Agent
Agent(model)实战
类似于 RL 的过程
Agent(WorkFlow)相关理论+实战
类似于设计有向无环图
https://qiankunli.github.io/2018/09/04/technology_manage.html
从头实现一个基于 LLM 的 Agent 是一个系统工程,对一个初学者来说要学习的太多,本文结合个人思考从学术研究到常见框架进行总结。
https://github.com/KelvinQiu802/llm-mcp-rag
流式输出:GitHub - ZejunCao/bilibili_code: bilibili 视频讲解所使用的课件代码记录
初学者网站:
0. Motivation
搭建可自我修正、持续优化的 Agent 系统。
可能的关键点:
1.上下文动态调整机制
Context 决定了 LLM 在各个场景中的实际表现。上下文包含:User Query、History Messages、Prompt、Search Results、Tool Call Results 等等。尽管 LLM 的 Attention 与自回归生成可以改变 context,但实践证明这种机制还不足够,现有 LLM 依然需要精细 context 设置才能更好完成任务。分治、专注:相比使用单个复杂 Prompt,将复杂任务拆解为简单子任务,并为每个子任务设置独立的 Prompt 更容易优化,取得更好的整体效果。多尺度上下文:将 Context 中的冗余信息进行压缩或扩充。
2.反思与适应机制
1.大模型常见工具、平台
分布式训练框架:Accelerate(初始化)、DeepSpeed、MegaTron-LM、Colossal-AI、FairScale
推理框架:vLLM、LMDeploy、TensorRT-LLM、TGI、DeepSpeed-IF3
分布式任务调度框架:Ray
LLM 微调框架:OpenRLHF、LLaMA Factory、VeRL
GPT给出的VeRL与其他模块的关系
数据 → SFT → Reward Model → Preference Data → PPO / DPO / IPO → 微调完成
↑ ↑ ↑ ↓
DeepSpeed Accelerate Ray Tune (可选) 模型 API 暴露,供 LangChain 调用
应用开发框架:LangChain、pydantic_ai Web UI:Gradio、Streamlit、FastAPI、Flask
2.相关概念
Agent = LLM + Planning + Memory + Tools + Action
这里头 LLM 当然是核心,其推理、规划等能力都要出色,也可以使用多个 LLM 来联合完成任务。Planning 是
2.1.Agent System
大模型没那么大:ACL 2025 | 大模型提示词不是「随便写」!这篇文章告诉你:每句话都在重塑 AI 的「思考路径」
LLM 基座的选择很重要,因为有的模型推理能力不足,或者缺乏具备创造/调用工具的能力,难以支持复杂的 Agent 任务。除了基座选择以外,Prompt 也是重要的一环,是让 Agent 实现自主的关键。具体来说,Prompt 可以同时起到角色定位、陈述性和流程性等记忆(用户喜好、工具定义、可行的工具流程)、思维能力增强(CoT 能力、反思能力、抽象思维、发散思维、归纳思维、思维结构塑造)和内外部感知(工具、环境的感知)等作用,优化速度很快而且成本很低。因此 Prompt 微调相比参数微调对 Agent 更为重要,更适合测试时适应,而且给用户的反馈是最直接的。参数微调则更适合在获得大量数据后将知识内化。CoT 实际上也可以看做一种自己 Prompt 自己的过程【论文】,有序化搜索空间,提升泛化能力,因此理论上来说存在不需要任何 System Prompt 的 Agent。【想法:Prompt 太多了也不好,每次推理速度很慢,如何实现 Prompt 的内化?可以将 Prompt LLM 的能力蒸馏到 w/o Prompt LLM 中,通过对比两个模型的性能来实现自我学习。或者自己将 Prompt 进行总结,对比总结前后的性能来有效提升 LLM 能力】
Prompt 也会起到 负面作用,比如我在设计 Agent 的时候,一开始就只设定了其智能助理的身份,结果 LLM 就丧失了利用自身知识的对话能力。比如,询问我设计的 Agent 某个动漫每一集的内容,它无法回答出来,而在无 Prompt 的情况下就可以很好的回答问题。最后,我在 Prompt 中引入了一个知识库的身份,引导其可以利用自身知识来回答问题,才部分解决了这一问题。还有比如 Prompt 如果包含不合理的工作流,也会让 LLM 效果更差。
2.2.Memory:RAG、记忆系统
看完 Cursor 记忆功能提示词后,我发现了 AI 智能体记忆设计的秘诀
首次全面复盘 AI Agents 记忆系统:3 大类,6 种操作!
2.3.Tools:Function Call、Model Context Protocol (MCP)
不理不理:Qwen Function Calling 的对话模板及训练方法总结
MCP、function calling 这两者有什么区别?与 AI Agent 是什么关系?
战士金:大模型工具调用(function call)原理及实现
MCP 的 Github 链接:
https://github.com/modelcontextprotocol/python-sdk
@mcp.tools 的实现
LastWhisper:MCP (Model Context Protocol),一篇就够了。
https://github.com/liaokongVFX/MCP-Chinese-Getting-Started-Guide?tab = readme-ov-file
MCP 的 Prompt(未确认)
Tool: {self.name}
Description: {self.description}
Arguments:
{chr(10).join(args_desc)}
2.4.Planning:WorkFlow、Chain of Thought (CoT)
简单来讲,就是通过将问题进行分解并依次求解,来提升复杂问题的处理能力,例如做数学题、编写代码。CoT 的发展历程为 IO (Input-Output) -> CoT -> ToT (Tree of Thought)。实现方式包括:
Prompt
3.相关研究
3.1.Agent 的仿生启发
吕阿华:【AI Agent 研究综述】《基础智�能体的进展与挑战:从脑启发智能到进化、协作和安全系统》(全文)
3.2.Agent 综述
LinguaMind:万字长文!何谓 Agent,为何 Agent?
3.3.Agent 前沿
自动驾驶之心:思维链再进化!极简推理范式 Chain of Draft:推理 token 爆砍 80%~
机器之心:OTC‑PO 重磅发布 | 揭开 o3 神秘面纱,让 Agent 少用工具、多动脑子!
3.3. Agent 项目与系统
https://github.com/Fosowl/agenticSeek
如何快速理解已有 Github 项目,并用于自己的项目中?
Claude code 的逆向工程:
https://github.com/shareAI-lab/analysis_claude_code
4.实战
4.1. Prompt 设计心得
Prompt 一方面给予了模型引导,另一方面也会限制模型能力
4.1.常见格式
模型训练-sharegpt,保存为 jsonl:
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]
conversations 是一个列表,每个元素包含一个 from 和一个 value,分别代表发言的角色以及内容。conversations 中奇数列为外部环境反馈(human、observation),偶数列为 Agent 的 Action(gpt、funciton_call)。system 和 tools 是其他参数。
sharegpt 还可以设置偏好数据集,其中 conversations 为多轮对话(奇数个,需要模型输出回答)。chosen 和 rejected 则为正负样本对。
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "gpt",
"value": "模型回答"
},
{
"from": "human",
"value": "人类指令"
}
],
"chosen": {
"from": "gpt",
"value": "优质回答"
},
"rejected": {
"from": "gpt",
"value": "劣质回答"
}
}
]
模型训练-alpaca,保存为 jsonl 或者 json:
{
"instruction": "Describe the benefits of exercise.",
"input": "",
"output": "Exercise improves mental and physical health..."
}
LLaMA 2 / ChatLLaMA 格式(Meta 官方推荐)
huggingface 上 llama 2 chat 格式是多轮 messages 模式:
{
"conversations": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's the weather like?"},
{"role": "assistant", "content": "It's sunny and warm."}
]
}
Vicuna(基于 LLaMA + ShareGPT)
Vicuna 用的是 ShareGPT 格式,类似 messages 列表。
{
"conversations": [
{"from": "human", "value": "Tell me a joke."},
{"from": "gpt", "value": "Why did the chicken cross the road? To get to the other side!"}
]
}
Baichuan / Qwen / ChatGLM 格式
一般也采用 messages 数组结构,但 role 命名不同。
{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What's AI?"},
{"role": "assistant", "content": "AI stands for Artificial Intelligence..."}
]
}
4.1.基础 Agent 实现
无涯:基于本地知识的问答机器人 langchain-ChatGLM
RedHerring:手搓一个最小的 Agent 系统 — Tiny Agent
wx1997:AI Agent 系列二:Agent 基础技术篇(ReACT、ReST、AgentTuning、Reflexion)
摇一摇:我也复刻了一个 Manus,带高仿 WebUI 和沙盒
4.1.结合模型训练的 Agent
4.2.NLP 奇幻之旅:vLLM 入门(一)初始 vLLM
4.3
字节跳动开源了 Deep Research 项目 DeerFlow,这将如何影响开源社区和技术发展?
SkyRL:首个现实环境、长周期 LLM Agent 的端到端 RL 流水线框架
设计 action space �接近于帮 LLM agent 的抽象出它的 skills
设计 state space 接近于帮 LLM 选择需要置入 上下文的内容或者写提示词
reward function 相当于帮 LLM 设计 evaluation 和 verify 模块,直接决定 它的自行迭代环路的 转动速度
manus
什么是 manus
-
Manus 是一个真正自主的 AI 代理,能够解决各种复杂且不断变化的任务。其名称来源于拉丁语中 "手" 的意思,象征着它能够将思想转化为行动的能力。与传统的 AI 助手不同,Manus 不仅能提供建议或回答,还能直接交付完整的任务结果。
-
作为一个 "通用型 AI 代理",Manus 能够自主执行任务,从简单的查询到复杂的项目,无需用户持续干预。用户只需输入简单的提示,无需 AI 知识或经验,即可获得高质量的输出。
-
这种 "一步解决任何问题" 的设计理念使 Manus 区别于传统的 AI 工作流程,更易于普通用户使用。
关于 manus
-
Manus 之前做的是 AI 浏览器,后跟 Arc 团队转型做 Dia 遇到了类似的问题,但比他们做的更多更快,于是转去做了现在的 Manus。之前的 Browse Use、Computer Use 的人机协同体验不佳, AI 在跟用户抢夺控制权,当你下达任务之后,只能在一旁欣赏 AI 的表演,如果误触,流程就可能被打断。AI 需��要使用浏览器,但 Manus 团队认为应该给 AI 一个自己云端的浏览器,最后把结果反馈给用户就行。
-
Less Structure, More Intelliengence. 这是业内大家讨论比较多的一个非共识,对于这个问题的热烈讨论从扣子 Coze 等平台支持通过 workflow 构建 AI 应用就一直存在。比如 Flood Sung 就在 Kimi 发布 k1.5 时表态,“现在的各种 Agentic Workflow 就是各种带 Structure 的东西,它一定会限制模型能力,没有长期价值,早晚会被模型本身能力取代掉。Manus 就是这样的设计,没有任何搭建的 workflow,所有的能力都是模型自然演化出来的,而不是用 workflow 去教会的。
-
