认知负荷是关键
非常建议直接读原文
介绍
现在有很多流行语和最佳实践,但让我们关注一些更基本的东西。重要的是,开发人员在阅读代码时会感到多少困惑。
混乱会耗费时间和金钱。混乱是由高认知负荷引起的。这不是一些花哨的抽象概念,而是人类的基本约束。
因为我们花在阅读和理解代码上的时间远远多于写代码的时间,所以我们应该不断地问自己是否在代码中嵌入了过多的认知负荷。

认知负荷
认知负荷是指开发人员为完成一项任务需要思考的程度。
阅读代码时,您会将变量值、控制流逻辑和调用序列等内容放入脑海中。一般人的工作记忆中可以容纳大约四个这样的块。一旦认知负荷达到这个阈值,理解事物就会变得更加困难。
*比方说�,我们被要求对一个完全陌生的项目进行一些修正。我们被告知,一位非常聪明的开发人员为该项目做出了贡献。他使用了很多很酷的架构、花哨的库和时髦的技术。换句话说,作者为我们创造了很高的认知负荷。
我们应尽可能减少项目中的认知负荷。
认知负荷的类型
内在 - 由任务的内在难度造成。它无法降低,是软件开发的核心。
外来 - 信息呈现方式造成的。由与任务无直接关系的因素造成,如聪明的作者的怪癖。可以大大减少。我们将重点讨论这类认知负荷。
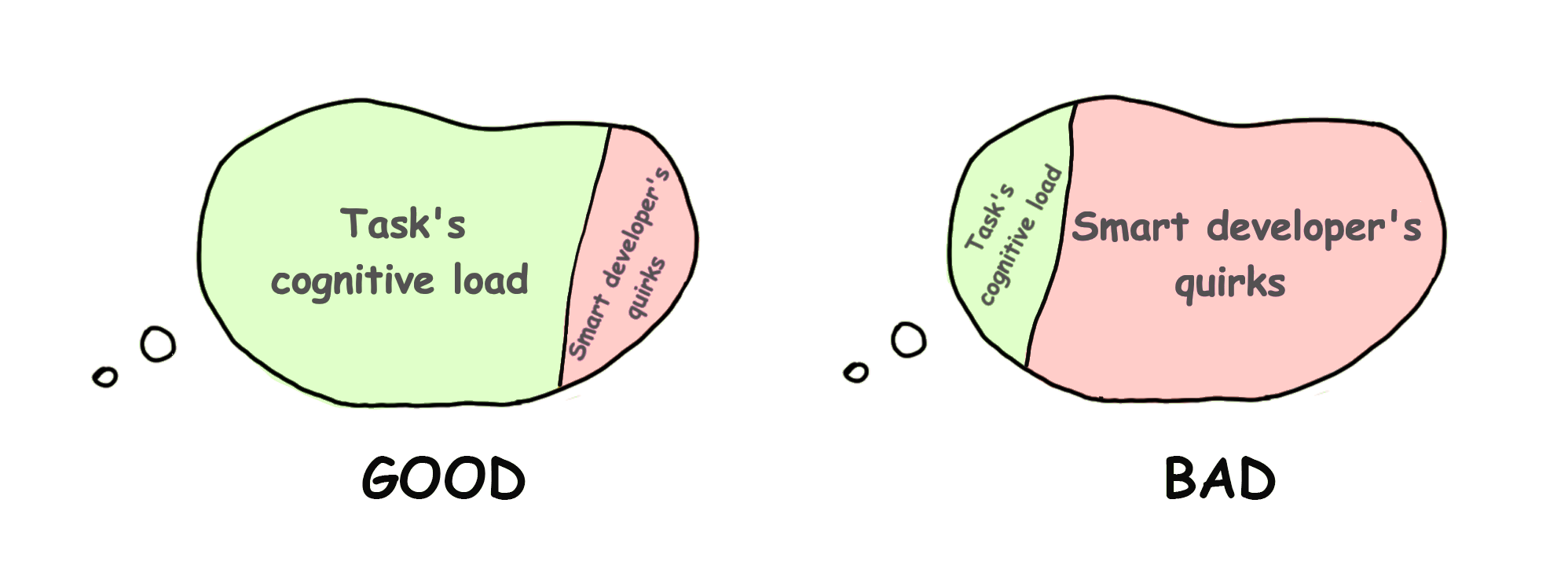
让我们直接跳到无关认知负荷的具体实例。
我们将认知负荷水平称为如下:
🧠:新鲜工作记忆,零认知负荷
🧠++:我们工作记忆中的两个事实,认知负荷增加
🤯:工作记忆溢出,超过 4 个事实
我们的大脑要复杂得多且未经探索,但我们可以采用这个简单化的模型。
复杂条件句
if val > someConstant // 🧠+
&& (condition2 || condition3) // 🧠+++, prev cond should be true, one of c2 or c3 has be true
&& (condition4 && !condition5) { // 🤯, we are messed up by this point
...
