Kimi K2
Agent RL 相关内容
Introduce
这一部分指出当前 Agent 训练存在核心挑战(后训练挑战:多步推理、长期规划和工具使用等主体能力在自然数据中罕见且扩展成本高昂),引出 Kimi K2 专门设计以应对核心挑战并推动代理能力的边界。
介绍了训练模型之前会有一个大规模的自主数据合成管道,通过模拟和现实环境系统性地生成工具使用示范。该系统构建了多样化的工具、代理、任务和轨迹,以大规模创建高保真、可验证正确的自主交互。
同时秀肌肉(图一展示了 8 个表格,有一半是评估 agent 能力的,可见这个模型对于 agent 能力的重视):
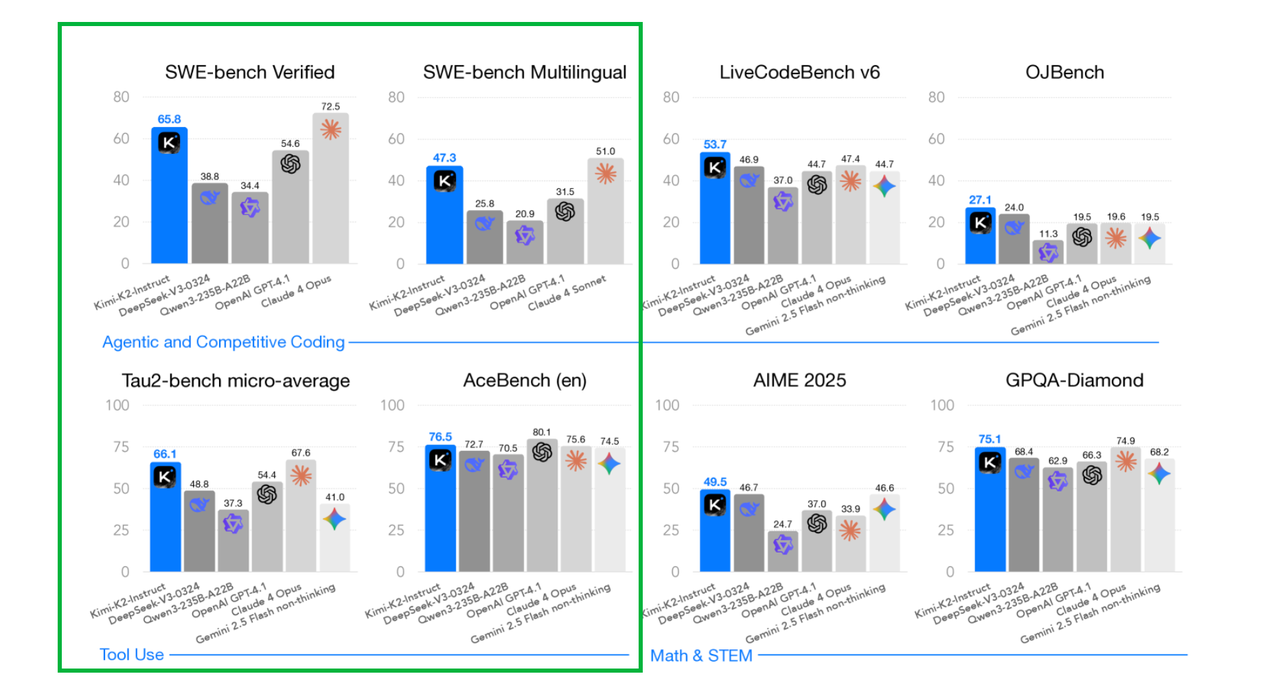
展示的这几个榜单如下
Post-Training
数据合成流水线
Agent 数据合成流水线(开发了一套流水线,能够大规模模拟现实工具使用场景,从而生成数万条多样且高质量的训练样本)
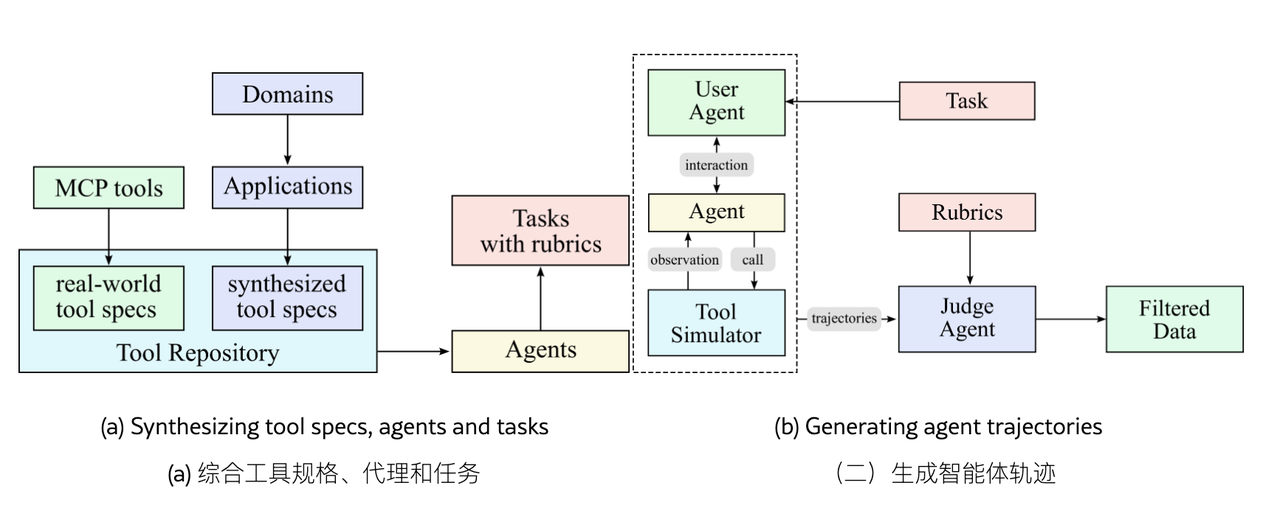
-
工具规格生成:我们首先从现实世界工具和 LLM 合成工具中构建一个大型工具规格库
-
在 Kimi K2 的技术报告中,“工具规格生成”(Tool Spec Generation)是构建智能体(Agent)能力的基石。简单来说,这步工作的目标是给模型准备一本“工具大百科全书”,让它知道世界上有哪些工具、这些工具怎么用。