Manus 设计的第一个核心是给大模型配了一个电脑,让它一步步规划去做 observation 和 action;第二个核心是给它配了系统权限,好比给新来的同事开通了一些公司账户权限,Manus 接入了大量的私有 API,能够处理许多结构化的权威数据;第三个核心是给它 Training,给它培训,就好比跟新来的同事也有磨合的过程,Manus 也会根据你的使用习惯不断的去学习你的要求。
-
为什么 Manus 说自己是“全球首款真正意义上的通用 AI Agent?”那之前的 Operator、Deep Research、MetaGPT、AutoGPT、Eko 等等不算吗?以及为啥有人说 Manus 是套壳到了极致?在我们的理解里,其实之前的一些 Agent 开源框架也能实现 Manus 类似的效果,但 Manus 做了一些不错的工程优化,率先的产品化了出来。这里 cue 一下另一个华人团队 Flowith,他们半年前做的 Oracle 模式,基本都能实现目前 Manus Demo 演示出的效果。
核心架构解析
Manus 的��架构设计体现 Multi-Agent 系统的典型特征,其核心由三大模块构成:
1.规划模块(Planning)
规划模块是 Manus 的 "大脑",负责理解用户意图,将复杂任务分解为可执行的步骤,并制定执行计划。这一模块使 Manus 能够处理抽象的任务描述,并将其转化为具体的行动步骤。
作为系统的决策中枢,规划模块实现:
-
任务理解与分析
-
任务分解与优先级排序
-
执行计划制定
-
资源分配与工具选择
-
语义理解与意图识别(NLU)
-
复杂任务分解为 DAG 结构
-
异常处理与流程优化
2.记忆模块(Memory)
记忆模块使 Manus 能够存储和利用历史信息,提高任务执行的连贯性和个性化程度。该模块管理三类关键信息:
-
用户偏好:记录用户的习惯和喜好,使后续交互更加个性化
-
历史交互:保存过去的对话和任务执行记录,提供上下文连贯性
-
中间结果:存储任务执行过程中的临时数据,支持复杂任务的分步执行
构建长期记忆体系:
class MemorySystem:
def __init__(self):
self.user_profile = UserVector() ## 用户偏好向量
self.history_db = ChromaDB() ## 交互历史数据库
self.cache = LRUCache() ## 短期记忆缓存
3.工具使用(Tool Use)
工具使用模块是 Manus 的 "手",负责实际执行各种操作。该��模块能够调用和使用多种工具来完成任务,包括:
-
网络搜索与信息检索
-
数据分析与处理
-
代码编写与执行
-
文档生成
-
数据可视化
这种多工具集成能力使 Manus 能够处理各种复杂任务,从信息收集到内容创建,再到数据分析。
Multi-Agent 系统:智能协作的艺术
-
Multi-Agent 系统(MAS)由多个交互的智能体组成,每个智能体都是能够感知、学习环境模型、做出决策并执行行动的自主实体。这些智能体可以是软件程序、机器人、无人机、传感器、人类,或它们的组合。
-
在典型的 Multi-Agent 架构中,各个智能体具有专业化的能力和目标。例如,一个系统可能包含专注于内容摘要、翻译、内容生成等不同任务的智能体。它们通过信息共享和任务分工的方式协同工作,实现更复杂、更高效的问题解决能力。
运转逻辑与工作流程
- Manus 采用多代理架构(Multiple Agent Architecture),在独立的虚拟环境中运行。其运转逻辑可以概括为以下流程:
完整执行流程
-
任务接收:用户提交任务请求,可以是简单的查询,也可以是复杂的项目需求。Manus 接收这一输入,并开始处理。
-
任务理解:Manus 分析用户输入,理解任务的本质和目标。在这一阶段,记忆模块提供用户偏好和历史交互信息,帮助更准确地理解用户意图。
- 运用先进的自然语言处理技术对用户输入进行意图识别和关键词提取
- 在需求不明确时,通过对话式引导帮助用户明晰目标
- 支持文本、图片、文档等多模态输入,提升交互体验
-
任务分解:规划模块将复杂任务自动分解为多个可执行的子任务,建立任务依赖关系和执行顺序。
// todo.md
- [ ] ��调研日本热门旅游城市
- [ ] 收集交通信息
- [ ] 制定行程安排
- [ ] 预算规划
- 任务初始化与环境准备:为确保任务执行的隔离性和安全性�,系统创建独立的执行环境:
## 创建任务目录结构
mkdir -p {task_id}/
docker run -d --name task_{task_id} task_image
-
执行计划制定:为每个子任务制定执行计划,包括所需的工具和资源。历史交互记录在这一阶段提供参考,帮助优化执行计划。
-
自主执行:工具使用模块在虚拟环境中自主执行各个子任务,包括搜索信息、检索数据、编写代码、生成文档和数据分析与可视化等。执行过程中的中间结果被记忆模块保存,用于后续步骤。
系统采用多个专业化 Agent 协同工作,各司其职:
每个 Agent 的执行结果都会保存到任务目录,确保可追溯性:
class SearchAgent:
def execute(self, task):
## 调用搜索 API
results = search_api.query(task.keywords)
## 模拟浏览器行为
browser = HeadlessBrowser()
for result in results:
content = browser.visit(result.url)
if self.validate_content(content):
self.save_result(content)
- Search Agent: 负责网络信息搜索,获取最新、最相关的数据,采用混合搜索策略(关键词+语义)
- Code Agent: 处理代码生成和执行,实现自动化操作,支持 Python/JS/SQL 等语言
- Data Analysis Agent: 进行数据分析,提取有价值的洞见,Pandas/Matplotlib 集成
- 动态质量检测:
def quality_check(result):
if result.confidence < 0.7:
trigger_self_correction()
return generate_validation_report()
- 结果整合:将各个子任务的结果整合为最终输出,确保内容的连贯性和完整性。
-
智能整合所有 Agent 的执行结果,消除冗余和矛盾
-
生成用户友好的多模态输出,确保内容的可理解性和实用性
-
结果交付:向用户提供完整的任务结果,可能是报告、分析、代码、图表或其他形式的输出。
-
用户反馈与学习:用户对结果提供反馈,这些反馈被记忆模块记录,用于改进未来的任务执行。强化模型微调,不断提升系统性能。
manus 的核心能力-推测与拆解
- manus 核心优势在 Controller 层
在 agent flow 能力(observe,plan 和 tool decide 的大模型环节),大概率这些是使用自己调优训练的大模型的,并且基础模型大概率是 qwen
- Manus 比较亮眼的能力:
- Plan 较为充分,有条理
- 决定使用什么 tool 的能力很强(例如可以玩 2048,用 yahoo api 下载布伦特原油价格数据)
- 浏览器上的观察能力不弱(例如可以展开日历控件并且尝试翻页)
- 与用户的交互能力不弱(可以理解到弹出了小红书登录框并且交互要求登录)
- 初步判断 agent flow 中应该是使用了自己调优的模型
- 单步的 tool 或者 agent 调用可能没有调优,例如 codeact 模型未必需要在论文基础上调优(目前看官方爆料,大概率用的是 Claude Sonnet 3.7)
- manus 的核心壁垒是数据
- 很简单,如果得知核心优势是调优的模型,那么核心壁垒就一定是调优数据
- Manus 团队之前是做 AI 浏览器的,浏览器交互数据可能很充分(这也说明了为什么他们浏览器操作很多,并且只能程度很高);这里可以贡献了 plan 和 observe 部分的数据。
- 其他 agent flow 的数据未知,尤其是 tool decide 的数据情况未知
- manus 的 AgentFlow 有没有可能使用了其他黑科技
- 之前觉得有黑科技,或者说实际上之后可以发展为 CodeAgent(就是整个 plan 和 tasks 都是 code 描述的,包括方法调用,状态码,任务复杂结构,try catch 容错等)
- 但目前看 manus 的模式不是,还是本地起 todo.md,里面是 task-》subtask 模式
- 不能排除其他黑科技
- manus 不用 MCP 协议的原因
- 本质上 Manus 只使用了 3 个工具调用:vscode - python, Linux sandbox - computer use, chrome - browser use。并且开发人员否认了 MCP 的使用,hidecloud 也在群里表示完全不理解为什么要用 MCP。
- MCP 其实提供了一个更大范围的可调用 tool list,但是它没有解决排行问题和检索问题
- MCP 对于 Manus 模式的贡献可能会有 2 个,一个是更好的搜索源,一个是官方的长尾 rpa(例如操作美团或者 12306),除此之外没有什么帮助
技术特点与创新
Manus 具有多项技术特点,使其在 AI 代理领域脱颖而出:
-
自主规划能力
- Manus 能够独立思考和规划,确保任务的执行,这是其与之前工具的主要区别。在 GAIA 基准测试(General AI Assistant Benchmark)中,Manus 取得了最新的 SOTA(State-of-the-Art)成绩,这一测试旨在评估通用 AI 助手在现实世界中解决问题的能力。在复杂任务中实现 94%的自动完成率。
-
上下文理解
- Manus 能够从模糊或抽象�的描述中准确识别用户需求。例如,用户只需描述视频内容,Manus 就能在平台上定位相应的视频链接。这种高效的匹配能力确保了更流畅的用户体验。支持 10 轮以上的长对话维护。
-
多代理协作
- Manus 采用多代理架构,类似于 Anthropic 的 Computer Use 功能,在独立的虚拟机中运行。这种架构使不同功能模块能够协同工作,处理复杂任务。
-
工具集成
- Manus 能够自动调用各种工具,如搜索、数据分析和代码生成,显著提高效率。这种集成能力使其能够处理各种复杂任务,从信息收集到内容创建,再到数据分析。支持自定义工具插件开发。
-
安全隔离
- 基于 gVisor 的沙箱环境,确保任务执行的安全性和稳定性。
-
其他技术优势
-
环境隔离的任务执行,确保安全性和稳定性
-
模块化的 Agent 设计,支持灵活扩展
-
智能化的任务调度机制,最大化资源利用
-
未来优化方向
-
任务依赖关系升级为 DAG (有向无环图) 结构,支持更复杂的任务流
-
引入自动化测试和质量控制,提高执行结果的可靠性
-
发展人机混合交互模式,结合人类洞察和 AI 效率
技术架构依赖
系统的强大能力得益于多层次的模型协作:
-
轻量级模型:负责意图识别,提供快速响应
-
Deepseek-r1:专注于任务规划,把控全局策略
-
Claude-3.7-sonnet:处理复杂的多模态任务,提供深度理解能力
应用场景扩展
| 场景类型 | 典型案例 | 输出形式 |
|---|---|---|
| 旅行规划 | 日本深度游定制 | 交互式地图 + 预算表 |
| 金融分析 | 特斯拉股票多维分析 | 动态仪表盘 + 风险评估 |
| 教育支持 | 动量定理教学方案 | 互动式课件 + 实验模拟 |
| 商业决策 | 保险产品对比分析 | 可视化对比矩阵 + 建议书 |
| 市场研究 | 亚马逊市场情绪分析 | 季度趋势报告 + 预测模型 |
与传统 AI 助手的差异对比
优点:
-
端到端任务交付:不仅提供建议,还能直接执行任务并交付结果
-
任务分解能力:能够将复杂任务分解为可管理的步骤
-
工具使用能力:能够调用和使用各种工具完成任务
-
动态环境适应能力:能够根据任务需求调整执行策略
-
长期记忆保持:能够记住用户偏好和历史交互,提供个性化体验
-
结果导向:注重交付完整的任务结果,而非仅提供信息
缺点:
-
单次交互模式:传统 AI 主要停留在 "对话" 层面
-
静态响应机制:缺乏自主执行能力
-
无状态设计:每次对话独立,缺乏连续性
openManus
继 deepseek 之后,武汉一个开发 monica 的团队又开发了 manus,号称是全球第一个通用的 agent!各路自媒体企图复刻下一个 deepseek,疯狂报道!
然而 manus 发布后不久,metaGPT 团队 5 个工程师号称耗时 3 小时就搞定了一个 demo 版本的 manus,取名 openManus,才几天时间就收获了 34.4K 的 start,又火出圈了!现在研究一下 openManus 的核心原理!
为什么要 agent
-
目前的 LLM 只能做决策,无法落地实施,所以还需要外部的 tool 具体干活
-
目前的 LLM 虽然已经有各种 COT,但纯粹依靠 LLM 自己完成整个链条是不行的,还是需要人为介入做 plan、action、review 等工作
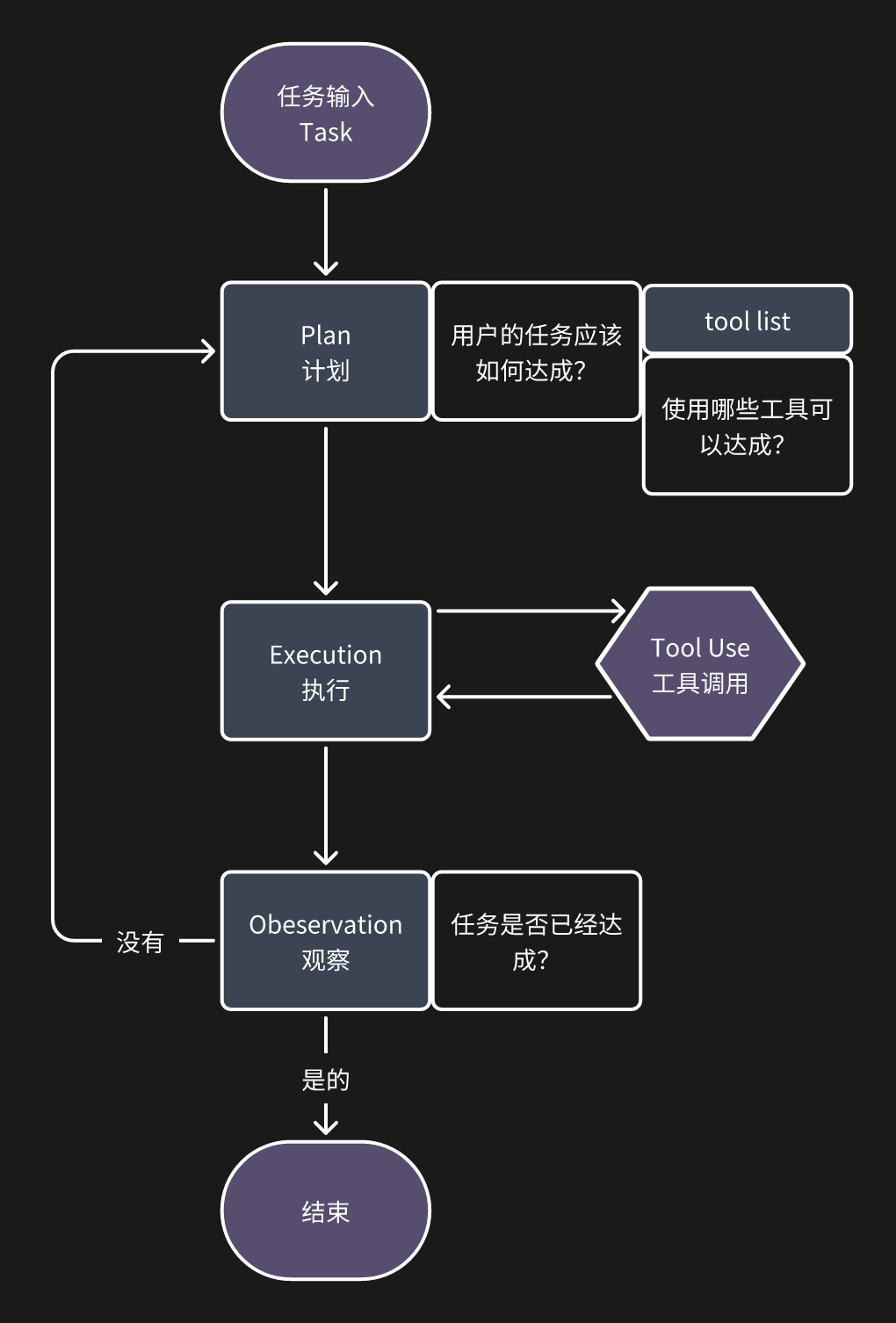
所以 agent 诞生了!不管是 deep search、deep research、manus 等,核心思路都是一样的:plan-> action-> review-> action-> review...... 如此循环下去,直到触发结束的条件!大概的流程如下:
具体到 openManus,核心的流程是这样的:用户输入 prompt 后,有专门的 agent 调用 LLM 针对 prompt 做任务拆分,把复杂的问题拆解成一个个细分的、逻��辑连贯的小问题,然后对于这些小问题,挨个调用 tool box 的工具执行,最后返回结果给用户!