}
引入具有有意义名称的中间变量:
isValid = val > someConstant
isAllowed = condition2 || condition3
isSecure = condition4 && !condition5
// 🧠, we don't need to remember the conditions, there are descriptive variables
if isValid && isAllowed && isSecure {
...
}
嵌套 if
if isValid { // 🧠+, okay nested code applies to valid input only
if isSecure { // 🧠++, we do stuff for valid and secure input only
stuff // 🧠+++
}
}
与早期回报进行比较:
if !isValid
return
if !isSecure
return
// 🧠, we don't really care about earlier returns, if we are here then all good
stuff // 🧠+
我们可以只专注于快乐的道路,从而将我们的工作记忆从各种先决条件中解放出来。
继承噩梦
我们被要求为我们的管理员用户更改一些内容:🧠
AdminController 扩展了 UserController 扩展了 GuestController 扩展了 BaseController
- 部分功能在
BaseController中,让我们看一下:🧠+ - 在
GuestController中引入了基本角色机制:🧠++ - 在
UserController中进行了部分更改:🧠+++ - 终于到了,
AdminController,让我们编写代码吧!🧠++++ - 等等,有一个扩展了“AdminController”的“SuperuserController”。通过修改“AdminController”,我们可以破坏继承类中的内容,所以让我们首先深入了解“SuperuserController”:“🤯”
优先选择组合而不是继承。
太多的小方法、类或模块
方法、类和模块在这种情况下是可以互换的
诸如“方法应该少于 15 行代码”或“类应该很小”之类的咒语被证明是有些错误的。
深层模块 - 界面简单,功能复杂
浅层模块 - 界面相对于它提供的小功能来说相对复杂
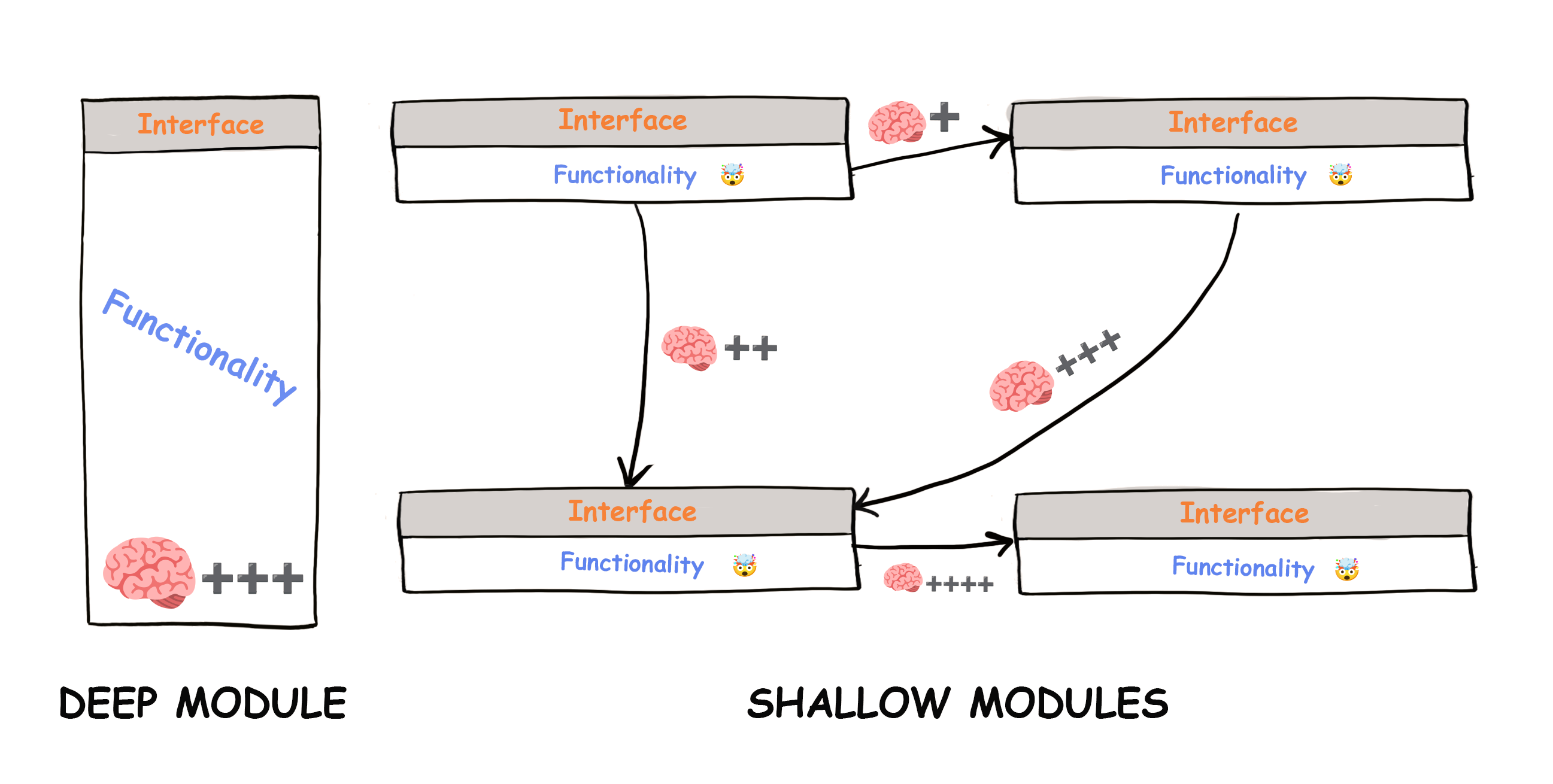
