Net(nn.Module):
def __init__(self, feedback_bits):
super(CS_Net, self).__init__()
self.A = np.random.uniform(low=-0.5, high=0.5, size=(1024, feedback_bits))
self.A = torch.from_numpy(self.A)
self.A = self.A.float()
self.decoder = Csi_Decoder(feedback_bits)
def forward(self, x):
x = x.view(32, -1)
out = x @ self.A
out = self.decoder(out)
return out
class Csi_CNN_Transformer_Net(nn.Module):
def __init__(self, feedback_bits):
super(Csi_CNN_Transformer_Net, self).__init__()
self.encoder = Csi_Encoder(feedback_bits)
self.decoder = Csi_Attention_Decoder(feedback_bits)
def forward(self, x):
feature = self.encoder(x)
out = self.decoder(feature)
return out
image segmentation
import matplotlib as plt
import os
import random
import time
import matplotlib.pyplot as plt
gpu_list = '0'
os.environ["CUDA_VISIBLE_DEVICES"] = gpu_list
def seed_everything(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
def channel_visualization(image):
fig, ax = plt.subplots()
ax.imshow(image, cmap=plt.cm.gray, interpolation='nearest', origin='upper')
ax.spines['left'].set_position(('outward', 10))
ax.spines['bottom'].set_position(('outward', 10))
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.yaxis.set_ticks_position('left')
ax.xaxis.set_ticks_position('bottom')
plt.show()
SEED = 42
print("seeding everything...")
seed_everything(SEED)
print("initializing parameters...")
class model_trainer():
def __init__(self,
epochs,
net,
feedbackbits=128,
batch_size=32,
learning_rate=1e-3,
lr_decay_freq=30,
lr_decay=0.1,
best_loss=100,
num_workers=0,
print_freq=100,
train_test_ratio=0.8):
self.epochs = epochs
self.batch_size = batch_size
self.learning_rate = learning_rate
self.lr_decay_freq = lr_decay_freq
self.lr_decay = lr_decay
self.best_loss = best_loss
self.num_workers = num_workers
self.print_freq = print_freq
self.train_test_ratio = train_test_ratio
# parameters for data
self.feedback_bits = feedbackbits
self.img_height = 16
self.img_width = 32
self.img_channels = 2
self.model = eval(net)(self.feedback_bits)
self.x_label = []
self.y_label = []
self.ys_label = []
self.t_label = []
# if len(gpu_list.split(',')) > 1:
# self.model = torch.nn.DataParallel(self.model).cuda() # model.module
# else:
# self.model = self.model.cuda()
self.model = self.model
self.criterion = NMSELoss(reduction='mean') # nn.MSELoss()
self.criterion_test = NMSELoss(reduction='sum')
# self.criterion_rho = CosSimilarity(reduction='mean')
# self.criterion_test_rho = CosSimilarity(reduction='sum')
self.optimizer = torch.optim.AdamW(self.model.parameters(), lr=self.learning_rate)
# train_loader, test_loader, train_dataset, test_dataset, \
# train_shuffle_loader, test_shuffle_loader, train_shuffle_dataset, test_shuffle_dataset
self.train_loader, self.test_loader, self.train_dataset, self.test_dataset, self.train_shuffle_loader, self.test_shuffle_loader, self.train_shuffle_dataset, self.test_shuffle_dataset = load_data('data/',shuffle = True)
def model_save(self, model_path):
print('Saving the entire model...')
torch.save(self.model, model_path)
print(f'Model saved to {model_path}')
print('Model saved!')
self.best_loss = self.average_loss
def model_train(self):
for epoch in range(self.epochs):
print('========================')
print('lr:%.4e' % self.optimizer.param_groups[0]['lr'])
# train model
self.model.train()
# decay lr
if epoch % self.lr_decay_freq == 0 and epoch > 0:
self.optimizer.param_groups[0]['lr'] = self.optimizer.param_groups[0]['lr'] * self.lr_decay
# training...
for i, input in enumerate(self.train_loader):
# input = input.cuda() # input [batch=32,2,16,32]
output = self.model(input)
loss = self.criterion(output, input)
loss.backward()
self.optimizer.step()
self.optimizer.zero_grad()
if i % self.print_freq == 0:
print('Epoch: [{0}][{1}/{2}]\t'
'Loss {loss:.4f}\t'.format(
epoch, i, len(self.train_loader), loss=loss.item()))
self.model.eval()
# evaluating...
self.total_loss = 0
self.total_rho = 0
start = time.time()
with torch.no_grad():
for i, input in enumerate(self.test_loader):
# input = input.cuda()
output = self.model(input)
self.total_loss += self.criterion_test(output, input).item()
# self.total_rho += self.criterion_rho(output,input).item()
#print(rho(output,input), type(rho(output,input)))
self.total_rho += (rho(output,input))
end = time.time()
t = end - start
self.average_loss = self.total_loss / len(self.test_dataset)
self.average_rho = self.total_rho / len(list(enumerate(self.test_loader)))
self.x_label.append(epoch)
self.y_label.append(self.average_loss)
self.t_label.append(t)
print('NMSE %.4f ρ %.3f time %.3f' % (self.average_loss,self.average_rho, t))
for i, input in enumerate(self.test_loader): # visualize one sample
if i == 3: # set shuffle = False to ensure the same sample each time
ones = torch.ones(32,32)
image1 = input[0].view(32,32)
image1 = ones - image1
image1 = image1.numpy()
channel_visualization(image1)
# input = input.cuda()
output = self.model(input)
output = output.cpu()
image2 = output[0].view(32,32)
image2 = ones - image2
image2 = image2.detach().numpy()
channel_visualization(image2)
return self.x_label, self.y_label, sum(self.t_label)/len(self.t_label) # , self.ys_label
seeding everything...