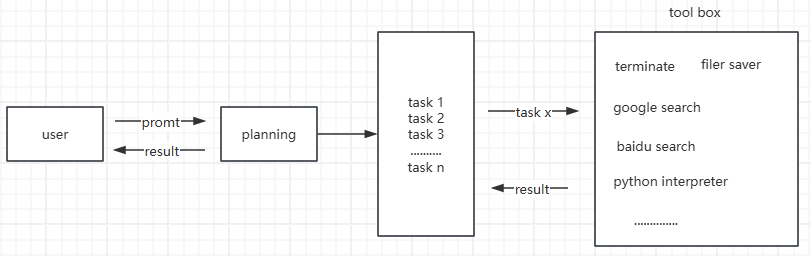
这类通用 agent 最核心的竞争力就两点了:
- plan 是否准确:这个主要看底层 LLM 的能力,对 prompt 做命名实体识别和意图识别!
- tool box 的工具是否丰富:用户的需求是多样的,tool 是否足够满足用户需求?
openManus 的目录结构
4 个文件夹,分别是 agent、flow、prompt、tool,只看名字就知道这个模块的功能了
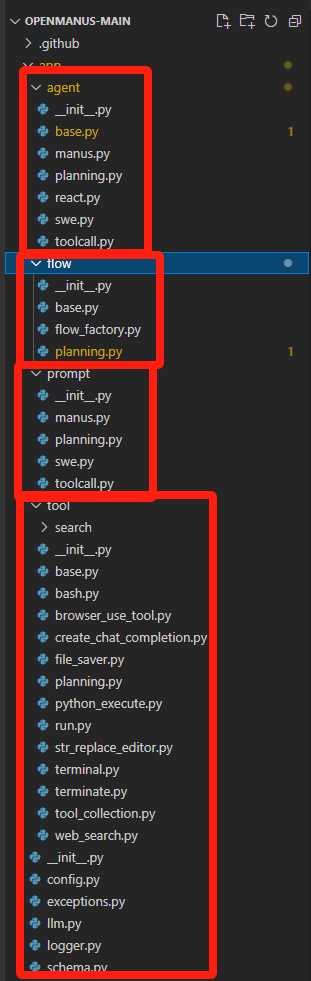
整个程序入口肯定是各种 agent 啦!各大 agent 之间的关系如下:
(1)agent 核心的功能之一不就是 plan 么,openManus 的 prompt 是这么干的:promt 中就直接说明了是 expert plan agent,需要生成可执行的 plan!
PLANNING_SYSTEM_PROMPT = """
You are an expert Planning Agent tasked with solving problems efficiently through structured plans.
Your job is:
1. Analyze requests to understand the task scope
2. Create a clear, actionable plan that makes meaningful progress with the `planning` tool
3. Execute steps using available tools as needed
4. Track progress and adapt plans when necessary
5. Use `finish` to conclude immediately when the task is complete
Available tools will vary by task but may include:
- `planning`: Create, update, and track plans (commands: create, update, mark_step, etc.)
- `finish`: End the task when complete
Break tasks into logical steps with clear outcomes. Avoid excessive detail or sub-steps.
Think about dependencies and verification methods.
Know when to conclude - don't continue thinking once objectives are met.
"""
NEXT_STEP_PROMPT = """
Based on the current state, what's your next action?
Choose the most efficient path forward:
1. Is the plan sufficient, or does it need refinement?
2. Can you execute the next step immediately?
3. Is the task complete? If so, use `finish` right away.
Be concise in your reasoning, then select the appropriate tool or action.
"""
prompt 有了,接着就是让 LLM 对 prompt 生成 plan 了,在 agent/planning.py 文件中:
async def create_initial_plan(self, request: str) -> None:
"""Create an initial plan based on the request."""
logger.info(f"Creating initial plan with ID: {self.active_plan_id}")
messages = [
Message.user_message(
f"Analyze the request and create a plan with ID {self.active_plan_id}: {request}"
)
]
self.memory.add_messages(messages)
response = await self.llm.ask_tool(
messages=messages,
system_msgs=[Message.system_message(self.system_prompt)],
tools=self.available_tools.to_params(),
tool_choice=ToolChoice.AUTO,
)
assistant_msg = Message.from_tool_calls(
content=response.content, tool_calls=response.tool_calls
)
self.memory.add_message(assistant_msg)
plan_created = False
for tool_call in response.tool_calls:
if tool_call.function.name == "planning":
result = await self.execute_tool(tool_call)
logger.info(
f"Executed tool {tool_call.function.name} with result: {result}"
)
## Add tool response to memory
tool_msg = Message.tool_message(
content=result,
tool_call_id=tool_call.id,
name=tool_call.function.name,
)
self.memory.add_message(tool_msg)
plan_created = True
break
if not plan_created:
logger.warning("No plan created from initial request")
tool_msg = Message.assistant_message(
"Error: Parameter `plan_id` is required for command: create"
)
self.memory.add_message(tool_msg)
plan 生成后,就是 think 和 act 的循环啦!同理,这部分实现代码在 agent/toolcall.py 中,如下:think 的功能是让 LLM 选择干活的工具,act 负责调用具体的工具执行
async def think(self) -> bool:
"""Process current state and decide next actions using tools"""
if self.next_step_prompt:
user_msg = Message.user_message(self.next_step_prompt)
self.messages += [user_msg]
## Get response with tool options:让LLM选择使用哪种工具干活
response = await self.llm.ask_tool(
messages=self.messages,
system_msgs=[Message.system_message(self.system_prompt)]
if self.system_prompt
else None,
tools=self.available_tools.to_params(),
tool_choice=self.tool_choices,
)
self.tool_calls = response.tool_calls
## Log response info
logger.info(f"✨ {self.name}'s thoughts: {response.content}")
logger.info(
f"🛠️ {self.name} selected {len(response.tool_calls) if response.tool_calls else 0} tools to use"
)
if response.tool_calls:
logger.info(
f"🧰 Tools being prepared: {[call.function.name for call in response.tool_calls]}"
)
try:
## Handle different tool_choices modes
if self.tool_choices == ToolChoice.NONE:
if response.tool_calls:
logger.warning(
f"🤔 Hmm, {self.name} tried to use tools when they weren't available!"
)
if response.content:
self.memory.add_message(Message.assistant_message(response.content))
return True
return False
## Create and add assistant message
assistant_msg = (
Message.from_tool_calls(
content=response.content, tool_calls=self.tool_calls
)
if self.tool_calls
else Message.assistant_message(response.content)
)
self.memory.add_message(assistant_msg)
if self.tool_choices == ToolChoice.REQUIRED and not self.tool_calls:
return True ## Will be handled in act()
## For 'auto' mode, continue with content if no commands but content exists
if self.tool_choices == ToolChoice.AUTO and not self.tool_calls:
return bool(response.content)
return bool(self.tool_calls)
except Exception as e:
logger.error(f"🚨 Oops! The {self.name}'s thinking process hit a snag: {e}")
self.memory.add_message(
Message.assistant_message(
f"Error encountered while processing: {str(e)}"
)
)
return False
async def act(self) -> str:
"""Execute tool calls and handle their results"""
if not self.tool_calls:
if self.tool_choices == ToolChoice.REQUIRED:
raise ValueError(TOOL_CALL_REQUIRED)
## Return last message content if no tool calls
return self.messages[-1].content or "No content or commands to execute"
results = []
for command in self.tool_calls:
result = await self.execute_tool(command)#调用具体的工具干活
if self.max_observe:
result = result[: self.max_observe]
logger.info(
f"🎯 Tool '{command.function.name}' completed its mission! Result: {result}"
)
## Add tool response to memory
tool_msg = Message.tool_message(
content=result, tool_call_id=command.id, name=command.function.name
)
self.memory.add_message(tool_msg)
results.append(result)
return "\n\n".join(results)
think 和 act 是循环执行的,直到满足停止条件,这部分功能在 agent/base.py 实现的:
async def run(self, request: Optional[str] = None) -> str:
"""Execute the agent's main loop asynchronously.
Args:
request: Optional initial user request to process.
Returns:
A string summarizing the execution results.
Raises:
RuntimeError: If the agent is not in IDLE state at start.
"""
if self.state != AgentState.IDLE:
raise RuntimeError(f"Cannot run agent from state: {self.state}")
if request:
self.update_memory("user", request)
results: List[str] = []
async with self.state_context(AgentState.RUNNING):
while ( ## 循环停止的条件:达到最大步数,或agent的状态已经是完成的了
self.current_step < self.max_steps and self.state != AgentState.FINISHED
):
self.current_step += 1
logger.info(f"Executing step {self.current_step}/{self.max_steps}")
step_result = await self.step()
## Check for stuck state
if self.is_stuck():
self.handle_stuck_state()
results.append(f"Step {self.current_step}: {step_result}")
if self.current_step >= self.max_steps:
self.current_step = 0
self.state = AgentState.IDLE
results.append(f"Terminated: Reached max steps ({self.max_steps})")
return "\n".join(results) if results else "No steps executed"
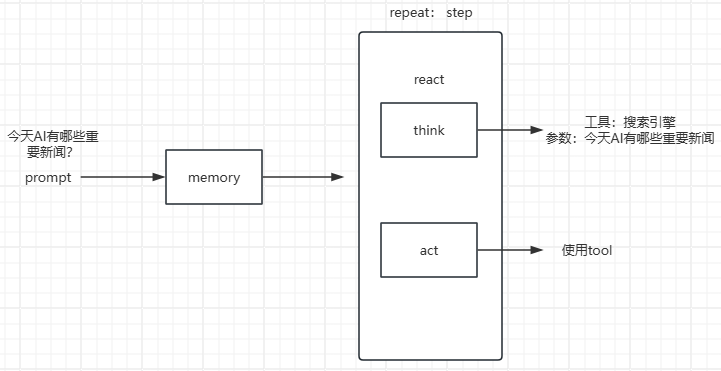
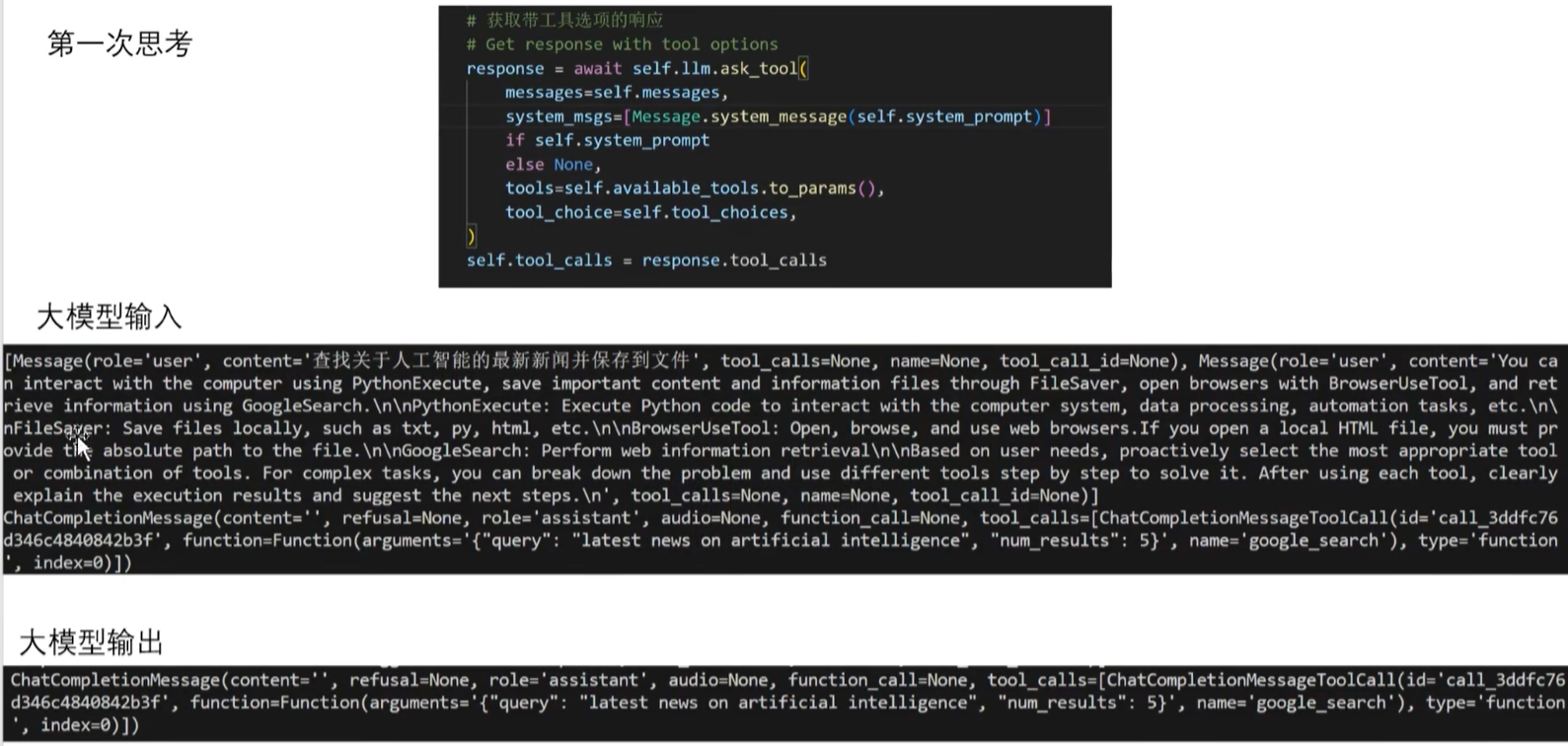
既然是 while 循环迭代,那每次迭代又有啥不一样的了?举个例子:查找 AI 最新的新闻,并保存到文件中。第一次 think,调用 LLM 的时候输入用户的 prompt 和相应的人设、能使用的 tool,让 LLM 自己�选择一个合适的 tool,并输出到 response 中!这里的 LLM 选择了 google search 去查找新闻,并提供了 google search 的 query!