-
真实工具:3000+ MCP 工具的“实战库”
-
什么是 MCP?:MCP 全称是 Model Context Protocol(模型上下文协议),这是一种标准化的接口协议,由 Anthropic 等公司发起,旨在让 AI 模型更方便地连接外部数据和工具
-
获取方式:团队从 GitHub 仓库中直接抓取了 3000 多个现成的、高质量的工具定义
-
意义:这些工具来自于真实的开发者需求(比如查询实时天气、读写本地文件、调用特定的 API),确保了模型学习到的工具使用逻辑是 符合现实世界规范 的
-
-
合�成工具:20,000+ 工具的“演化工厂(由于真实世界的工具虽然真实,但可能在某些领域(如极端边界情况)覆盖不足,团队使用了 LLM 自行生成了海量的“合成工具”)
-
分层领域生成 (Hierarchical Domain Generation):这是一个由面到点的过程
-
第一步:确定大类。比如选定“金融交易”、“机器人控制”、“软件应用”等关键类别 ()
-
第二步:细化领域。在每个大类下,进一步演化出更具体的应用场景
-
第三步:合成工具。为每个场景设计具体的工具接口、功能描述以及操作语义
-
-
意义:这种方式产生了超过 20,000 个合成工具,极大地扩展了工具的 多样性,弥补了自然数据稀缺的不足
-
-
来源多样化:为什么需要 23,000 个这么多?