initializing parameters...
train
import numpy as np
import matplotlib.pyplot as plt
import h5py
import torch
import os
import torch.nn as nn
import random
# gpu_list = '0'
# os.environ["CUDA_VISIBLE_DEVICES"] = gpu_list
def seed_everything(seed=42):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
SEED = 42
seed_everything(SEED)
# bits = 256
bits = 128
# bits = 64
# bits = 32
Csi_Net
print("="*30)
print("Encoder: CNN; Decoder: CNN")
print("compressed codeword bits: {}".format(bits))
agent3 = model_trainer(epochs=40, net="Csi_Net",feedbackbits=bits)
x3, agent3_NMSE, t3 = agent3.model_train()
print("Csi_Net")
print(agent3_NMSE)
print("average time used is:", t3)
plt.plot(x3, agent3_NMSE, label="cnn")
# 保存模型
model_path = f'models/Csi_Net_model_{bits}.pth'
agent3.model_save(model_path)
==============================
Encoder: CNN; Decoder: CNN
compressed codeword bits: 128
loading data...
========================
lr:1.0000e-03
Epoch: [0][0/200] Loss 14.1170
Epoch: [0][100/200] Loss 1.6231
NMSE 1.3334 ρ 0.058 time 1.204
========================
lr:1.0000e-03
Epoch: [1][0/200] Loss 1.2072
Epoch: [1][100/200] Loss 1.3410
NMSE 1.1423 ρ 0.174 time 0.573
========================
lr:1.0000e-03
Epoch: [2][0/200] Loss 1.1115
Epoch: [2][100/200] Loss 1.1585
NMSE 1.0452 ρ 0.293 time 0.535
========================
lr:1.0000e-03
Epoch: [3][0/200] Loss 1.0717
Epoch: [3][100/200] Loss 0.9346
NMSE 0.8754 ρ 0.463 time 1.153
========================
lr:1.0000e-03
Epoch: [4][0/200] Loss 0.8362
Epoch: [4][100/200] Loss 0.6380
NMSE 0.6576 ρ 0.614 time 0.521
========================
lr:1.0000e-03
Epoch: [5][0/200] Loss 0.6203
Epoch: [5][100/200] Loss 0.5353
NMSE 0.5380 ρ 0.693 time 0.568
========================
lr:1.0000e-03
Epoch: [6][0/200] Loss 0.5071
Epoch: [6][100/200] Loss 0.5355
NMSE 0.4787 ρ 0.733 time 0.545
========================
lr:1.0000e-03
Epoch: [7][0/200] Loss 0.4867
Epoch: [7][100/200] Loss 0.4088
NMSE 0.4406 ρ 0.759 time 0.640
========================
lr:1.0000e-03
Epoch: [8][0/200] Loss 0.4613
Epoch: [8][100/200] Loss 0.4002
NMSE 0.4013 ρ 0.782 time 0.528
========================
lr:1.0000e-03
Epoch: [9][0/200] Loss 0.3757
Epoch: [9][100/200] Loss 0.3755
NMSE 0.3983 ρ 0.787 time 0.537
========================
lr:1.0000e-03
Epoch: [10][0/200] Loss 0.3914
Epoch: [10][100/200] Loss 0.4193
NMSE 0.4489 ρ 0.762 time 0.529
========================
lr:1.0000e-03
Epoch: [11][0/200] Loss 0.4755
Epoch: [11][100/200] Loss 0.3684
NMSE 0.3594 ρ 0.809 time 0.515
========================
lr:1.0000e-03
Epoch: [12][0/200] Loss 0.3788
Epoch: [12][100/200] Loss 0.3704
NMSE 0.3356 ρ 0.820 time 0.580
========================
lr:1.0000e-03
Epoch: [13][0/200] Loss 0.3617
Epoch: [13][100/200] Loss 0.3398
NMSE 0.3221 ρ 0.827 time 0.750
========================
lr:1.0000e-03
Epoch: [14][0/200] Loss 0.3272
Epoch: [14][100/200] Loss 0.4293
NMSE 0.3350 ρ 0.820 time 0.525
========================
lr:1.0000e-03
Epoch: [15][0/200] Loss 0.3543
Epoch: [15][100/200] Loss 0.3455
NMSE 0.3119 ρ 0.835 time 0.516
========================
lr:1.0000e-03
Epoch: [16][0/200] Loss 0.2992
Epoch: [16][100/200] Loss 0.9529
NMSE 0.2986 ρ 0.840 time 0.599
========================
lr:1.0000e-03