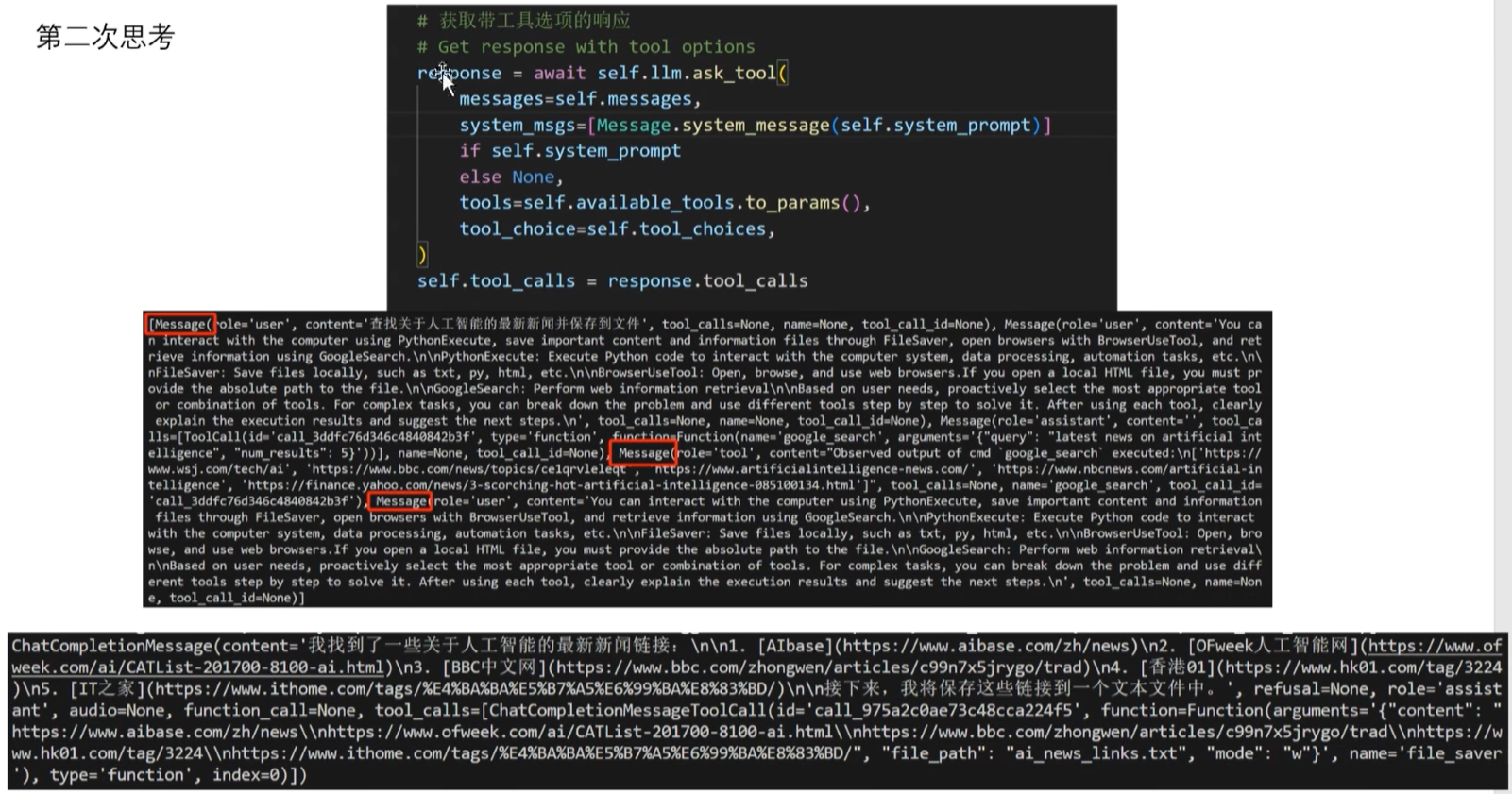
第二次 think,给 LLM 输入的 prompt 带上了第一轮的 prompt 和 response,类似多轮对话,把多个 context 收集到一起作为这次的最新的 prompt,让 LLM 继续输出结果,也就是第三次的 action 是啥!
第三次 think:同样包含前面两次的 promt!但这次 LLM 反馈已经不需要调用任何工具了,所以这个 query 至此已经完全结束!
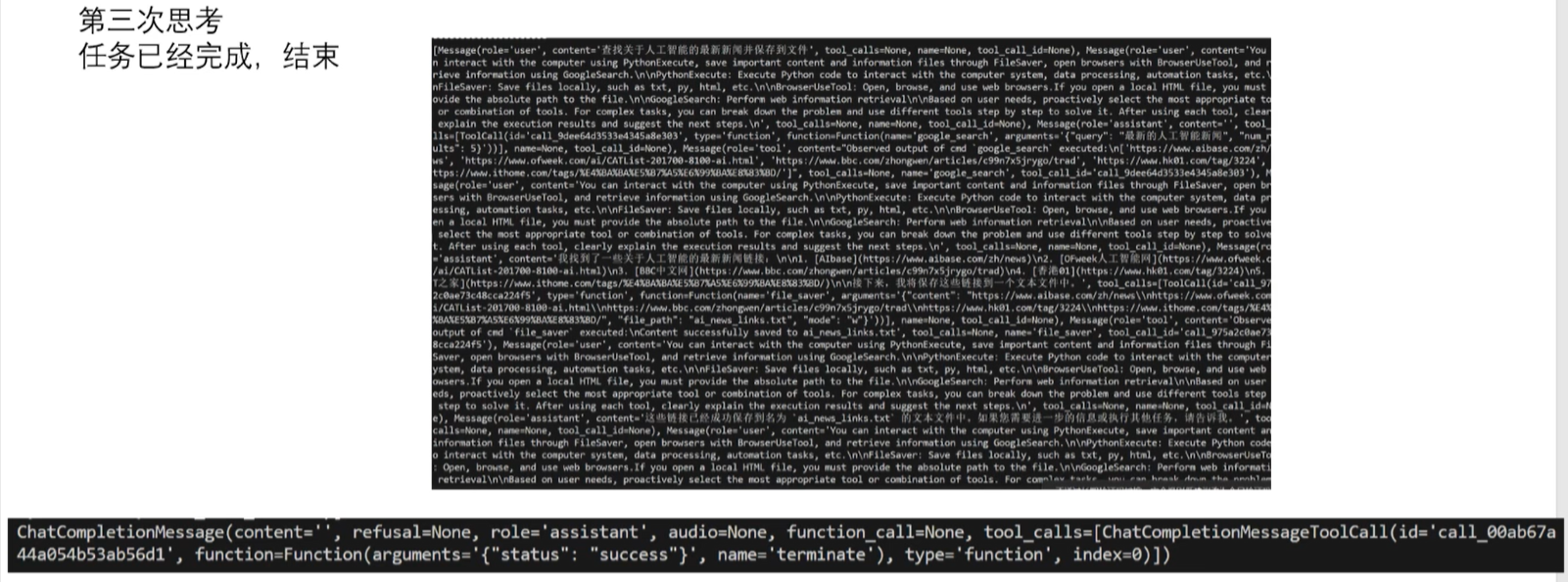
整个流程简单!另外,用户也可以添加自己的 tool,只要符合 MCP 协议就行!
openManus 的设计思路
从外部来看,Manus(以及复刻的 OpenManus)本质上是一个多智能体系统(Multi-Agent System)。不同于单一大模型那种一次性 "大而全" 的回答方式,多智能体系统通过 "规划—执行—反馈" 的循环,逐步解决复杂的真实世界问题。在 OpenManus 的设计中,最核心的思路可以概括为以下几点:
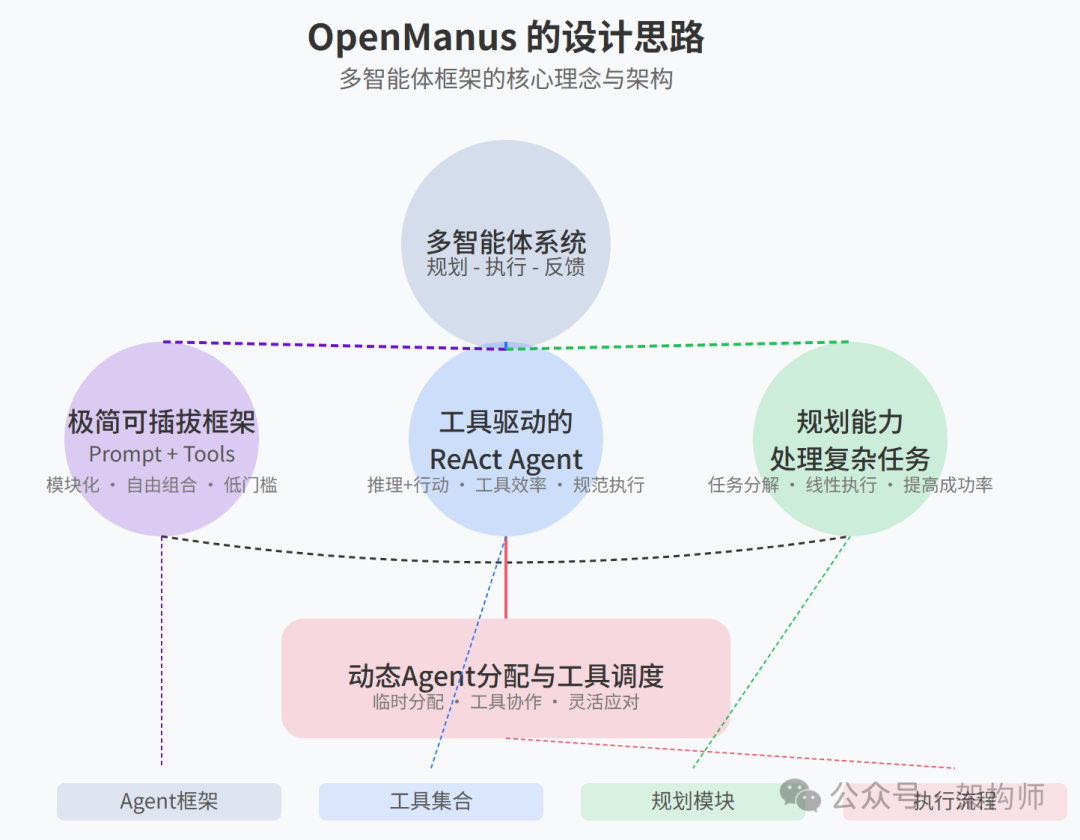
极简可插拔框架
OpenManus 的核心设计是构建一个非常精简的 Agent 框架,强调模块化和可扩展性。它通过可插拔的工具(Tools)和提示词(Prompt)的组合来定义 Agent 的功能和行为,降低了开发和定制 Agent 的门槛。
- Prompt 决定 Agent 的行为逻辑和思考方式
- Tools 则提供行动能力(如计算机操作、代码执行、搜索等)
通过对 Prompt 和 Tools 的自由组合,就能快速 "拼装" 出新的 Agent,赋予其处理不同类型任务的能力。
工具驱动的 ReAct Agent
OpenManus 基于 ReAct(Reason + Act)模式,并以工具为核心驱动 Agent 的行动。Prompt 引导 Agent 的推理和逻辑,而 Tools 则赋予 Agent 行动能力。ToolCall Agent 的引入,进一步提升了工具使用的效率和规范性。
规划能力处理复杂任务
OpenManus 延续了 Manus 的多智能体规划优势,将 PlanningTool 用于对用户需求进行高层规划。这种 "先规划,后执行" 的思路在复杂、长链任务上效果更佳。PlanningTool 将复杂的用户需求分解为线性的子任务计划,这种规划能力是处理现实世界复杂问题的关键。过去的研究表明,在相同模型能力下,如果缺乏��系统的分解和规划,许多真实问题的成功率会大打折扣;而加入规划后,成功率会有显著提升。
动态 Agent 分配与工具调度
当一个任务拆解出若干子任务后,系统会根据子任务类型,动态将其分配给预先定义或适配的 Agent(有各自的工具集和能力倾向)。这种 "临时分配 + 工具协作" 的机制,可以最大化利用多模型、多工具的组合优势,提高应对不同问题场景的灵活度。Agent 预先装备了不同的工具集以应对不同类型的任务,提高了系统的灵活性和效率。
工作流程与执行路径
OpenManus 的运行流程可以清晰概括为 "规划 → 分配 → 执行",具体步骤如下:
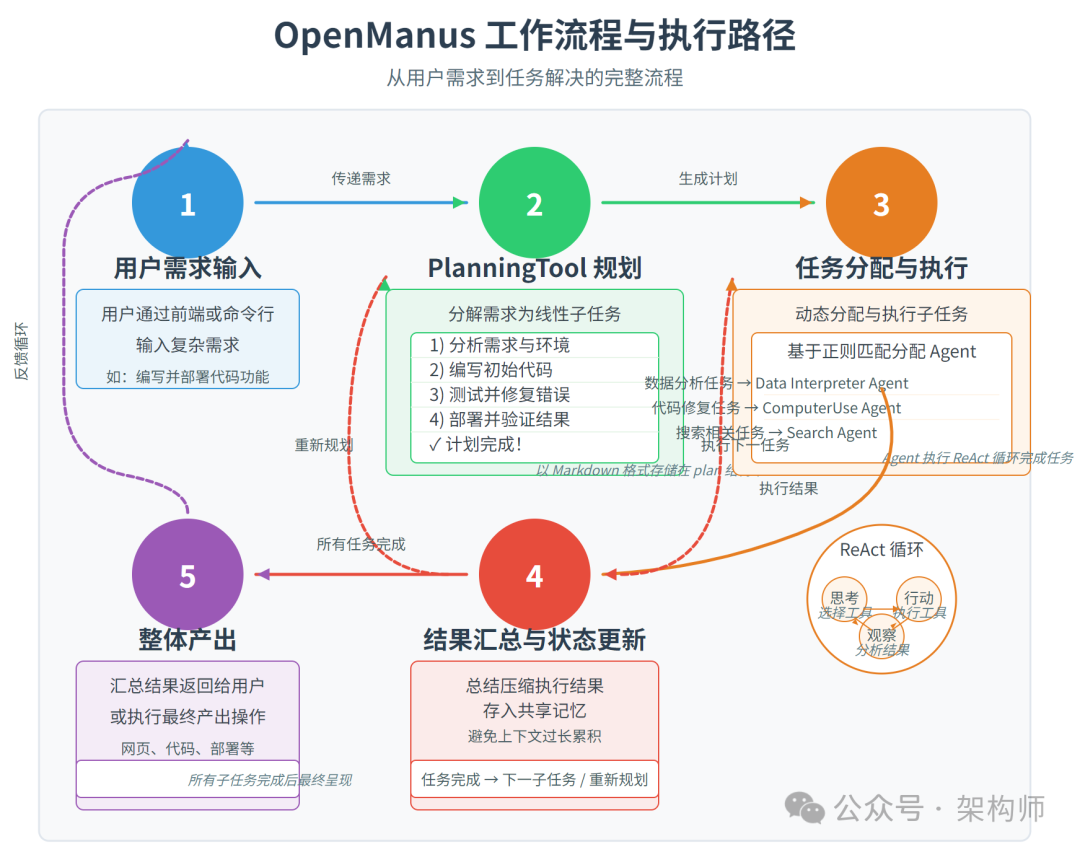
用户需求输入
用户在前端或命令行中输入复杂的需求,例如 "写一段代码完成某种功能,并自动部署到服务器上"。
PlanningTool 规划
系统先调用 PlanningTool,对需求进行分析与分解,形成一个线性结构的计划或任务序列。比如,会将需求拆解为:
-
分析需求与环境
-
编写初始代码
-
测试并修复错误
-
部署并验证结果
这些子任务被记录在一个 plan 或类似结构中。
任务分配与执行
如果任务中涉及大规模数据分析或机器学习流程,可能会调用一个具备 Data Interpreter 能力的 Agent;
若任务需要复杂的代码修复或文件管理,则会调用另一个能够使用 ComputerUse 工具的 Agent;
系统按照顺序从计划中依次取出子任务;
根据任务关键字或意图判定,分配给最合适的 Agent。目前 Agent 分配主要基于正则匹配,未来考虑使用 LLM 实现更智能的任务分配。
每个 Agent 都会采用 ReAct 循环(Reason + Act)与 Tools 进行交互,以完成自己所负责的子任务。
结果汇总与状态更新
当某个子任务执行完毕后,系统会将执行结果、关键上下文信息进行必要的 "总结与压缩"(以避免不断增加的冗长 Memory),然后存入当前的 "Plan 内存" 或全局可访问的共享内存。
如果任务完成顺利,进入下一子任务;
若出现执行失败或结果异常,系统可进行自动调试或重新规划,视�设计实现程度而定。
整体产出
当所有子任务执行完毕,系统对整体结果进行汇总并返回给用户,或完成如网页部署、自动执行脚本等操作。
在这个过程中,多 Agent + 工具的结构会在复杂需求上展现明显的优势,尤其当需要长链思考、结合搜索或外部工具时,能够更好地完成通用大模型难以一次性解决的工作。
技术架构剖析
工程结构概览
项目依赖相对简单,主要包括一些用于数据验证(pydantic)、AI 服务调用(openai)、浏览器控制(playwright、browsergym、browser-use)和一些基础工具库:
-
pydantic:数据验证和设置管理
-
openai:OpenAI API 的客户端库
-
browser-use:构建能使用网络浏览器的 AI 代理框架
-
browsergym:训练 AI 使用网络浏览器的环境
-
playwright:浏览器自动化库
-
googlesearch-python:无需 API 密钥进行搜索的库
这样的结构设计使得 OpenManus 在提供强大功能的同时保持了极高的可维护性和可扩展性。
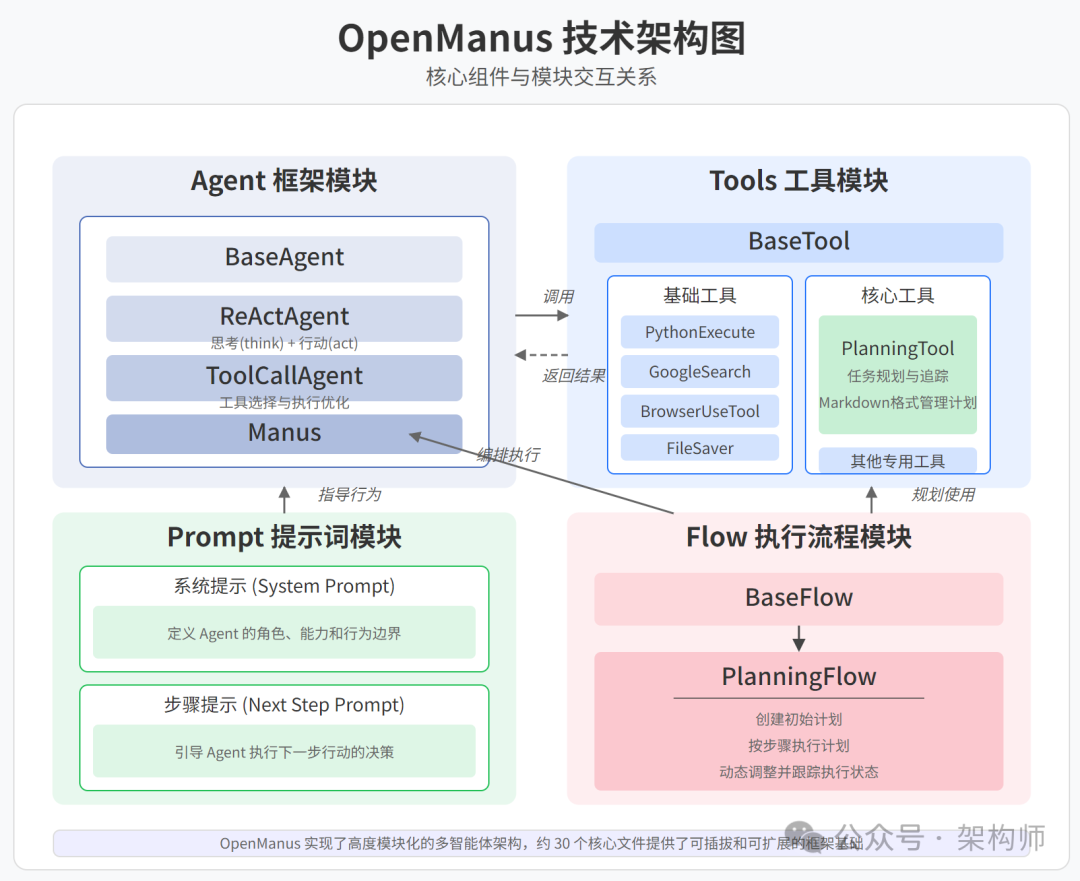
核心系统组件
OpenManus 的架构由四个主要模块构成:
核心多智能体框架(Agent)
Agent 模块采用清晰的继承层次,自底向上逐步增强功能:
示例代码(Manus 实现):
class Manus(ToolCallAgent):
"""
A versatile general-purpose agent that uses planning to solve various tasks.
"""
name: str = "Manus"
description: str = "A versatile agent that can solve various tasks using multiple tools"
system_prompt: str = SYSTEM_PROMPT
next_step_prompt: str = NEXT_STEP_PROMPT
## Add general-purpose tools to the tool collection
available_tools: ToolCollection = Field(
default_factory=lambda: ToolCollection(
PythonExecute(), GoogleSearch(), BrowserUseTool(), FileSaver(), Terminate()
)
)
-
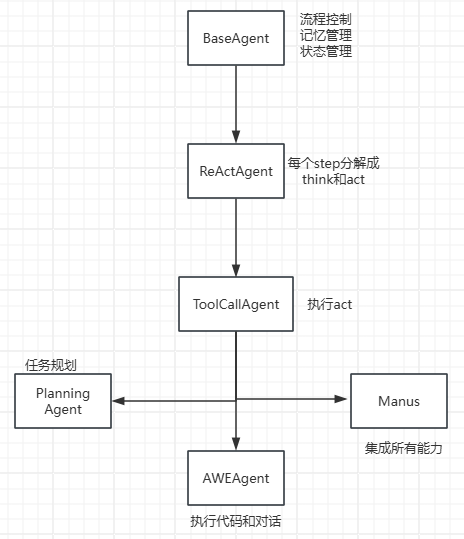
BaseAgent:定义了智能体的基础属性(name、memory、system_prompt)和基本行��为(执行逻辑、状态检查)。
-
ReActAgent:实现了经典的 "Reasoning + Acting" 模式,先思考后行动,每一步执行都分为 think 和 act 两个阶段。
-
ToolCallAgent:在 ReAct 基础上进一步细化,使 think 阶段专注于工具选择,act 阶段负责执行所选工具。
-
Manus:继承 ToolCallAgent,主要通过定制 system_prompt 和 available_tools 来赋予不同能力。
Tools(工具层)
工具模块是 OpenManus 的行动能力基础,各类工具均继承自 BaseTool:
其中,planning.py 实现了 Manus 著名的计划功能,用 Markdown 格式管理任务计划并跟踪执行进度。
-
ComputerUse:命令行和计算机操作
-
BrowserUse:网络浏览和交互
-
PythonExecute:执行 Python 代码
-
GoogleSearch:网络搜索
-
FileSaver:文件读写
-
PlanningTool:任务规划与追踪
Prompt(提示词模块)
Prompt 模块包含了各种 Agent 使用的指令模板,例如 Planning 的系统提示:
PLANNING_SYSTEM_PROMPT = """
You are an expert Planning Agent tasked with solving complex problems by creating and managing structured plans.
Your job is:
1. Analyze requests to understand the task scope
2. Create clear, actionable plans with the `planning` tool
3. Execute steps using available tools as needed
4. Track progress and adapt plans dynamically
5. Use `finish` to conclude when the task is complete
Available tools will vary by task but may include:
- `planning`: Create, update, and track plans (commands: create, update, mark_step, etc.)
- `finish`: End the task when complete
Break tasks into logical, sequential steps. Think about dependencies and verification methods.
"""
而 Manus 的系统提示则更加简洁:
SYSTEM_PROMPT = "You are OpenManus, an all-capable AI assistant, aimed at solving any task presented by the user.
You have various tools at your disposal that you can call upon to efficiently complete complex requests.
Whether it's programming, information retrieval, file processing, or web browsing, you can handle it all."
Flow(执行流程模块)
Flow 模块负责任务的高层编排和执行流程管理:
PlanningFlow 的执行流程:
每步执行前,系统会生成上下文丰富的提示:
step_prompt = f"""
CURRENT PLAN STATUS:
{plan_status}
YOUR CURRENT TASK:
You are now working on step {self.current_step_index}: "{step_text}"
Please execute this step using the appropriate tools. When you're done, provide a summary of what you accomplished.