-
互补性:技术报告中的 t-SNE 可视化图表显示,真实工具(MCP)和合成工具在功能分布上是互补的 。真实工具提供真实感,合成工具提供系统性的空间覆盖。
-
泛化能力:只有见过足够多、足够怪的工具(通过合成工具模拟各种失败和边界情况),模型在遇到用户给出的 从未见过的新工具 时,才能根据工具文档准确判断如何调用
-
-
-
-
代理和任务生成:对于从工具库中抽取的每个工具集,我们生成一个使用该工具集的代理及一些相应的任务
-
在 Kimi K2 的数据合成流水线中,智能体与任务生成(Agent and Task Generation) 紧接在“工具仓库构建”之后。如果说工具是“武器”,那么这一步就是为了创造出各式各样的“士兵”(智能体)并给他们布置具体的“战场任务”
-
智能体多样化:创造数千个“数字专家”(为了让模型学会处理各行各业的复杂指令,研发团队不仅仅是把工具丢给模型,而是通过“角色扮演”的方式将工具与特定的专业背景结合)
-
系统提示词(System Prompts)的组合:团队合成了成千上万种不同的系统提示词,用来定义智能体的身份、语气、专业知识范围和行为准则 ()
-
工具集的差异化分配:从包含 23,000 个工具的仓库中随机采样不同的子集,装备给不同的智能体 ()()()
-
结果:生成了数千个具有独特“行为模式”的智能体 ()。例如:
-
智能体 A 可能是一个 财务分析师,装备了查询股价、读财报和计算收益的工具,其行为模式设定为专业且严谨。
-
智能体 B 可能是一个 智能家居助手,装备了控制灯光、查询天气和播放音乐的工具,其行为模式设定为亲切且高效
-
-
-
基于规则的任务生成:设计“阶梯式”考卷
-
从简单到复杂的演进(Curriculum Design):为每个智能体配置的任务涵盖了不同的难度等级 (单步任务到复杂任务)
-
配备明确的评估准则(Rubrics):这是 Kimi K2 的关键创新。每个任务在生成时,都会自动配一套“评分标准”
-
成功标准:规定最终结果必须达到什么要求(例如,财务报表必须包含特定的百分比数据
-
预期工具使用模式:规定智能体应该按什么逻辑调用工具,不该调用哪些工具
-
评估检查点:在复杂的长任务中设置中间步骤的验证点
-
-
-
-
-
轨迹生成:对于每个代理和任务,我们生成代理通过调用工具完成任务的轨迹。
-
这部分内容描述了 Kimi K2 如何生成能够让模型学习的“实战经验”。在有了工具和任务后,模型需要通过实际的交互来学习如何应对各种复杂情况。
-
多智能体模拟:模拟真实的对话环境
-
用户智能体 (User Agent):由大模型扮演不同的用户角色(User Personas),它们拥有独特的沟通风格和偏好
-
多轮互动:用户智能体会提出要求,并与助理智能体进行多轮对话,创造出自然且真实的交互模式
-
-
混合环境执行:提供真实的反馈机制
-
工具模拟器 (Tool Simulator):
-
定位:这是一个功能等同于“世界模型”的模拟器,负责执行工具调用并提供反馈
-
持久化状态:模拟器会在每次工具执行后更新并保持状态,从而支持连续的多步交互
-
引入随机性:为了让模型更健壮,模拟器会受控地引入随机性,生成 成功、部分失败或边界情况(Edge Cases)等不同结果,迫使智能体学习错误恢复能力
-
-
真实沙箱 (Real Execution Sandboxes)
-
适用场景:主要用于对真实性要求极高的代码编写和软件工程任务
-
基础设施:基于 Kubernetes 构建,支持超过 10,000 个并发实例,具备高扩展性和安全性
-
客观评价:在真实环境下运行代码,通过 测试套件通过率 等客观指标获取最真实的结果反馈
-
-
-
质量守门人:严苛的数据筛选
-
LLM 评委 (LLM-based Judge):使用一个专门的大模型担任“考官”,对照之前预设的任务评估准则(Rubrics)对整个交互轨迹进行打分
-
拒绝采样 (Rejection Sampling):只有那些完全通过评估准则、成功完成任务的轨迹才会被保留用于后续训练
-
-
-
RL
奖励信号设计
针对 Agent 任务设计了一些奖励信号
-
忠实度 (Faithfulness)
-
核心定义:模型在生成回答(尤其是多轮工具使用或长文本分析)时,必须确保每一句话都能在给定的上下文或工具反馈中找到明确依据,绝不“脑补”
-
论文中的技术实现: K2 训练了一个专门的“句子级判官模型”。它会将模型的回复拆解成独立的单句,逐一核实:这句话是否有据可查?
-
-
代码与软件工程
-
核心定义:模型不仅是“写代码”,而是作为一个“智能体”在真实的开发环境(沙箱)中解决复杂的工程问题。
-
论文中的技术实现: K2 利用 GitHub 上的真实 Issue(议题)和 Pull Request(拉取请求)构建了一个可执行的训练环境。它不仅有代码,还有完整的“测试套件”和“运行沙箱”
-
场景:系统给 K2 指派了一个任务——修复一个开源�计算器项目中“除以 0 时程序会直接崩溃”的 Bug
-
任务开始:K2 并不是直接吐出一行
if (x == 0),而是首先调用工具查看整个项目的目录结构,寻找处理运算逻辑的文件 -
沙箱操作:它会在基于 Kubernetes 的安全沙箱中,像人类程序员一样在终端输入指令,尝试复现这个崩溃
-
代码修改与验证:K2 修改了代码后,必须自己运行项目原有的 单元测试(Unit Tests)。如果修改后虽然除以 0 不崩溃了,但导致加法算错了(即未通过旧的测试),那么它无法获得奖励。
-
奖励获取:只有当 K2 提交的补丁(Patch)通过了所有测试用例,证明它既解决了新问题又没破坏旧功能时,它才能在强化学习中获得高分。这解释了为什么 K2 在处理真实世界的软件仓库问题(如 SWE-bench 评测)时表现出色。
-
-
疑问
Kimi k2 论文里面的奖励信号设计分了几个部分,但是我不清楚为什么把忠实度评测与代码软件工程放在同一个维度,这样写似乎有点奇怪。我的代码软件工程的 agent 任务中,不能进行忠实度评测嘛?或者说这个忠实度评测是单独的一个领域?