Epoch: [17][0/200] Loss 0.2856
Epoch: [17][100/200] Loss 0.3119
NMSE 0.2954 ρ 0.843 time 0.573
========================
lr:1.0000e-03
Epoch: [18][0/200] Loss 0.2677
Epoch: [18][100/200] Loss 0.2961
NMSE 0.2801 ρ 0.850 time 0.847
========================
lr:1.0000e-03
Epoch: [19][0/200] Loss 0.2459
Epoch: [19][100/200] Loss 0.2546
NMSE 0.2758 ρ 0.852 time 0.615
========================
lr:1.0000e-03
Epoch: [20][0/200] Loss 0.2563
Epoch: [20][100/200] Loss 0.2762
NMSE 0.2699 ρ 0.855 time 0.553
========================
lr:1.0000e-03
Epoch: [21][0/200] Loss 0.2847
Epoch: [21][100/200] Loss 0.2760
NMSE 0.2617 ρ 0.859 time 0.501
========================
lr:1.0000e-03
Epoch: [22][0/200] Loss 0.2808
Epoch: [22][100/200] Loss 0.2431
NMSE 0.2645 ρ 0.856 time 1.056
========================
lr:1.0000e-03
Epoch: [23][0/200] Loss 0.2779
Epoch: [23][100/200] Loss 0.2001
NMSE 0.2553 ρ 0.863 time 1.128
========================
lr:1.0000e-03
Epoch: [24][0/200] Loss 0.2286
Epoch: [24][100/200] Loss 0.2272
NMSE 0.2539 ρ 0.864 time 0.647
========================
lr:1.0000e-03
Epoch: [25][0/200] Loss 0.2420
Epoch: [25][100/200] Loss 0.2283
NMSE 0.2385 ρ 0.871 time 0.533
========================
lr:1.0000e-03
Epoch: [26][0/200] Loss 0.1934
Epoch: [26][100/200] Loss 0.2241
NMSE 0.2377 ρ 0.871 time 0.531
========================
lr:1.0000e-03
Epoch: [27][0/200] Loss 0.2343
Epoch: [27][100/200] Loss 0.2251
NMSE 0.2111 ρ 0.884 time 0.531
========================
lr:1.0000e-03
Epoch: [28][0/200] Loss 0.1790
Epoch: [28][100/200] Loss 0.1600
NMSE 0.2141 ρ 0.883 time 0.520
========================
lr:1.0000e-03
Epoch: [29][0/200] Loss 0.1748
Epoch: [29][100/200] Loss 0.1895
NMSE 0.2047 ρ 0.888 time 0.562
========================
lr:1.0000e-03
Epoch: [30][0/200] Loss 0.1748
Epoch: [30][100/200] Loss 0.1557
NMSE 0.1984 ρ 0.892 time 0.519
========================
lr:1.0000e-04
Epoch: [31][0/200] Loss 0.1814
Epoch: [31][100/200] Loss 0.2022
NMSE 0.1978 ρ 0.892 time 0.544
========================
lr:1.0000e-04
Epoch: [32][0/200] Loss 0.1897
Epoch: [32][100/200] Loss 0.1875
NMSE 0.1973 ρ 0.893 time 0.514
========================
lr:1.0000e-04
Epoch: [33][0/200] Loss 0.1683
Epoch: [33][100/200] Loss 0.1652
NMSE 0.1970 ρ 0.893 time 0.532
========================
lr:1.0000e-04
Epoch: [34][0/200] Loss 0.2179
Epoch: [34][100/200] Loss 0.1884
NMSE 0.1967 ρ 0.893 time 0.513
========================
lr:1.0000e-04
Epoch: [35][0/200] Loss 0.1835
Epoch: [35][100/200] Loss 0.1834
NMSE 0.1962 ρ 0.893 time 0.618
========================
lr:1.0000e-04
Epoch: [36][0/200] Loss 0.1966
Epoch: [36][100/200] Loss 0.1879
NMSE 0.1959 ρ 0.893 time 0.558
========================
lr:1.0000e-04
Epoch: [37][0/200] Loss 0.1554
Epoch: [37][100/200] Loss 0.2014
NMSE 0.1955 ρ 0.894 time 0.532
========================
lr:1.0000e-04
Epoch: [38][0/200] Loss 0.1609
Epoch: [38][100/200] Loss 0.1458
NMSE 0.1952 ρ 0.894 time 0.611
========================
lr:1.0000e-04
Epoch: [39][0/200] Loss 0.1746
Epoch: [39][100/200] Loss 0.2031
NMSE 0.1949 ρ 0.894 time 0.560
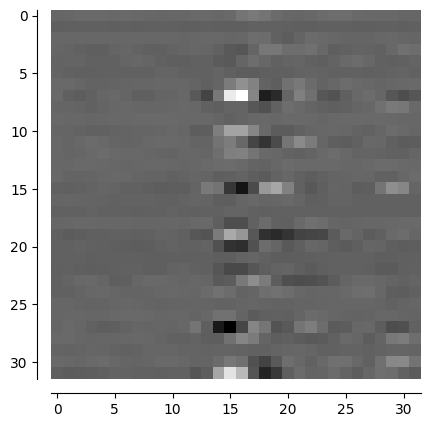
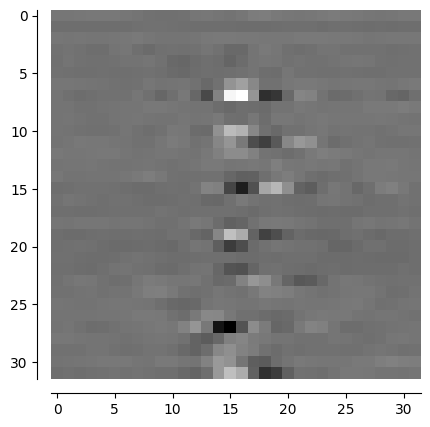
Csi_Net
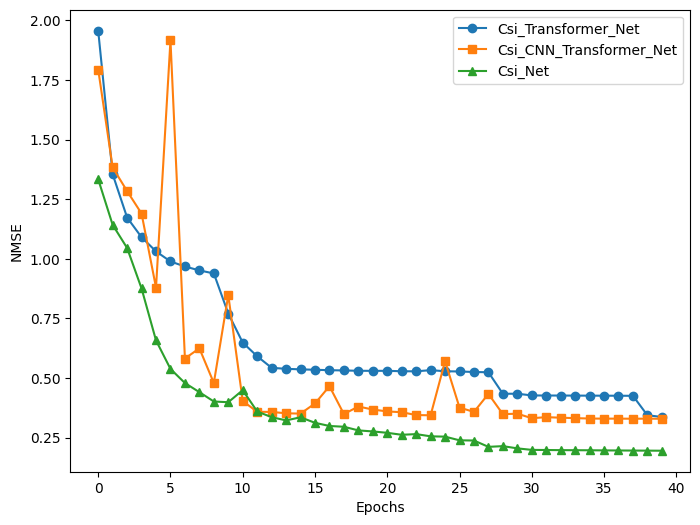