"""
BaseFlow:抽象基类,定义了 Agent 管理和执行接口
PlanningFlow:实现基于规划的执行策略
创建初始计划(_create_initial_plan)
按计划步骤调用适当的 Agent
跟踪计划执行状态并动态调整
系统运行机制
基础版本(Manus)
-
用户输入需求,调用 Manus agent 的 run 函数
-
run 函数循环执行 step 操作(来自 ReActAgent)
-
每个 step 包含 think(选工具)和 act(执行工具)两个环节
-
直接使用基础工具集(Python 执行、搜索、浏览器、文件保存等)
高级版本(PlanningFlow)
-
使用 PlanningTool 对需求进行整体规划
-
针对每个子任务动态生成适合的上下文和指令
-
调用 Manus agent 执行各个子任务
-
维护计划状态和执行进度
值得注意的是,在当前版本中,虽然 PlanningFlow 具备多智能体调度的能力,但实际上只有单一的 Manus 智能体在执行任务。未来版本可引入更多专业化的 Agent 以充分发挥多智能体协作的优势。
Memory 管理与 Agent 分配
与前文描述一致,OpenManus 实现了简单但有效的记忆管理和 Agent 分配机制:
-
Memory 管理:每个子任务执行后进行总结压缩,避免上下文过长
-
Agent 分配:当前主要基于正则匹配和规则,后续可考虑 LLM 辅助分配
owl
在 AI 领域,开源项目正逐渐成为推动技术发展的重要力量。OWL Agent,一个由 CAMEL-AI 团队推出的开源 AI 智能体项目,不仅完全复刻了 Manus 的核心功能,还在灵活性和开源生态上实现了超越。深入了解 OWL Agent 如何帮助你零成本打造全能的开源 AI 打工人。
OWL 简介
OWL 的多智能体协作机制通过分层架构和模块化设计实现高效协作。它的核心组件包括 BaseAgent、ChatAgent、RolePlaying、Workforce 以及 Task 相关 Agent 等,这些组件各司其职,共同完成任务分解、角色分配和任务执行等功能。
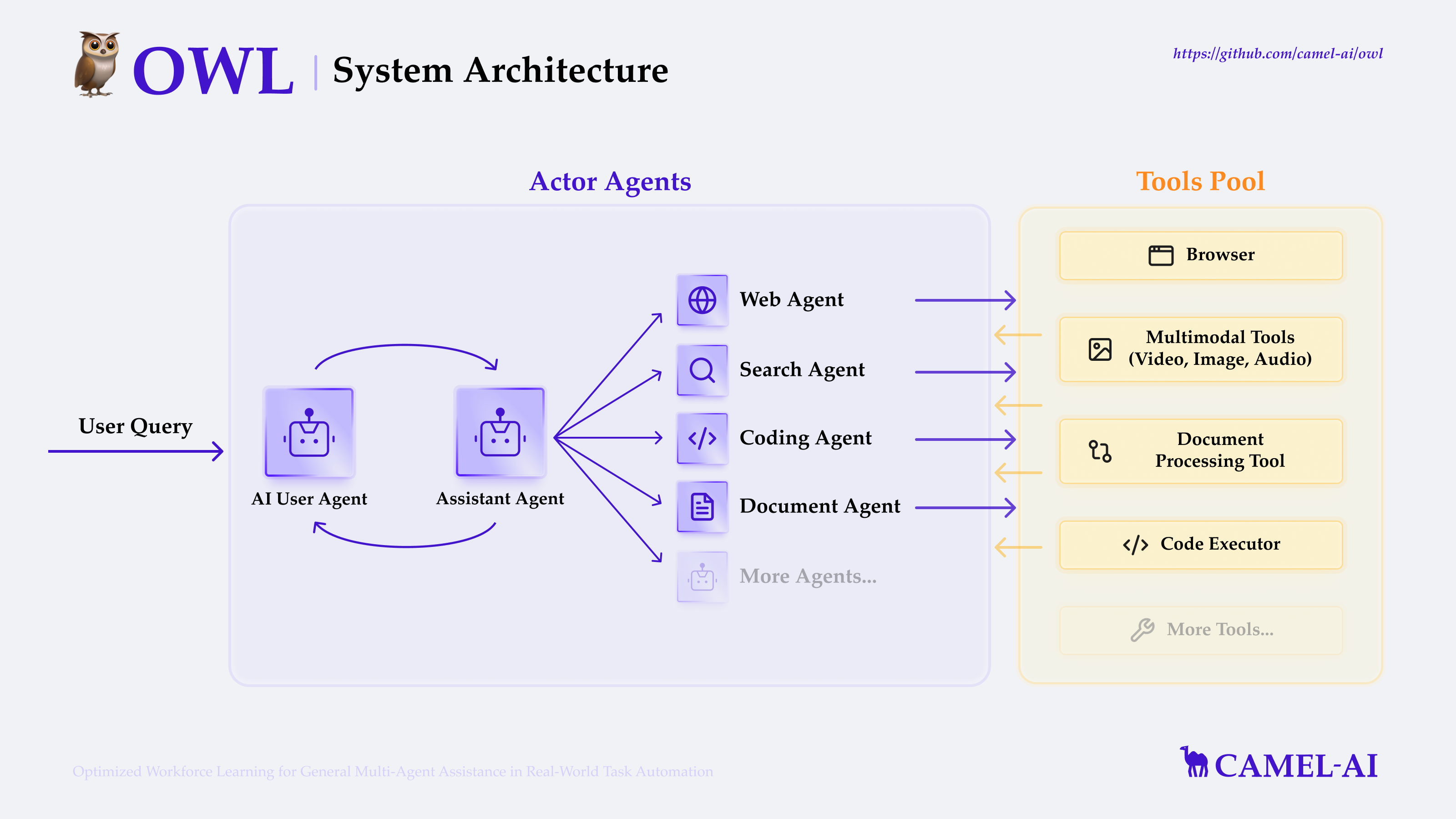
核心架构
OWL 的多智能体协作机制主要基于以下几个核心组件:
- BaseAgent:所有智能体的基类,定义了基本的 reset()和 step()接口
- ChatAgent:基础的对话智能体,负责管理对话和消息处理
- RolePlaying:实现两个智能体之间的角色扮演对话
- Workforce:实现多个工作节点(agents)协同工作的系统
- Task 相关 Agent:包括 TaskSpecifyAgent、TaskPlannerAgent、TaskCreationAgent 等,负责任务的分解、规划和创建
- RoleAssignmentAgent:负责根据任务分配合适的角色
架构特点
- 分层架构:通过层次化设计,提升系统的可扩展性和灵活性。
- 任务分解与优先级调整:通过 TaskPlannerAgent 和 TaskPrioritizationAgent 实现复杂任务的分解与优先级动态调整。
- 协作模式:支持多样化的协作方式,包括角色扮演和工作节点协同。
- 记忆管理:利用 ChatHistoryMemory 记录并管理对话历史。
- 工具与 API 集成:支持外部工具和 API 的扩展能力。
这种设计使 OWL 能够高效处理复杂任务,动态调整任务角色分配,提升多智能体间的协作效率,同时具备自适应学习和优化能力,满足多样化的应用需求。
核心功能
- 在线搜索:使用维基百科、谷歌搜索等,进行实时信息检索
- 多模态处理:支持互联网或本地视频、图片、语音处理
- 浏览器操作:借助 Playwright 框架开发浏览器模拟交互,支持页面滚动、点击、输入、下载、历史回退等功能
- 文件解析:word、excel、PDF、PowerPoint 信息提取,内容转文文本/Markdown
- 代码执行:编写 python 代码,并使用解释器运行
核心工作流
OWL 将 Manus 的核心工作流拆解为以下六步:
- 启动 Ubuntu 容器,为 Agent 远程工作��准备环境。
- 知识召回,快速调用已学习的内容。
- 连接数据源,覆盖数据库、网盘、云存储等。
- 数据挂载到 Ubuntu,为 Agent 提供数据支持。
- 自动生成 todo.md,规划任务并创建待办清单。
- 使用 Ubuntu 工具链和外接工具执行全流程任务。
Ubuntu Toolkit
为了实现 Agent 的远程操作,OWL 配备了强大的 Ubuntu Toolkit,支持以下功能:
- 终端命令执行,满足运维和部署需求。
- 文件解析,支持 PDF 转 Markdown、网页爬取等。
- 自动生成报告、代码和文档,直接交付成果。
- 浏览器操作,支持滚动、点击、输入等交互。
Memory Toolkit
与 Manus 类似,OWL 也具备记忆功能,能够实时存储新知识,并在任务中召回过往经验。这使得 OWL 在处理类似任务时更加高效。
CRAB+OWL:跨平台掌控力
在 Manus 爆火之前,CAMEL-AI 已经开发了 CRAB——一套强大的跨平台操作系统通用智能体。CRAB 不仅能操控 Ubuntu 容器,还能直接控制手机和电脑中的任何应用。未来,CRAB 技术将融入 OWL,实现跨平台、多设备、全场景的远程操作。
在 AI 领域,开源的力量是无穷的。OWL 项目不仅在 0 天内复刻了 Manus ��的核心功能,还通过开源模式吸引了全球开发者的参与。它不仅性能卓越,还具备高度的灵活性和扩展性。
OWL 和 openmanus 功能对比
| 维度 | OWL | OpenManus |
|---|---|---|
| 执行环境 | Docker 容器 + 原生系统穿透 | 本地沙箱环境 |
| 任务复杂度 | 支持多设备联动任务 | 单设备线性任务 |
| 记忆系统 | 增量式知识图谱(支持版本回溯) | 临时记忆池(任务级隔离) |
| 资源消耗 | 单任务平均 8 万 tokens | 单任务峰值 24 万 tokens |
| 扩展性 | 插件市场 + 自定义工具链 | 固定模块组合 |
OWL Agent 作为一个开源 AI 智能体项目,不仅在性能上达到了行业领先水平,还在成本和灵活性上具有显著优势。它为开发者和用户提供了一个零成本、高性能的 AI 工具,能够满足多种应用场景的需求。
agent 发展史
1.裸大模型调用
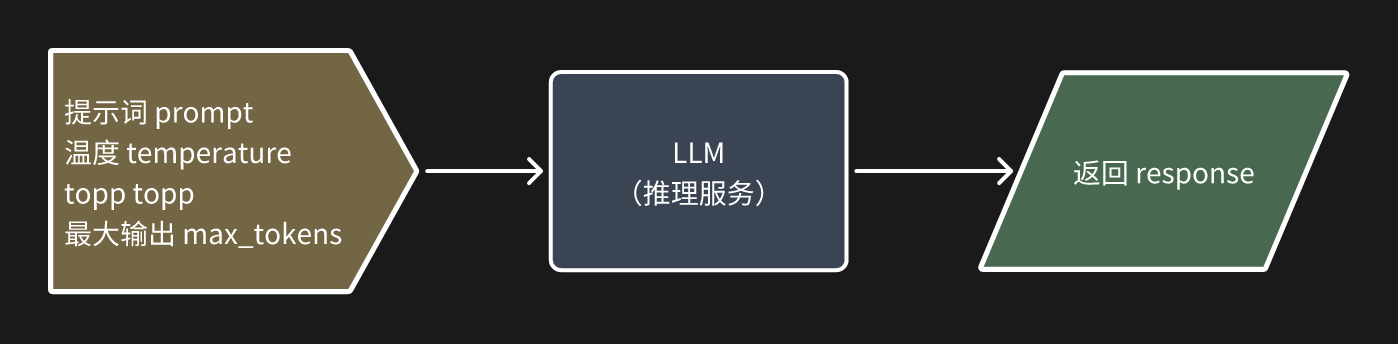
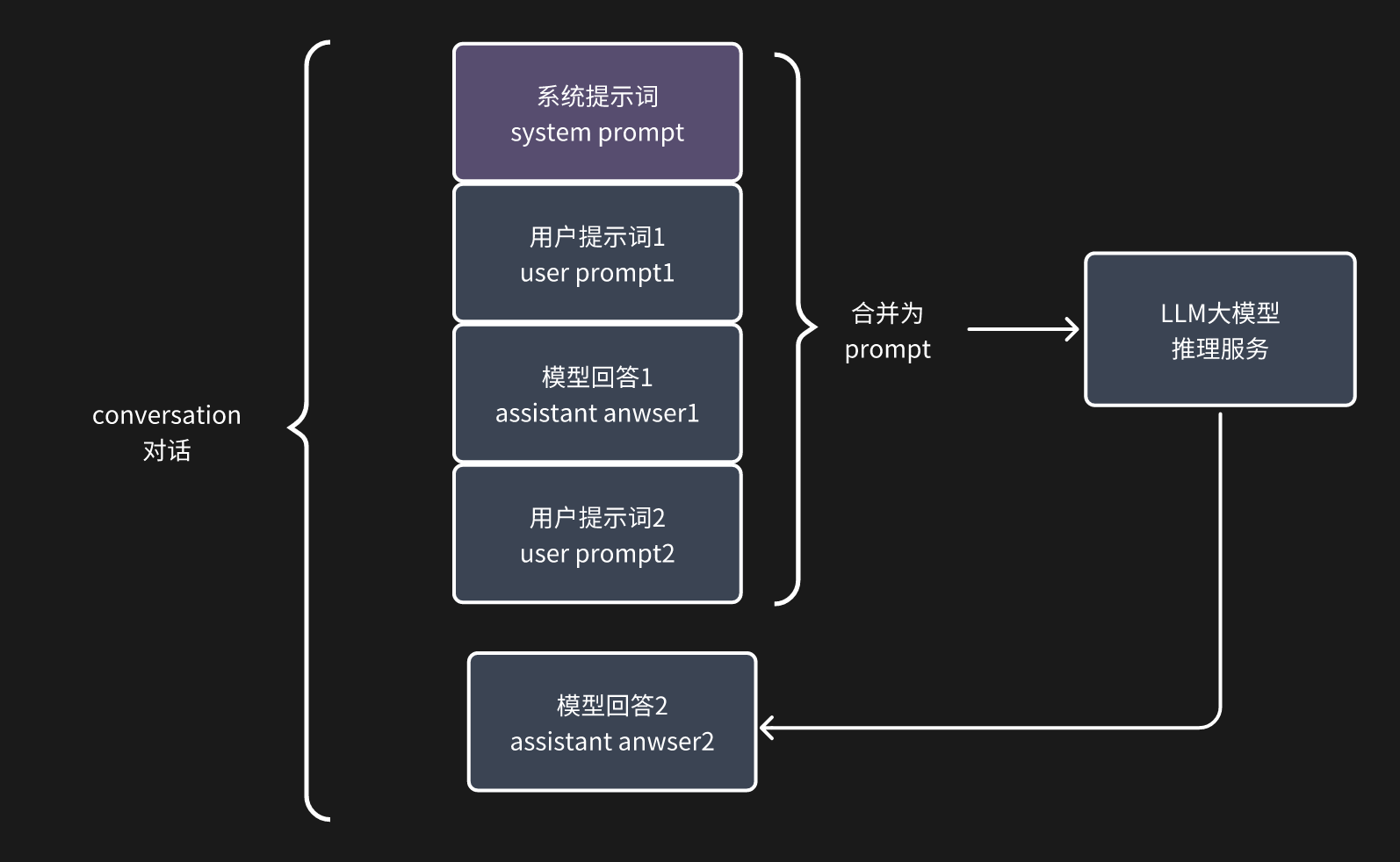
2.最简单的智能体:简易 Chatbot
- 在裸大模型调用上进行了简易的封装,变成了对话机制的 chatbot
- 要注意的是每一轮对话,都会包括 系统提示词 + 历史对话 + 最新一轮用户输入
3.智能体概念初期(Langchain)
- Langchain 是一个非常古老的智能体项目
- 主要提出了智能体的概念和组成部分,对后世影响巨大
- 设计时概念:
- 智能体 Agent。表示了一个可能包含 AI 步骤,能够自动完成多步任务的程序。Agent 由以下部分组成。
- 步骤/链条 Chain。表示一个有输入有输出,会进行处理的步骤。
- 常见的 Chain 是 LLMChain,也就是大模型步骤。
- 实际上也可以包括任何其他形式的处理。
- 路由 Router。用于判断接下来该进行哪个 Chain。
- 可能通过某些数值或者条件来进行判断。
- 但实际上 LLMRouter 也很常见,也就是你问大模型接下来是应该走哪个 Chain。
- 工具 Tool。类似于搜索,计算器,日期这样的工具调用。与 Chain 的主要区别在于,tool 是在 Chain 上的一次调用还会返回 Chain。
- 运行时概念:context 上下文,status 状态。
【金融场景:搜索+知识库 rag】
4.多智能体 Multi-agent
- 大致可以理解成多个 Agent 进程/线程会并行工作,相互之间通过某些机制进行沟通(例如消息队列)
- 典型案例:metagpt 的多角色协同(产品、后端、前端、测试),斯坦福小镇
- 不出现并行工作的,不是 Multi-agent;coze 上所谓的“Multi-agent”就是典型的错误概念,因为它只是不同的 agent 之间串行流转。
5.长任务智能体
- 通常需要较长的步骤或者较多的时间才能完成,需要进行 agentflow 编排。
- Copilot 类。
- 希望有人工进行干预,有可能允许人工修改参数,选择参考资料,甚至决定路由。
- 典型:Flowith(oracle 模式)
- Agentic 类。
- 追求更高的自动化程度,极少需要人工干预。
- 典型:autogpt,Manus,metagpt,gemini deep research
【autogpt】
6.短任务智能体
- 通常追求的是更快的响应时间,因为人类对这类场景的响应时间有要求。
- 虚拟人
- AI 游戏
- 硬件相关,例如:智能家居、车载、智能音箱
MultiAgent:协作形态、关键技术与现实判断
MultiAgent 不是“多开几个模型实例”,也不是“把三个终端一起跑”。它更像是在组织一套可分工、可协作、可治理的智能系统。
这篇稿子不打算只从 CodeAgent 视角聊这个话题。
我这次更想把它横着讲清楚:
- 它为什么在 2024 到 2026 重新变热
- 它到底有哪些主流技术路线
- 哪些场景真的适合多 Agent,哪些只是想象很美
- 今天谈 MultiAgent,到底应该抓哪些原则,警惕哪些坑
这篇文章主要基于 Anthropic、OpenAI、Google、Microsoft、MCP 官方文档、IJCAI 和 OpenReview 的资料来写。
我会尽量把判断写成“资料事实 + 基于资料的归纳”,而不是凭印象喊口号。
为什么现在必须重新看 MultiAgent
严格说,MultiAgent 根本不新。
多智能体系统本来就是传统 MAS(Multi-Agent Systems,多智能体系统)和分布式人工智能里的老题目。IJCAI 2024 的综述 和 OpenReview 2024 的综述 都已经把这条历史线梳理得很完整。所以今天重新看 MultiAgent,不是因为这个词突然被发明出来了,而是因为 问题的重心变了。
以前大家讨论 AI,核心问题更像是:模型够不够聪明,回答够不够像人,补全够不够快。
但到了 2024 到 2026,这个问题开始不够用了。越来越多真实任务卡住的,不是模型会不会说,而是一个单体 Agent 根本不适合同时承担这么多事:它既要理解目标,又要调工具、跨系统、维持长上下文、处理异步反馈、自己给自己验收,最后还要保证别失控。换句话说,瓶颈正在从“模型能力”迁移到“系统组织能力”。
如果把这件事翻成人话,其实很像下面这个场面:
你让一个 Agent 一个人同时干 PM、开发、测试、值班同学和 reviewer 的活。它前一秒��在读需求,下一秒要去查资料、调工具、改代码、跑测试、写总结,中途还得处理新插进来的反馈和越来越长的上下文。它不是不聪明,而是你把太多原本就该分开的职责,一股脑塞给了一个执行单元。
这时候系统开始出问题,真的不奇怪。奇怪的是,过去我们居然经常默认这套做法应该成立。
这才是今天必须重新看 MultiAgent 的真正原因。
不是因为“多几个 Agent 看起来更高级”,而是因为很多任务已经开始逼着我们承认:单 Agent 不是万能执行单元,很多时候它只是一个被过度期待的总包工头。