RL 算法
RL 目标函数
Kimi K2 沿用了 K1.5 中的策略优化算法 (1)。其核心目标函数如下:
公式各项的含义:
-
:从训练集中抽取的某个问题(提示词) (2)。
-
:对于同一个问题,模型生成的回答数量 (3)。
-
:第 个由旧模型()生成的回答 (4)。
- 是旧模型生成回答的原因:off policy?infra上的训推分离?
-
:相对奖励值。其中 是当前回答的奖励分, 是 个回答的平均分 (5)。这一项的逻辑是:如果一个回答比其他回答都要好(高于平均水平),模型就应该学习它;如果低于平均水平,就应该抑制它。
-
:KL 散度约束项。 是调节系数, 是正在训练的新模型, 是原有的旧模型 (6)。
- 作用:防止新模型为了追求高分而变得过于激进,导致回答变得“怪异”或偏离人类语��言逻辑 (7)。它强迫新模型在改进性能的同时,不要离旧模型的基础能力太远。
-
(平方损失):这是一个回归式的设计。目标是让模型通过调整参数,使得其输出分布的变动量与获得的奖励信号达成一致 (8)。
预算控制 (Budget Control)
人们广泛观察到,RL 通常会导致模型生成的回答长度大幅增加 [35, 19] ()。虽然较长的回答可以让模型利用更多的测试时计算来提升复杂推理任务的表现,但这种收益往往无法抵消其在非推理领域的推理成本 ()。为了鼓励模型合理分配推理预算,我们在整个 RL 训练过程中强制执行针对每个样本的最大 Token 预算,该预算根据任务类型确定 ()。超过此 Token 预算的回答将被截断并被赋予惩罚,从而激励模型在指定限制内生成解决方案 ()。
PTX 损失 (PTX Loss)
为了防止在联合 RL 训练期间遗忘有价值的高质量数据,我们策划了一个由手工挑选的高质量样本组成的数据集,并通过辅助 PTX 损失 [54] 将其整合到 RL 目标中 ()。这一策略不仅利用了高质量数据的优势,还减轻了模型对训练方案中明确存在的有限任务集产生过拟合的风险 ()
-
精心挑选数据集:研发团队策划了一个包含“手工挑选、高质量样本”的专用数据集 ()()。这些数据通常代表了模型最核心的通用语言能力
-
整合进目标函数:在 RL 训练的每一步,模型不仅计算上述的奖励函数损失,还会同时在这些“高质量预训练数据”上计算一个传统的语言建模损失(即 PTX 损失)
温度衰减 (Temperature Decay)
对于创意写作和复杂推理等任务,我们发现在训练初期通过高采样温度来促进探索至关重要 ()。高温度允许模型生成多样化且创新的回答,从而有助于发现有效的策略并降低过早收敛到次优解的风险 ()。然而,在训练后期或评估期间保持高温度可能是有害的,因为它会引入过多的随机性,并损害模型输出的可靠性和一致性 ()。为了解决这个问题,我们采用温度衰减计划,在整个训练过程中从探索转向利用 ()。
总结
Kimi K2 的发布标志着从静态模仿学习向智能体智能(Agentic Intelligence)的范式转移 。相比主要关注强化学习(RL)规模化缩放的 K1.5,K2 针对智能体在复杂动态环境中的感知、规划与执行能力进行了专项攻坚。
该技术报告的核心贡献主要集中在以下两个维度:
一、 优化器创新:MuonClip 兼顾效率与稳定
报告通过严密的数学公式和丰富的消融实验,解决了大规模训练中的不稳定性问题:
二、 智能体能力建设:数据合成与精准对齐
K2 的智能体建设是一项系统工程,解决了“高质量数据稀缺”和“复杂行为难以评价”的痛点
另外:在 RL 部分使用的一些 trick 也值得学习(预算控制,PTX,温度衰减)