[1.3333566904067993, 1.1422800970077516, 1.0451844179630279, 0.8753661751747132, 0.6575556528568268, 0.5379940551519394, 0.4787355536222458, 0.4405597126483917, 0.40132262706756594, 0.39827447295188906, 0.4489418357610703, 0.3594482445716858, 0.33555667102336884, 0.322117959856987, 0.3350206232070923, 0.31192928612232207, 0.29864764750003814, 0.29539691090583803, 0.2801084813475609, 0.27577628135681154, 0.2699457517266273, 0.2617357462644577, 0.264499531686306, 0.2552609643340111, 0.2539336371421814, 0.2384874066710472, 0.237672161757946, 0.211108820438385, 0.2141134124994278, 0.20471315175294877, 0.1983871877193451, 0.1978167027235031, 0.19734854340553284, 0.19701571255922318, 0.1967495545744896, 0.1962449449300766, 0.19589142352342606, 0.1955234381556511, 0.19522991210222243, 0.1948663568496704]
average time used is: 0.6228328704833984
Saving the entire model...
Model saved to models/Csi_Net_model_128.pth
Model saved!
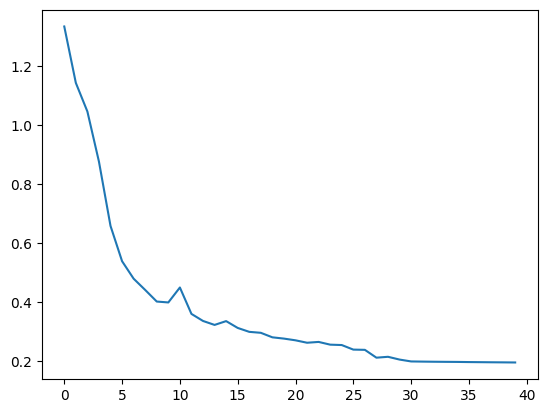
Csi_Transformer_Net
print("="*30)
print("Encoder: transformer; Decoder: transformer")
print("compressed codeword bits: {}".format(bits))
agent1 = model_trainer(epochs=40, net="Csi_Transformer_Net",feedbackbits=bits)
x1, agent1_NMSE, t1 = agent1.model_train()
print("Csi_Transformer_Net")
print(agent1_NMSE)
print("average time used is:", t1)
plt.plot(x1, agent1_NMSE, label="Csi_Transformer_Net")
# 保存模型
model_path = f'models/Csi_Transformer_Net_model_{bits}.pth'
agent1.model_save(model_path)
==============================
Encoder: transformer; Decoder: transformer
compressed codeword bits: 128
loading data...
========================
lr:1.0000e-03
Epoch: [0][0/200] Loss 16.8835
Epoch: [0][100/200] Loss 2.8815
NMSE 1.9566 ρ 0.061 time 1.629
========================
lr:1.0000e-03
Epoch: [1][0/200] Loss 1.9483
Epoch: [1][100/200] Loss 1.5439
NMSE 1.3547 ρ 0.370 time 1.601
========================
lr:1.0000e-03
Epoch: [2][0/200] Loss 1.3673
Epoch: [2][100/200] Loss 1.2373
NMSE 1.1730 ρ 0.497 time 1.647
========================
lr:1.0000e-03
Epoch: [3][0/200] Loss 1.0943
Epoch: [3][100/200] Loss 1.0867
NMSE 1.0903 ρ 0.565 time 1.658
========================
lr:1.0000e-03
Epoch: [4][0/200] Loss 1.0267
Epoch: [4][100/200] Loss 1.0023
NMSE 1.0311 ρ 0.614 time 0.919
========================
lr:1.0000e-03
Epoch: [5][0/200] Loss 1.0738
Epoch: [5][100/200] Loss 0.9662
NMSE 0.9886 ρ 0.622 time 0.737
========================
lr:1.0000e-03
Epoch: [6][0/200] Loss 0.9682
Epoch: [6][100/200] Loss 0.9577
NMSE 0.9677 ρ 0.648 time 0.792
========================
lr:1.0000e-03
Epoch: [7][0/200] Loss 0.8769
Epoch: [7][100/200] Loss 0.9669
NMSE 0.9511 ρ 0.663 time 0.759
========================
lr:1.0000e-03
Epoch: [8][0/200] Loss 0.9183
Epoch: [8][100/200] Loss 0.8877
NMSE 0.9386 ρ 0.662 time 0.894
========================
lr:1.0000e-03
Epoch: [9][0/200] Loss 0.9066
Epoch: [9][100/200] Loss 0.8874
NMSE 0.7703 ρ 0.700 time 0.754
========================
lr:1.0000e-03
Epoch: [10][0/200] Loss 0.7551
Epoch: [10][100/200] Loss 0.6318
NMSE 0.6484 ρ 0.733 time 0.902
========================
lr:1.0000e-03
Epoch: [11][0/200] Loss 0.6150
Epoch: [11][100/200] Loss 0.6004
NMSE 0.5911 ρ 0.756 time 0.774
========================
lr:1.0000e-03