Anthropic 在 2024 年 12 月 19 日发布的《Building Effective AI Agents》 和 OpenAI 在 2025 年 3 月 11 日发布的《New tools for building agents》 其实都在释放同一个信号:Agent 已经不只是聊天技巧,而是在进入真正的系统工程阶段。到了这个阶段,问题就自然会升级成:
- 任务怎么拆
- 上下文怎么分
- 谁来执行,谁来验收
- 长任务怎么恢复
- 出问题时怎么追踪、怎么治理
一旦问题变成这样,MultiAgent 就不再是“要不要追新概念”,而是“有没有必要重新设计系统组织方式”。
再往下看,Anthropic 在 2025 年 6 月 13 日公开的 multi-agent research system 把这个转折讲得特别直接:多 Agent 真正成立,不是因为它让模型突然更聪明了,而是因为它让系统终于能把广度探索、并行检索、跨上下文压缩这些单 Agent 很难同时做好��的事情拆开处理。这是一个很关键的信号,它说明 MultiAgent 的价值开始从“概念想象”变成“在某些任务里确实更合适的结构”。
与此同时,企业侧的诉求也在变。ServiceNow、Workday 和 Microsoft Azure AI Foundry 这些材料背后讲的根本不是“多 agent 很酷”,而是另一件更现实的事:企业已经不满足于一个会回答问题的助手,它们要的是一套能跨角色、跨系统、跨流程协作,还能被管理、被问责、被治理的智能流程层。
这时候再看 MCP 和 A2A,你会发现它们的重要性也不是“又多了两个名词”,而是行业终于开始认真补基础设施了。MCP 的起点更偏 agent <-> tool / resource,A2A 更偏 remote agent service <-> remote agent service。而且到 2026 年,MCP 自己也已经开始往 UI、任务和 agent communication 延展。这不代表标准已经统一,但至少说明大家已经意识到:如果继续每家都写私有胶水代码,MultiAgent 很难真的长成产业能力。
最后,真正让我觉得这个方向必须重看的,不是热度,而是冷水。OpenReview 在 2025 年发布的《Why Do Multiagent Systems Fail?》 和 《Why Do Multi-Agent LLM Systems Fail?》 很重要,因为它们把话题从“MultiAgent 能干什么”往前推了一步,开始问“MultiAgent 为什么经常干砸”。这意味着行业已经不只是沉迷想象力,开始进入更像工程学的阶段了:要讨论 specification、coordination、verification、observability 和治理。
一句话判断
今天重新看 MultiAgent,不是为了追热词,而是因为 AI 系统真正难的部分,正在从“让模型回答”变成“让一套智能系统长期协作而不失控”。
这波热度当然有 hype,但它背后对应的问题也确实比以前更真了。
先别把所有 MultiAgent 混成一个词
今天很多文章的问题,不是资料少,而是把完全不同的东西都叫成了 MultiAgent。读者一眼看过去,会觉得这些词都认识,但根本不知道差别在哪里。
如果你也有过这种感觉: 一会儿看到它像“团队协作”,一会儿又像“工作流编排”,再往后又突然变成“协议互通”或者“自治网络”,那多半不是你没看懂,而是很多文章确实把不同层面的问题混着写了。
如果要把这件事讲明白,我觉得不能先扔术语,得先回答三个更人话的问题:
- 谁在指挥? 是不是有一个总协调者统一拆任务、分配工作、汇总结果?
- 任务怎么流? 是按固定步骤接力推进,还是多个 Agent 同时展开,再回到一起?
- Agent 靠什么协作? 是互相发消息、围着共享状态工作,还是干脆各自独立协商?
只要这三个问题想清楚,很多看起来很玄的名词就会突然变得很好懂。
先别急着记术语
先拿这三个问题去压一遍任何一个系统:
- 谁在指挥
- 任务怎么流
- Agent 靠什么协作
能回答这三句,再去看它叫
team、swarm、workflow还是committee,基本就不太容易被名字带跑。
还有一句最好先讲死:这三个问题是三个观察维度,不是一棵只能选一条分支的分类树。
一个系统完全可能同时满足这几句:
- 控制上是中心化的
- 任务组织上是
orchestrator-worker - 状态上围着
shared state工作 - 运行时又靠
event-driven往前推
很多文章写乱,就是因为前面刚把维度分开,后面又把不同维度的答案重新揉成一团。
先看“谁在指挥”
最粗的一刀,其实是看控制拓扑,也就是谁在掌控全局。
中心化编排
这类系统有一个明显的主脑,或者至少有一个主控制流。
人话一点,就是:
- 有一个总负责人知道目标是什么
- 它决定把任务拆给谁
- 它决定什么时候继续、什么时候停止
- 最后也是它来汇总结果
这类系统更像“项目经理带专项同事”。
现在公开的一手工业案例,大多数都偏这一类。比如 Anthropic 的 multi-agent research system,本质就是 orchestrator-worker。好处是清楚、好 debug、好加护栏;坏处是主协调者容易变瓶颈。
去中心化协作
这类系统没有单一主控,多个 Agent 更像平等节点。
人话一点,就是:
- 没有一个“总经理”永远说了算
- 每个 Agent 会根据局部信息和能力做决定
- 它们之间更像协作网络,而不是上下级关系
这类系统更像“多个独立团队临时联合干活”。
AgentNet 这类研究很看重这条路,因为中心化天然有单点瓶颈、扩展性问题和隐私边界问题。但它的工程难度也更高:路由怎么收敛、冲突怎么解决、谁来背责任,这些都更难。
再看“任务怎么流”
在“谁指挥”之外,第二个关键问题是:主任务到底按什么路径往前推进。
这里读者最容易混淆的一点是:任务怎么流,不等于 Agent 之间怎么说话。很多系统表面上看上去很热闹,好像到处都在消息乱飞,但真正决定系统骨架的,往往还是主任务到底怎么推进。
这里先只看两种最常见的主路径:
- 一种是有人拆题、派工、回收结果
- 一种是按固定步骤接力推进
像 committee、blackboard、async messaging 这些,不是主路径本身,更像协作和收敛机制,我放到下一节单独讲。
监督者 / Orchestrator-Worker
这是今天最容易落地,也最常见的一种。
它的基本逻辑是:
- 一个 supervisor 先理解总任务
- 把任务拆成多个子问题
- 分给不同 worker
- 最后再把结果收回来整合
它最像什么?最像一个总协调者带一组专项执行者,也最像现实团队里的“项目经理 + 专项同事”。
它适合什么?
- Research
- 宽搜型信息处理
- 可以明显拆成几个子问题的大任务
它的主要好处是:
- 责任边界清楚
- 上下文容易隔离
- 结果更容易汇总
它的主要坏处是:
- supervisor 很容易变成瓶颈
- 一旦主脑判断错了,整串任务都会跟着偏
- 如果拆分本身�不合理,worker 再努力也没用
Example:CodeAgent SubAgent 怎么像一个监督者系统
流水线 / Graph Workflow
这一类不要想成“大家在开会”,要想成“大家在接力”。
它的逻辑是:
- 第一个 Agent 做完第一步
- 结果交给第二个 Agent
- 第二个做完再交给第三个
- 整条链像流程图一样往前走
它最像什么?最像审批流、生产流水线或者一个可回放、可恢复的任务图。
它适合什么?
- 企业流程
- 长任务 orchestration
- 需要断点恢复、回放、人工插手的场景
为什么很多团队喜欢它?
- 可预测
- 好观察
- 好恢复
- 适合合规和人工接管
它的主要坏处是:
- 前面一环歪了,后面全会跟着歪
- 流程过于僵硬时,不适合探索型任务
- 图越来越复杂后,维护成本会上升得很快
Example:企业报销为什么更像流水线,不像开会
最后看“Agent 靠什么协作 / 收敛”
前面两节讲的是“谁在带队”和“主任务怎么走”。但真实系统真正容易写乱的,往往是第三件事:Agent 彼此到底靠什么交换信息、共享中间结果、收敛结论。
这一层才是很多文章最喜欢一股脑混成 swarm、committee、blackboard、async、peer-to-peer 的地方。它们也不是互斥的,很多系统会同时出现两三种。
评审 / 辩论 / Committee
这一类的核心不是“分工执行”,而是“多视角交叉判断”。
它的逻辑是:
- 多个 Agent 对同一问题独立思考
- 它们互相批评、投票,或者由一个 judge 汇总
- 最终不是看谁先说,而是看谁更站得住
它最像什么?最像作者、评审、元评审者组成的小型评审会,或者同一份方案被不同角色交叉 review。
它适合什么?
- 高不确定性推理
- 方案评审
- 红队、安全、judge 类任务
它的主要价值是:
- 不是更快,而是更稳
- 当你不希望单个 Agent 一路自洽到底时,这类机制特别有用
它的主要坏处是:
- 很贵
- 很耗 Token
- 很容易出现“多数人一起错”
Multi-LLM Debate 就提醒过,辩论不一定天然带来更好答案,它也可能收敛成多数意见,甚至放大共同误区。
Example:一份并购分析报告怎么用 Committee 做交叉判断
共享状态 / Blackboard
这一类最容易被写糊。
它不是“Agent 之间一直互相聊天”,而是多个 Agent 围着同一个共享工作区工作。
它的逻辑是:
- 大家不是直接互相来回传话
- 而是把中间结果写进共享状态
- 其他 Agent 再根据共享状态决定下一步动作
它最像什么?最像多人围着同一块白板工作,或者围着同一份不断更新的任务面板工作。
它适合什么?
- 需要回放、审计、断点恢复的系统
- 长任务 orchestration
- 需要明确状态流转的系统
为什么这类模式重要?
- 很多长任务系统真正需要的,不是 endless chat,而是一个可追踪、可恢复、�可审计的状态空间
- LangGraph 的 StateGraph 就很适合拿来理解这一点
它的主要坏处是:
- 状态 schema 很难设计
- 并发更新容易冲突
- reducer 和状态合并逻辑一复杂,系统会越来越像状态机地狱
Example:复杂客服工单为什么更适合共享状态
事件驱动 / Asynchronous Messaging
这一类更接近真实分布式系统。
它的逻辑是:
- Agent 不一定同步轮流说话
- 谁收到事件、谁满足条件,谁就开始干活
- 任务可以异步推进,不必所有人都等同一个时钟
它最像什么?最像消息队列、工单系统或者事件总线。
它适合什么?
- 多系统集成
- 长任务
- 企业级 runtime
为什么这类模式值钱?
- 弹性更强
- 更适合跨系统
- 更适合异步长任务
AutoGen Core 对这一层就讲得很清楚,它的底层更偏 actor model 和异步消息,不是单纯的多轮聊天�。
它的主要坏处是:
- 调试明显更难
- 重试、幂等、状态一致性、事件顺序都会变成真问题
- 业务链一长之后,很容易出现“事情在跑,但没人能一眼看懂现在跑到哪了”
Example:生产事故响应为什么更能体现事件驱动
对等 / Peer-to-Peer / Decentralized
这是最容易让人脑补出“智能体社会”的一类。
它的逻辑是:
- 没有固定主控
- 多个 Agent 按能力和局部信息自己协商
- 网络结构本身会影响协作效果
它最像什么?最像多个独立组织共同完成一件事,而不是一个团队内部排班。
它适合什么?