过多的浅层模块会使项目难以理解。 我们不仅要牢记每个模块的职责,还要牢记它们所有的交互。要��理解浅层模块的用途,我们首先需要查看所有相关模块的功能。 🤯
信息隐藏至关重要,我们不会在浅层模块中隐藏太多复杂性。
我有两个喜欢的项目,它们都有 5K 行代码。第一个有 80 个浅层类,而第二个只有 7 个深层类。我已经一年半没有维护任何这些项目了。
回来后,我意识到在第一个项目中理清这 80 个类之间的所有交互是极其困难的。在开始编码之前,我必须重建大量的认知负荷。另一方面,我能够很快掌握第二个项目,因为它只有几个深层类和一个简单的接口。
最好的组件是那些提供强大功能但界面简单的组件。 --约翰·K·奥斯特豪特
UNIX I/O 的接口非常简单。它只有五个基本调用:
open(path, flags, permissions)
read(fd, buffer, count)
write(fd, buffer, count)
lseek(fd, offset, referencePosition)
close(fd)
该接口的现代实现有数十万行代码。许多复杂性隐藏在幕后。然而,由于其简单的界面,它很容易使用。
这个深层模块示例取自 John K. Ousterhout 所著的《软件设计哲学》一书。本书不仅涵盖了软件开发中复杂性的本质,而且还对Parnas颇具影响力的论文On the Criteria To Be Use in Decomusing Systems into Modules。两者都是必备读物。其他相关阅读:可能是时候停止推荐干净代码了、[被认为有害的小函数](https://copyconstruct.medium.com/small-functions-considered-harmful -91035d316c29)。
附:如果你认为我们支持臃肿的上帝对象和太多的责任,那你就错了。
浅层模块和 SRP
很多时候,我们最终会创建大量浅层模块,遵循一些模糊的“一个模块应该负责一个且只负责一个事物”的原则。这模糊的一件事是什么?实例化一个对象是一回事,对吧?所以 MetricsProviderFactoryFactory 似乎就很好。这些类的名称和接口往往比它们的整个实现更费脑力,那是一种什么样的抽象?出了点问题。
在如此浅层的组件之间跳转也很费脑力,线性思维对我们人类来说更自然。
我们对系统进行更改以满足我们的用户和利益相关者的需求。我们对他们负责。
一个模块应该对一个且仅对一个用户或利益相关者负责。
这就是单一责任原则的全部内容。简单来说,如果我们在一个地方引入了一个bug,然后两个不同的业务人员来抱怨,我们就违反了原则。它与我们在模块中所做的事情的数量无关。