Epoch: [12][0/200] Loss 0.5684
Epoch: [12][100/200] Loss 0.5429
NMSE 0.5425 ρ 0.755 time 0.776
========================
lr:1.0000e-03
Epoch: [13][0/200] Loss 0.5027
Epoch: [13][100/200] Loss 0.5482
NMSE 0.5385 ρ 0.757 time 0.773
========================
lr:1.0000e-03
Epoch: [14][0/200] Loss 0.5368
Epoch: [14][100/200] Loss 0.4899
NMSE 0.5361 ρ 0.760 time 0.761
========================
lr:1.0000e-03
Epoch: [15][0/200] Loss 0.5421
Epoch: [15][100/200] Loss 0.5330
NMSE 0.5345 ρ 0.762 time 0.777
========================
lr:1.0000e-03
Epoch: [16][0/200] Loss 0.4967
Epoch: [16][100/200] Loss 0.5264
NMSE 0.5326 ρ 0.759 time 0.809
========================
lr:1.0000e-03
Epoch: [17][0/200] Loss 0.5447
Epoch: [17][100/200] Loss 0.5212
NMSE 0.5316 ρ 0.767 time 0.911
========================
lr:1.0000e-03
Epoch: [18][0/200] Loss 0.4953
Epoch: [18][100/200] Loss 0.5240
NMSE 0.5301 ρ 0.761 time 0.918
========================
lr:1.0000e-03
Epoch: [19][0/200] Loss 0.4699
Epoch: [19][100/200] Loss 0.5144
NMSE 0.5300 ρ 0.760 time 0.775
========================
lr:1.0000e-03
Epoch: [20][0/200] Loss 0.5295
Epoch: [20][100/200] Loss 0.5224
NMSE 0.5300 ρ 0.761 time 0.792
========================
lr:1.0000e-03
Epoch: [21][0/200] Loss 0.4950
Epoch: [21][100/200] Loss 0.5359
NMSE 0.5283 ρ 0.764 time 0.821
========================
lr:1.0000e-03
Epoch: [22][0/200] Loss 0.5202
Epoch: [22][100/200] Loss 0.5535
NMSE 0.5279 ρ 0.765 time 0.844
========================
lr:1.0000e-03
Epoch: [23][0/200] Loss 0.5108
Epoch: [23][100/200] Loss 0.5283
NMSE 0.5328 ρ 0.750 time 0.785
========================
lr:1.0000e-03
Epoch: [24][0/200] Loss 0.5188
Epoch: [24][100/200] Loss 0.4741
NMSE 0.5282 ρ 0.761 time 0.776
========================
lr:1.0000e-03
Epoch: [25][0/200] Loss 0.4862
Epoch: [25][100/200] Loss 0.4990
NMSE 0.5272 ρ 0.761 time 1.599
========================
lr:1.0000e-03
Epoch: [26][0/200] Loss 0.4873
Epoch: [26][100/200] Loss 0.4856
NMSE 0.5251 ρ 0.764 time 1.647
========================
lr:1.0000e-03
Epoch: [27][0/200] Loss 0.4745
Epoch: [27][100/200] Loss 0.5390
NMSE 0.5240 ρ 0.765 time 1.595
========================
lr:1.0000e-03
Epoch: [28][0/200] Loss 0.4830
Epoch: [28][100/200] Loss 0.3965
NMSE 0.4337 ρ 0.792 time 1.619
========================
lr:1.0000e-03
Epoch: [29][0/200] Loss 0.4264
Epoch: [29][100/200] Loss 0.4338
NMSE 0.4340 ρ 0.784 time 1.655
========================
lr:1.0000e-03
Epoch: [30][0/200] Loss 0.4309
Epoch: [30][100/200] Loss 0.4537
NMSE 0.4268 ρ 0.795 time 1.595
========================
lr:1.0000e-04
Epoch: [31][0/200] Loss 0.4027
Epoch: [31][100/200] Loss 0.4340
NMSE 0.4264 ρ 0.796 time 1.602
========================
lr:1.0000e-04
Epoch: [32][0/200] Loss 0.4187
Epoch: [32][100/200] Loss 0.3953
NMSE 0.4264 ρ 0.794 time 1.624
========================
lr:1.0000e-04
Epoch: [33][0/200] Loss 0.4534
Epoch: [33][100/200] Loss 0.3923
NMSE 0.4260 ρ 0.797 time 1.643
========================
lr:1.0000e-04
Epoch: [34][0/200] Loss 0.3964
Epoch: [34][100/200] Loss 0.4492
NMSE 0.4259 ρ 0.797 time 1.596
========================
lr:1.0000e-04
Epoch: [35][0/200] Loss 0.4250
Epoch: [35][100/200] Loss 0.4602
NMSE 0.4257 ρ 0.797 time 1.619
========================