但即使是现在,这种解释也弊大于利。这条规则可以以多种不同的方式来理解,就像有多少个人一样。更好的方法是看看这一切会产生多少认知负荷。记住一个模块的变化可能会在不同的业务流中引发一系列反应,这对心理上的要求很高。就是这样。
太多浅层微服务
这种浅深模块原则与规模无关,我们可以将其应用到微服务架构中。太多的浅层微服务不会有任何好处——行业正在走向某种程度的“宏观服务”,即不那么浅层(=深层)的服务。最糟糕和最难修复的现象之一是所谓的分布式整体,这通常是这种过于细粒度的浅层分离的结果。
我曾经咨询过一家初创公司,该公司的 5 名开发人员团队引入了 17 个(!)微服务。它们比原计划晚了 10 个月,而且距离公开发布还差得很远。每一个新需求都会导致 4 个以上微服务的变化。集成空间的诊断难度急剧上升。上市时间和认知负荷都高得令人无法接受。 🤯
这是处理新系统不确定性的正确方法吗?一开始就很难得出正确的逻辑界限。关键是在负责任地等待的时间内尽可能晚地做出决定,因为那时你拥有最多的信息来做出决定。通过预先引入网络层,我们的设计决策很难从一开始就恢复。该团队唯一的理由是:“FAANG 公司证明了微服务架构是有效的”。 你好,你不能再做大梦了。
Tanenbaum-Torvalds 辩论 认为 Linux 的整体设计是有缺陷且过时的,应该使用微内核架构来代替。事实上,“从理论和美学”的角度来看,微内核设计似乎更优越。从实际情况来看,三十年过去了,基于微内核的 GNU Hurd 仍在开发中,而整体 Linux 已经无处不在。此页面由 Linux 提供支持,您的智能茶壶由 Linux 提供支持。通过单片Linux。
具有真正隔离模块的精心设计的整体通常比一堆微服务灵活得多。它还需要更少的认知努力来维持。只有当单独部署的需求变得至关重要时(例如扩展开发团队),您才应该考虑在模块和未来的微服务之间添加网络层。
功能丰富的语言
当我们喜爱的语言发布新功能时,我们会感到兴奋。我们花一些时间学习这些功能,并在此基础上编写代码。
如果有很多功能,我��们可能要花半小时来处理几行代码,以使用这样或那样的功能。这有点浪费时间。但更糟糕的是,当你稍后再回来时,你将不得不重新经历那个思考过程!
你不仅要理解这个复杂的程序,还要理解为什么程序员决定用这种方法来解决现有功能中的问题。🤯
发表这些言论的不是别人,正是罗伯-派克。
通过限制选择数量来减少认知负荷。
只要语言特征是相互正交的,就没有问题。
一位拥有20年C++经验的工程师的想法️⭐️:
前几天,我在看我的 RSS 阅读器时发现,我的 "C++"标签下有三百多篇未读文章。从去年夏天到现在,我一篇关于 C++ 语言的文章都没读过,感觉好极了!
我使用 C++ 已经有 20 年了,这几乎是我人生的三分之二的时间。我的大部分经验都在于处理语言中最黑暗的角落(例如各种未定义的行为)。这不是一个可重复使用的体验,现在把它全部扔掉有点令人毛骨悚然。
比如,你能想象 || 符号在 requires ((! P
|| ! Q ) 和 requires (! (P || Q )) 中的含义不同吗?)前者是约束析取,后者是古老的逻辑 OR 运算符,它们的行为是不同的。 你不能为简单的类型分配空间,而无需额外的努力就可以在其中 memcpy 一组字节 - 这不会启动对象的生命周期。 C++20之前就是这种情况。它在 C++20 中得到了修复,但该语言的认知负荷只是增加了。
尽管事情已经解决,但认知负荷却在不断增加。我应该知道修复了什么,什么时候修复的,修复前是什么样子。毕竟我是专业人士。当然,C++ 擅长遗留问题支持,这也意味着你将面对遗留问题。例如,上个月我的一位同事向我询问 C++03 中的一些行为。
有 20 种初始化方式。现在增加了统一初始化语法。现在我们有 21 种初始化方式。顺便问一句,还有人记得从初始化列表中选择构造函数的规则吗?关于隐式转换,信息损失最小,但如果值是静态已知的,那么......
这种认知负荷的增加并不是由手头的业务任务造成的。它不是领域的内在复杂性。它只是由于历史原因而存在(外在认知负荷)。
我不得不想出一些规则。比如,如果那行代码不那么明显,而我又必须记住标准,那我最好不要那样写。顺便说一句,该标准长达 1500 页。
我绝不是在指责 C++。我热爱这门语言。只是我现在累了
分层架构
抽象本应隐藏复杂性,但在这里它只是增加了间接性。从一个调用跳转到另一个调用,以便阅读并找出出错的地方和遗漏的地方,这是快速解决问题的一个重要要求。由于该架构的层解耦(uncoupling),需要指数级的额外跟踪(通常是不连贯的)才能找到故障发生点。每一个这样的跟踪都会占用我们有限的工作内存空间。🤯
这种架构起初很有直觉意义,但每次我们尝试将其应用到项目中时,都是弊大于利。最后,我们放弃了这一切,转而采用古老的依赖关系反转原则。没有需要学习的端口/适配器术语,没有不必要的水平抽象层,没有无关的认知负荷。