lr:1.0000e-04
Epoch: [36][0/200] Loss 0.3898
Epoch: [36][100/200] Loss 0.3978
NMSE 0.4255 ρ 0.796 time 1.591
========================
lr:1.0000e-04
Epoch: [37][0/200] Loss 0.3960
Epoch: [37][100/200] Loss 0.3914
NMSE 0.4252 ρ 0.798 time 1.620
========================
lr:1.0000e-04
Epoch: [38][0/200] Loss 0.4531
Epoch: [38][100/200] Loss 0.4079
NMSE 0.3436 ρ 0.836 time 1.630
========================
lr:1.0000e-04
Epoch: [39][0/200] Loss 0.3105
Epoch: [39][100/200] Loss 0.3446
NMSE 0.3365 ρ 0.839 time 1.663
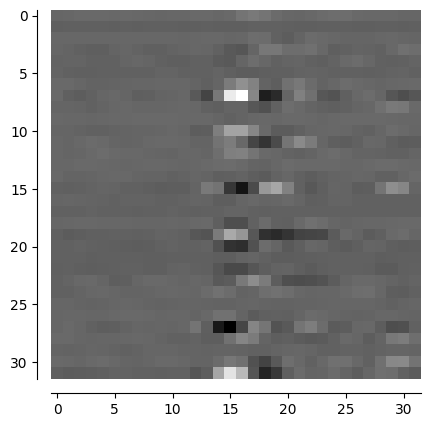

Csi_Transformer_Net
[1.9566105437278747, 1.3546967101097107, 1.1729794073104858, 1.0902969622612, 1.0310835707187653, 0.9886464655399323, 0.967725396156311, 0.9511337721347809, 0.9386063098907471, 0.7703430867195129, 0.6483797013759613, 0.5910915243625641, 0.5425180727243424, 0.5384866672754288, 0.536125123500824, 0.5344688516855239, 0.5326178723573685, 0.5316342955827713, 0.5301343083381653, 0.5299815499782562, 0.5299837756156921, 0.5282985603809357, 0.5278837376832962, 0.5328169310092926, 0.5282338237762452, 0.527239038348198, 0.5250765424966812, 0.523982360959053, 0.4337254935503006, 0.4340094310045242, 0.4267952162027359, 0.42642789661884306, 0.4263604950904846, 0.426031568646431, 0.4258938354253769, 0.4257040703296661, 0.4255121678113937, 0.42521106243133544, 0.34364676058292387, 0.3364664989709854]
average time used is: 1.1970998823642731
Saving the entire model...
Model saved to models/Csi_Transformer_Net_model_128.pth
Model saved!
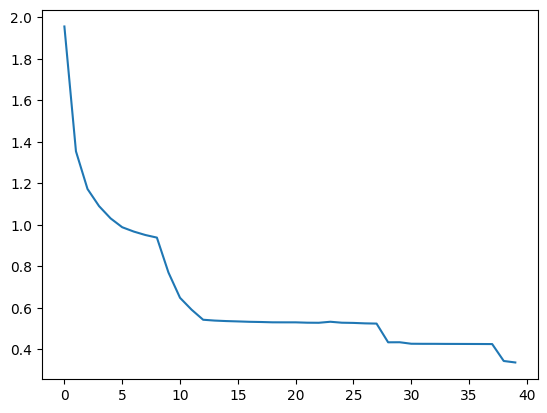
Csi_CNN_Transformer_Net
print("="*30)
print("Encoder: CNN; Decoder: transformer")
print("compressed codeword bits: {}".format(bits))
agent2 = model_trainer(epochs=40, net="Csi_CNN_Transformer_Net",feedbackbits=bits)
x2, agent2_NMSE, t2 = agent2.model_train()
print("Csi_CNN_Transformer_Net")
print(agent2_NMSE)
print("average time used is:", t2)
plt.plot(x2, agent2_NMSE, label="Csi_CNN_Transformer_Net")
print(x2)
plt.show()
# 保存模型
model_path = f'models/Csi_CNN_Transformer_Net_model_{bits}.pth'
agent2.model_save(model_path)
==============================
Encoder: CNN; Decoder: transformer
compressed codeword bits: 128
loading data...
========================
lr:1.0000e-03
Epoch: [0][0/200] Loss 16.7723
Epoch: [0][100/200] Loss 2.7850
NMSE 1.7937 ρ 0.337 time 0.447
========================
lr:1.0000e-03
Epoch: [1][0/200] Loss 1.8238
Epoch: [1][100/200] Loss 1.4794
NMSE 1.3830 ρ 0.503 time 0.437
========================
lr:1.0000e-03
Epoch: [2][0/200] Loss 1.2672
Epoch: [2][100/200] Loss 1.2981
NMSE 1.2839 ρ 0.556 time 0.449
========================
lr:1.0000e-03
Epoch: [3][0/200] Loss 1.1113
Epoch: [3][100/200] Loss 1.1200
NMSE 1.1895 ρ 0.638 time 0.518
========================
lr:1.0000e-03
Epoch: [4][0/200] Loss 1.1125
Epoch: [4][100/200] Loss 1.1114
NMSE 0.8790 ρ 0.593 time 0.876
========================
lr:1.0000e-03
Epoch: [5][0/200] Loss 0.8571
Epoch: [5][100/200] Loss 0.6774
NMSE 1.9164 ρ 0.755 time 0.913
========================
lr:1.0000e-03
Epoch: [6][0/200] Loss 0.6592
Epoch: [6][100/200] Loss 0.5653
NMSE 0.5816 ρ 0.758 time 0.912
========================
lr:1.0000e-03
Epoch: [7][0/200] Loss 0.5619