如果你认为这样的分层可以让你快速更换数据库或其他依赖项,那就大错特错了。改变存储会带来很多问题,相信我们,对数据访问层进行抽象是最不需要担心的。抽象最多只能节省 10%的迁移时间(如果有的话),真正的痛苦在于数据模型不兼容、通信协议、分布式系�统挑战和隐式接口。
那么,如果将来没有回报,为什么要为这种分层架构付出高认知负荷的代价呢?
不要为了架构而添加抽象层。只要出于实际原因需要扩展点,就应该添加抽象层。抽象层不是免费的,它们应保存在我们的工作记忆中。
DDD
领域驱动设计(DDD)有一些很好的观点,尽管它经常被曲解。人们说 "我们用领域驱动设计来写代码",这有点奇怪,因为领域驱动设计是关于问题空间的,而不是关于解决方案空间的。
无处不在的语言、领域、有界上下文、聚合、事件风暴都是关于问题空间的。它们旨在帮助我们了解关于领域的见解并提取边界。DDD使开发人员、领域专家和业务人员能够使用单一的统一语言进行有效的沟通。我们倾向于强调特定的文件夹结构、服务、存储库,以及其他解决方案空间技术。
我们解释 DDD 的方式很可能是独特而主观的。如果我们在这种理解的基础上构建代码,也就是说,如果我们创造了大量无关的认知负荷,那么未来的开发人员就注定要失败。 🤯
例如
- 我们的架构是一个标准的 CRUD 应用程序架构,Postgres 上的 Python 单体
- Instagram 如何在 仅有 3 名工程师 的情况下将用户数量扩大到 1400 万
- 我们觉得 "哇,这些人真是聪明绝顶 "的公司大多失败了。
- 一个功能将整个系统连接起来。如果您想知道系统是如何工作的,请阅读此文
这些架构相当枯燥,而且易于理解。任何人都可以轻松掌握。
让初级开发人员参与架构评审。他们将帮助您识别需要脑力劳动的领域。
熟悉项目中的认知负荷
如果你已经将项目的心理模型内化到你的长期记忆中,你就不会经历高认知负荷。
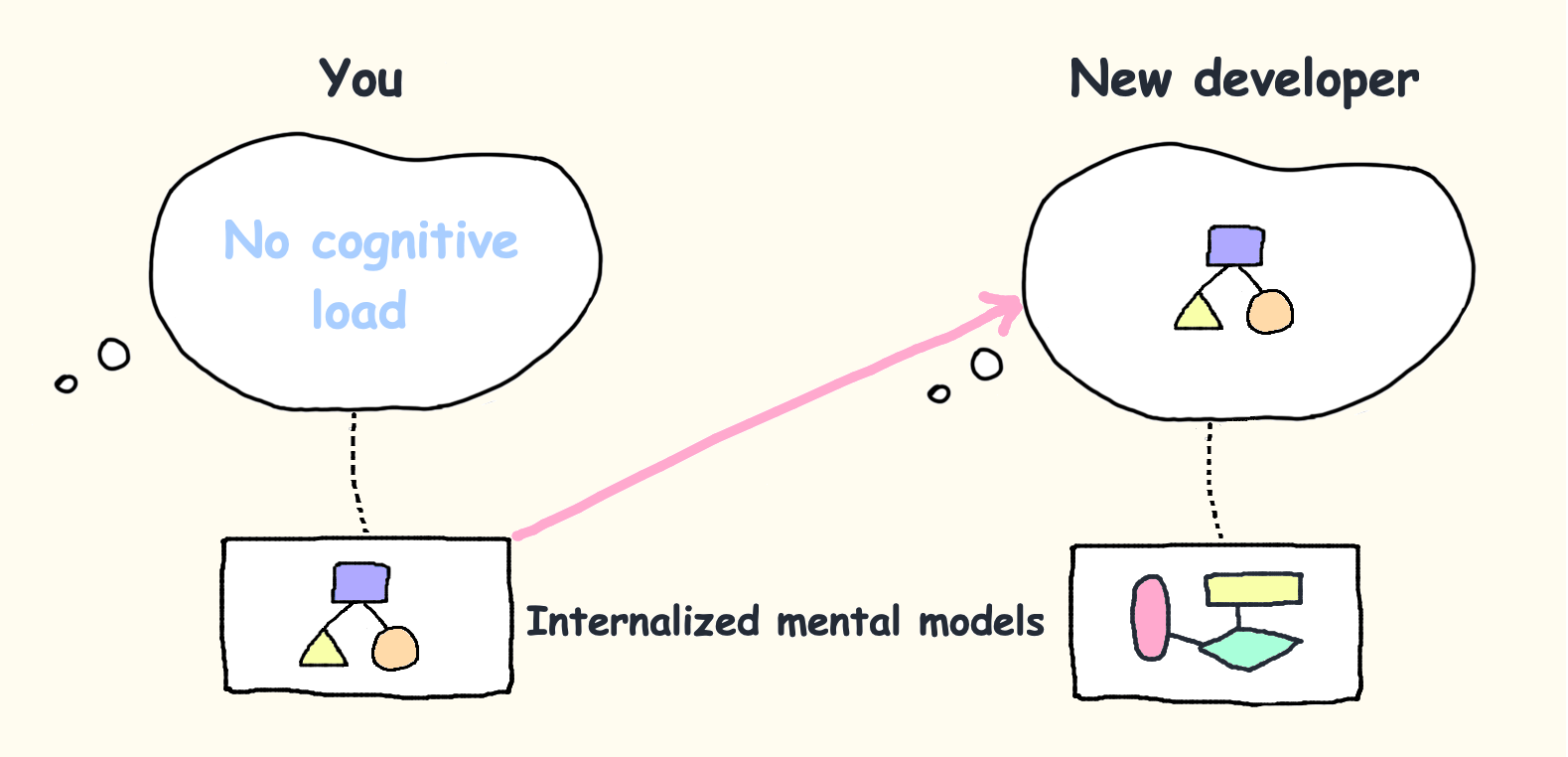
The more mental models there are to learn, the longer it takes for a new developer to deliver value.