Epoch: [7][100/200] Loss 0.5827
NMSE 0.6244 ρ 0.668 time 0.936
========================
lr:1.0000e-03
Epoch: [8][0/200] Loss 0.5068
Epoch: [8][100/200] Loss 0.5359
NMSE 0.4789 ρ 0.800 time 0.916
========================
lr:1.0000e-03
Epoch: [9][0/200] Loss 0.4513
Epoch: [9][100/200] Loss 0.4735
NMSE 0.8477 ρ 0.827 time 0.963
========================
lr:1.0000e-03
Epoch: [10][0/200] Loss 0.4208
Epoch: [10][100/200] Loss 0.4186
NMSE 0.4033 ρ 0.837 time 0.928
========================
lr:1.0000e-03
Epoch: [11][0/200] Loss 0.3055
Epoch: [11][100/200] Loss 0.3709
NMSE 0.3582 ρ 0.810 time 0.934
========================
lr:1.0000e-03
Epoch: [12][0/200] Loss 0.3048
Epoch: [12][100/200] Loss 0.3369
NMSE 0.3576 ρ 0.809 time 0.922
========================
lr:1.0000e-03
Epoch: [13][0/200] Loss 0.3596
Epoch: [13][100/200] Loss 0.3335
NMSE 0.3518 ρ 0.817 time 0.906
========================
lr:1.0000e-03
Epoch: [14][0/200] Loss 0.3324
Epoch: [14][100/200] Loss 0.3278
NMSE 0.3506 ρ 0.827 time 0.891
========================
lr:1.0000e-03
Epoch: [15][0/200] Loss 0.3422
Epoch: [15][100/200] Loss 0.3615
NMSE 0.3930 ρ 0.776 time 0.901
========================
lr:1.0000e-03
Epoch: [16][0/200] Loss 0.3087
Epoch: [16][100/200] Loss 0.3223
NMSE 0.4655 ρ 0.850 time 0.909
========================
lr:1.0000e-03
Epoch: [17][0/200] Loss 0.3008
Epoch: [17][100/200] Loss 0.3295
NMSE 0.3486 ρ 0.829 time 0.983
========================
lr:1.0000e-03
Epoch: [18][0/200] Loss 0.3196
Epoch: [18][100/200] Loss 0.3202
NMSE 0.3803 ρ 0.785 time 0.866
========================
lr:1.0000e-03
Epoch: [19][0/200] Loss 0.3409
Epoch: [19][100/200] Loss 0.3137
NMSE 0.3677 ρ 0.841 time 0.924
========================
lr:1.0000e-03
Epoch: [20][0/200] Loss 0.3369
Epoch: [20][100/200] Loss 0.3256
NMSE 0.3596 ρ 0.802 time 0.866
========================
lr:1.0000e-03
Epoch: [21][0/200] Loss 0.3814
Epoch: [21][100/200] Loss 0.3145
NMSE 0.3564 ρ 0.838 time 0.468
========================
lr:1.0000e-03
Epoch: [22][0/200] Loss 0.3593
Epoch: [22][100/200] Loss 0.3371
NMSE 0.3445 ρ 0.820 time 0.553
========================
lr:1.0000e-03
Epoch: [23][0/200] Loss 0.3151
Epoch: [23][100/200] Loss 0.3410
NMSE 0.3434 ρ 0.824 time 0.917
========================
lr:1.0000e-03
Epoch: [24][0/200] Loss 0.3600
Epoch: [24][100/200] Loss 0.3348
NMSE 0.5701 ρ 0.855 time 0.927
========================
lr:1.0000e-03
Epoch: [25][0/200] Loss 0.3392
Epoch: [25][100/200] Loss 0.2966
NMSE 0.3758 ρ 0.846 time 0.916
========================
lr:1.0000e-03
Epoch: [26][0/200] Loss 0.3510
Epoch: [26][100/200] Loss 0.3204
NMSE 0.3577 ρ 0.802 time 0.917
========================
lr:1.0000e-03
Epoch: [27][0/200] Loss 0.3344
Epoch: [27][100/200] Loss 0.3121
NMSE 0.4332 ρ 0.853 time 0.930
========================
lr:1.0000e-03
Epoch: [28][0/200] Loss 0.3257
Epoch: [28][100/200] Loss 0.3527
NMSE 0.3482 ρ 0.841 time 0.907
========================
lr:1.0000e-03
Epoch: [29][0/200] Loss 0.3031
Epoch: [29][100/200] Loss 0.3429
NMSE 0.3503 ρ 0.808 time 0.913
========================
lr:1.0000e-03
Epoch: [30][0/200] Loss 0.3269
Epoch: [30][100/200] Loss 0.3412
NMSE 0.3313 ρ 0.830 time 0.920
========================
lr:1.0000e-04
Epoch: [31][0/200] Loss 0.3079
Epoch: [31][100/200] Loss 0.3284
NMSE 0.3356 ρ 0.841 time 0.924
========================
lr:1.0000e-04
Epoch: [32][0/200] Loss 0.3316
Epoch: [32][100/200] Loss 0.3002
NMSE 0.3334 ρ 0.824 time 0.919
========================
lr:1.0000e-04
Epoch: [33][0/200] Loss 0.3063
Epoch: [33][100/200] Loss 0.2999
NMSE 0.3316 ρ 0.838 time 0.920
========================
lr:1.0000e-04
Epoch: [34][0/200] Loss 0.3269
Epoch: [34][100/200] Loss 0.3275
NMSE 0.3298 ρ 0.831 time 0.918
========================
lr:1.0000e-04
Epoch: [35][0/200] Loss 0.3314
Epoch: [35][100/200] Loss 0.3247
NMSE 0.3295 ρ 0.834 time 0.921
========================
lr:1.0000e-04
Epoch: [36][0/200] Loss 0.2935
Epoch: [36][100/200] Loss 0.3160
NMSE 0.3294 ρ 0.835 time 0.922
========================
lr:1.0000e-04
Epoch: [37][0/200] Loss 0.2945
Epoch: [37][100/200] Loss 0.3379
NMSE 0.3291 ρ 0.835 time 0.917
========================
lr:1.0000e-04
Epoch: [38][0/200] Loss 0.2834
Epoch: [38][100/200] Loss 0.3184
NMSE 0.3293 ρ 0.830 time 0.907
========================
lr:1.0000e-04
Epoch: [39][0/200] Loss 0.3403
Epoch: [39][100/200] Loss 0.3393
NMSE 0.3288 ρ 0.831 time 0.896
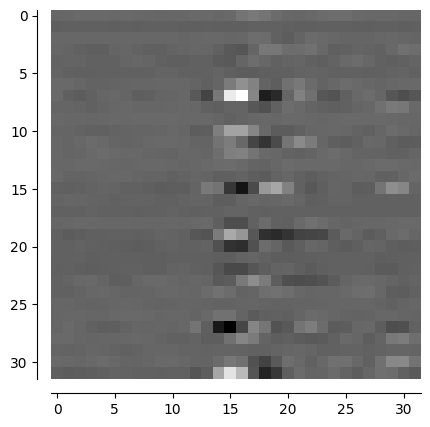
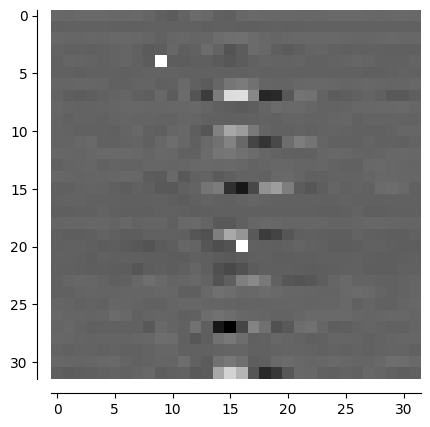
Csi_CNN_Transformer_Net
[1.7936574721336365, 1.3829833745956421, 1.283927230834961, 1.1894978594779968, 0.8790475904941559, 1.9164495015144347, 0.5816227388381958, 0.6243553447723389, 0.4789328819513321, 0.8476968479156494, 0.4033376920223236, 0.3581970351934433, 0.3575852298736572, 0.3518389576673508, 0.350602548122406, 0.3930432403087616, 0.46549117743968965, 0.3486467313766479, 0.3802634757757187, 0.36765024840831756, 0.3596446371078491, 0.35639182686805726, 0.34447405755519866, 0.34342944622039795, 0.5701418870687485, 0.3757738322019577, 0.35769821345806124, 0.4331714022159576, 0.34818855822086336, 0.35026067614555356, 0.3313265132904053, 0.3355947732925415, 0.33339386343955996, 0.33157447040081023, 0.3298351740837097, 0.3294666814804077, 0.32943468272686005, 0.32912233233451843, 0.3293388104438782, 0.3288260215520859]
average time used is: 0.850273048877716
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39]
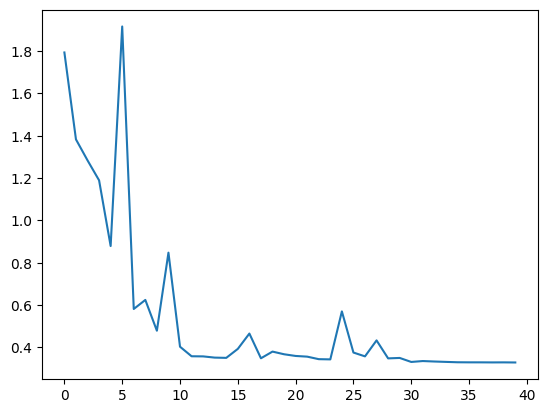
Saving the entire model...
Model saved to models/Csi_CNN_Transformer_Net_model_128.pth
Model saved!
import matplotlib.pyplot as plt
# 假设你有三个网络的损失函数结果
# 创建一个图形
plt.figure(figsize=(8, 6))
# 绘制第一个网络的损失函数曲线
plt.plot(x1, agent1_NMSE, label="Csi_Transformer_Net", marker='o')
# 绘制第二个网络的损失函数曲线
plt.plot(x2, agent2_NMSE, label="Csi_CNN_Transformer_Net", marker='s')
# 绘制第三个网络的�损失函数曲线
plt.plot(x3, agent3_NMSE, label="Csi_Net", marker='^')
# plt.plot(x3, (np.array(agent3_NMSE) - 0.2) * 2 / 2.6 + 0.5, label="Csi_Net")
# 设置标题、坐标轴标签和图例
plt.xlabel("Epochs")
plt.ylabel("NMSE")
plt.legend()
# 显示图形
plt.show()
CS_Net
# print("="*30)
# print("Encoder: Random Projection; Decoder: CNN")
# print("compressed codeword bits: {}".format(bits))
# agent4 = model_trainer(epochs=40, net="CS_Net",feedbackbits=bits)
# x4, agent4_NMSE= agent4.model_train()
# print("CS_Net")
# print(agent4_NMSE)
# plt.plot(x4, agent4_NMSE, label="CS_Net")
# # 保存模型
# model_path = f'models/CS_Net_model_{bits}.pth'
# agent4.model_save(model_path)