Once you onboard new people on your project, try to measure the amount of confusion they have (pair programming may help). If they're confused for more than ~40 minutes in a row - you've got things to improve in your code.
If you keep the cognitive load low, people can contribute to your codebase within the first few hours of joining your company.
总结
试想一下,我们在第二章中的推论实际上并不正确。如果是这样的话,那么我们刚刚否定的结论,以及前一章中我们认为有效的结论,可能也不正确。 🤯
你感觉到了吗?你不仅要在文章中跳来跳去才能理解意思(肤浅的模块!),而且段落一般都很难理解。我们只是在你的头脑中创造了一个不必要的认知负荷。不要对你的同事这样做
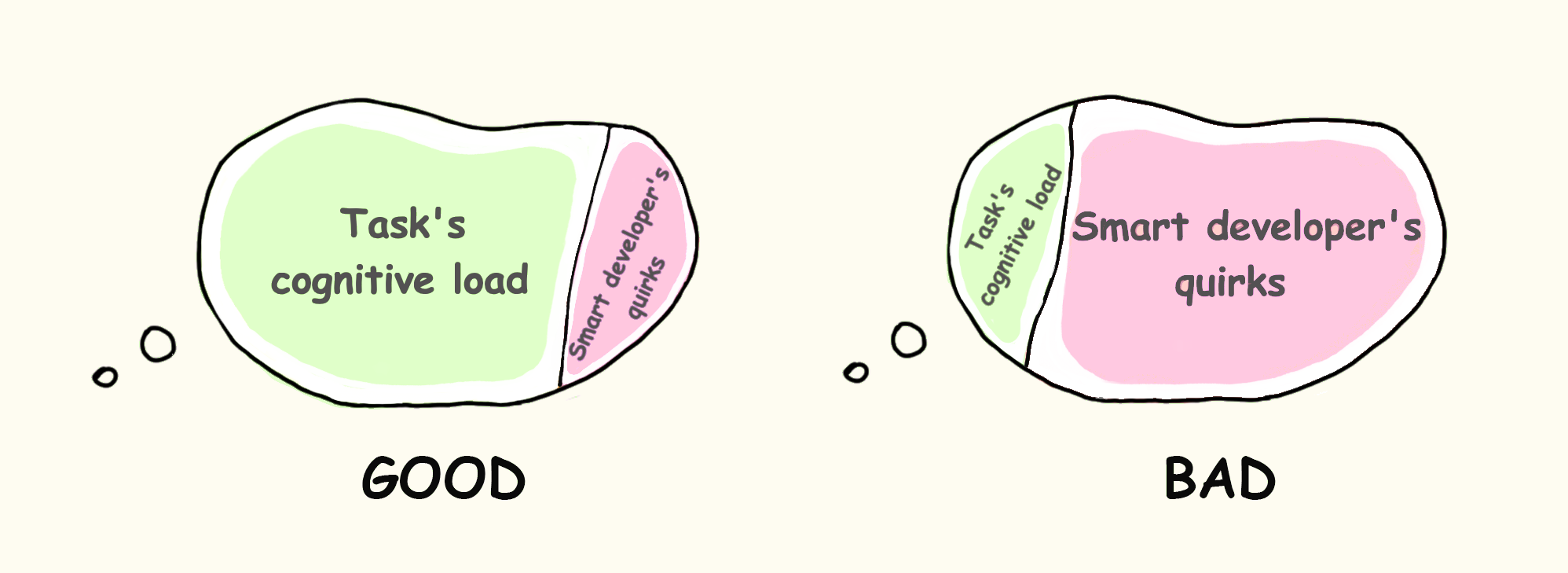
我们应该减少任何认知负荷超过我们所做的工作的内在。