- 跨组织协作
- 强隐私边界场景
- 没有谁愿意把全部控制权交给中心节点的系统
为什么它吸引人?
- 理论上更可扩展
- 更适合跨组织和隐私边界
- 不容易形成单点瓶颈
它的主要坏处是:
- 最难治理
- 谁可信、谁说了算、怎么防串谋、怎么防死循环、怎么保证收敛,全是硬问题
所以这类路线很值得关注,但至少从今天公开的一手工业材料看,它更像前沿方向,不像默认起点。
Example:多机器人仓储协同为什么更能体现去中心化
两个最近很值得看的案例
如果这一节要讲,我觉得就别再讲词义了,直接看案例。
因为今天真正有信息量的,不是 Agent Team 和 Agent Swarm 这两个词本身,而是:最近最有信息量的公开案例,到底把多 Agent 做成了什么样子。
我会抓两个案例。
案例一:Claude Code Agent Teams
这是最近最典型的“把多 Agent 做成团队协作产品”的例子。
根据 Claude Code 官方文档,Agent Teams 目前还是 experimental,但它已经把很多过去只停留在 demo 里的东西做成了明确机制:
- 一个
team lead负责整体协调 - 多个
teammates作为独立 session 并行工作 - 团队围着
shared task list推进 - 队员之间可以��通过
mailbox直接通信 - 每个 agent 都有自己的上下文窗口,可以单独被打断、重定向和继续执行
这套设计为什么值得看?因为它把多 Agent 最现实的一类需求做出来了:不是让一群 Agent 一起“思考”,而是让它们像一个真实小组一样分工干活。
如果再看 Anthropic 在 2026 年 2 月 5 日发布的《Building a C compiler with a team of parallel Claudes》,这个方向会更清楚。那篇文章最有价值的不是“很多 agent 一起写编译器”这个噱头,而是它把工程上真正难的东西暴露出来了:
- 多个 agent 并行时,怎么避免撞车
- 谁来锁任务,谁来合并结果
- 怎么让 review agent 和实现 agent 分开
- 怎么靠测试和 harness 保证团队没有一起跑偏
所以 Claude Code Agent Teams 这个案例真正说明的是:
MultiAgent 的一个重要方向,不是继续强化单个超级 Agent,而是把任务所有权、并行执行、review 和回收结果做成团队闭环。
案例二:Kimi K2.5 的 Agent Swarm 研究预览
如果说 Claude Code 代表的是“把团队协作产品化”,那 Kimi K2.5 更像另一条线:把大规模动态拆分和集群协作能力往模型侧和 runtime 侧推。
按 Kimi K2.5 技术报告 里的描述,这条线最值得��看的,不是名字,而是它背后的协作原理:
- 不是先把角色和 workflow 全部写死
- 而是围绕大目标,动态决定还要不要继续拆
- 把并行探索规模直接拉到最多 100 个 sub-agents、1500 个协同步骤
- 同时保留一个可训练的 orchestrator,负责拆解、调度和回收子任务结果
这其实是在做一件很明确的事:把“任务怎么拆、拆到多细、哪些支线该并行”从人工预设流程,往系统自己的调度能力上推。
所以 Kimi 这条线真正想推的,不只是“多起几个 agent”,而是:
- 让系统自己决定该不该继续拆
- 让并行探索规模大幅上去
- 让长链路任务不再只能靠人工预先写死 workflow
- 但同时,又不是完全放弃协调者,而是把协调本身也做成可训练能力
所以这个案例真正值钱的地方,不是 Swarm 这个词够不够帅,而是它把另一种多 Agent 方向讲得很具体:
MultiAgent 不一定只是在 UI 层做团队协作,也可以在模型和 runtime 层把动态拆解、并行扩张、长链路协同本身推到更大规模。
如果想看它的原始技术描述,可以直接看 Kimi K2.5 技术报告 和 Moonshot 平台的 Agent Support 文档。
这两个案例合在一起,说明了什么
如果把这两个案例放在一起看,我觉得最值得讲�的,不是“谁才代表真正的 Team 或 Swarm”,而是它们在不同层面回答同一个问题:
- Claude Code 更像把“组织形态”显性化,让 lead、teammates、task ownership、mailbox 这些关系直接长在产品交互里
- Kimi K2.5 更像把“动态拆解和并行扩张”往模型与 runtime 内部推,把拆题和调度本身做成系统能力
前者更强调可见的团队协作界面。
后者更强调更深一层的调度与扩张能力。
所以这两个案例不是在争一个标准答案,而是在不同层面推进 MultiAgent:
- 一个把组织关系做得更清楚
- 一个把并行协同做得更大
这一节真正该记住的
看
Claude Code Agent Teams,重点看它怎么解决分工、review、任务回收和并行开发。看
Kimi K2.5,重点看它怎么把动态拆分、并行协同和长链路执行做大。这两个案例真正说明的,不是两个词是什么意思,而是多 Agent 现在正在往哪两边长。
如果不想只看开发者工具,还有这些公开产品也值得看
如果只盯着 Claude Code 和 Kimi,视野还是太窄了。公开产品里,至少还有下面几类很值得看,而且它们各��自代表的问题完全不同。
- Microsoft Agent Framework 1.0,2026 年 4 月 3 日 这个例子最适合看“多 agent 编排开始从实验框架走向生产 SDK”。它把
multi-agent orchestration、跨运行时互通和稳定 API 一起推到 1.0,说明这条线已经不再只是研究玩具。 - Oracle Fusion Agentic Applications,2026 年 3 月 24 日 这个例子最适合看“多 Agent 开始直接长进企业业务软件本体”。它强调的是由一组有不同职责和决策权限的 agent team 去持续推进业务目标,而不是只做一个外挂式助手。
- IBM watsonx Orchestrate 的 Multi-agent Orchestration 当前产品页 这个例子最适合看“多 Agent 已经被做成正式可卖的企业编排层”。它把 supervisor、router、planner、workflow styles 和治理放在同一个产品能力里,讲得非常直接。
- NVIDIA Multi-Agent Warehouse AI Command Layer,2026 年 1 月 9 日 这个例子最适合看“MultiAgent 不只发生在聊天窗口,也会进入物理世界的运营系统”。它把仓储里的设备、人员、安全、预测、文档理解拉进同一个 command layer,很适合说明多 agent 为什么会长到真实业务系统里。
- Kimi K2.5,2026 年 1 月 这个例子最适合看“模型�侧怎么把 cluster 协作和动态拆解往更大规模推”。它代表的不是传统工作流编排,而是更底层的 agent cluster 能力。
- Anthropic《Building a C compiler with a team of parallel Claudes》,2026 年 2 月 5 日 这个例子最适合看“多 Agent 公开案例里,真正难的是怎么组织团队而不是怎么凑人数”。它把并行开发、review、测试、任务锁定和结果回收写得非常具体。
- Oracle AI Agents for Supply Chain,2026 年 2 月 10 日 这个例子最适合看“多 Agent 怎么进入高约束、强流程、跨职能的企业场景”。它不是在讲一个抽象 agent,而是在讲供应链计划、采购、制造、物流这些角色怎么被 agent 化。
把这些形态压成一张表
如果只想先建立一个最小判断框架,可以先记这张速查表。
这张表是速查表,不是严格 taxonomy
它故意把最常见的“长相”压在一起,里面同时混了控制拓扑、任务组织方式和协作 / 通信机制。
目的不是给所有 MultiAgent 系统一刀切地贴标签,而是帮读者先认长相。真要设计系统,还是得回到前面那三个问题分别判断。
| 形态 | 最像什么 | 适合什么 | 主要代价 |
|---|---|---|---|
| 监督者 / Orchestrator-Worker | 项目经理带专项同事 | Research、宽搜型复杂任务 | supervisor 瓶颈、单点失效 |
| 流水线 / Graph Workflow | 审批流、接力链 | 企业流程、长任务 | 前序错误级联、灵活性弱 |
| 评审 / 辩论 / Committee | 评审会 | 高不确定性推理、红队、方案评审 | 成本高、容易多数谬误 |
| 共享状态 / Blackboard | 围着同一块白板工作 | 可回放、可恢复、可审计系统 | 状态设计和并发复杂 |
| 事件驱动 / Async | 消息队列、事件总线 | 多系统集成、异步 runtime | 调试、重试、幂等困难 |
| 对等 / 去中心化 | 多个独立组织协作 | 跨组织、强隐私边界场景 | 治理、收敛、信任最难 |
这张表背后不是我自己拍脑袋分的,而是综合了 IJCAI 2024 survey、Anthropic 的 industrial case、AutoGen、LangChain/LangGraph 文档、Multi-LLM Debate 和 AgentNet 这些资料。
更有意思的是,不同来源之间其实有明显分歧。
- 工业界更偏中心化,因为更好 debug,更好加护栏。
- 研究界更愿意推去中心化,因为中心化天然有单点瓶颈和隐私边界问题。
- 一部分综述会把今天很多系统都算作 MultiAgent;但 《Large Language Models Miss the Multi-agent Mark》 这类研究会提醒你:很多现在被叫作 multi-agent 的系统,本质上更像“多个 LLM 角色一起干活”,还没到传统多智能体理论里那种高度自治、彼此持续互动、还会被环境实时反馈牵着走的程度。
一个现实判断
今天工业界主流公开案例,仍然明显偏中心化监督者和工作流编排。
去中心化很重要,但至少从公开的一手生产经验来看,它还不是主流落地方向。
底层关键技术:别把 Workflow、Memory、MCP、A2A 写成一团
很多讨论一到这里就开始堆词:
- skill
- memory
- shared state
- orchestration
- event bus
- MCP
- A2A
最后读完只剩一种感觉:好像什么都重要,但又不知道它们到底是不是同一层。
如果你以前读 agent 文章时经常在这一段开始掉线,这很正常。因为从这里往后,大家最容易把“能力”“记忆”“编排”“消息流”和“跨系统协议”全写成一锅粥。
问题往往不在于资料不够,而在于这些词其实在回答完全不同的问题:
skill回答的是“这个 Agent 被封装成擅长哪类任务”workflow回答的是“任务怎么往前走”memory回答的是“系统怎么记住东西”MCP回答的是“Agent 怎么接工具和资源”,而且到 2026 年已经开始往 UI 和部分边界能力延展A2A回答的是“独立 Agent 服务怎么跨边界互通”
它们本来就不是同类东西,硬写在一层当然会乱。
前面那张表是帮读者先认长相,这一节开始才进入更严格的系统分层。
你可以把这里想成在拆一台机器:
- 先看它有没有手脚
- 再看它记不记事
- 再看谁在调度
- 再看消息怎么流
- 最后才看不同系统之间怎么接线
这么看,后面那五层会顺很多。
我更建议把 MultiAgent 的底层技术拆成五层。
| 层级 | 它真正回答什么问题 | 常见内容 |
|---|---|---|
| 执行与能力层 | 单个 Agent 到底能做什么 | reasoning、tool calling、Skills、MCP、检索、代码执行、外部 API |
| 上下文与状态��层 | Agent 靠什么维持连续性 | session、memory、shared state、artifact、summary |
| 编排与协作层 | 多个 Agent 以什么组织方式分工 | centralized / decentralized topology、supervisor、workflow、committee |
| 通信与任务层 | 工作怎么在节点之间流转 | mailbox、direct messaging、broadcast、event bus、handoff、task lifecycle |
| 跨系统互通与服务边界层 | 独立 Agent 服务跨边界怎么接起来 | A2A、认证、发现、版本兼容、service boundary |
这一节不要按名词背
真正有用的读法不是把这五层硬记下来,而是每次碰到一个词,先问它到底在回答哪类问题:
- 单个 Agent 的能力问题
- 状态怎么维持的问题
- 多 Agent 怎么分工的问题
- 工作怎么流转的问题
- 独立服务怎么跨边界互通的问题
层级一分开,很多原本看起来缠在一起的讨论会立刻清楚很多。
第 1 层:执行与能力层
这一层最容易理解,它回答的是:
单个 Agent 到底能做什么。
比如:
- 会不会推理
- 会不会调工具
- 有没有相关
Skill - 能不能通过
MCP接工具和资源 - 能不能查知识库
- 能不能跑代码
- 能不能调外部 API
如果没有这一层,后面所有“多 Agent 协作”都没意义,因为连单个节点能干什么都不成立。
所以这层更像每个 Agent 的“手脚”和“工具箱”。
Example:一个支付故障处理 Agent,怎么同时用上这一层的几种能力
第 2 层:上下文与状态层
这一层回答的是:
系统靠什么维持连续性。
这里最容易混淆三个词:
memoryshared stateartifact
但它们其实不是一回事。
memory更像记忆。 比如系统记得这个用户之前问过什么、上一次推理得出了什么中间结论。shared state更像当前局势面板。 比如现在工单状态是high-priority,退款检查已经完成,权限检查还没完成。artifact更像阶段性产物。 比如一份摘要、一张表、一段 JSON 结果、一��版中间报告。
如果把它们翻成人话:
- memory 是“记住过什么”
- state 是“现在局面是什么”
- artifact 是“已经产出了什么”
这三者一混,系统设计就会开始发虚。
Example:同一张工单里,memory、state、artifact 到底分别是什么
第 3 层:编排与协作层
这一层回答的是:
多个 Agent 怎么分工。
也就是前面刚讲过的那些组织方式:
- centralized / decentralized topology
- supervisor-worker
- workflow
- committee
这里有两个特别容易放错层的词,需要单独讲一句:
blackboard是“状态层 + 协作层”的交叉物。共享状态本身在第 2 层,围着共享状态怎么分工才属于第 3 层。async / event-driven更接近第 4 层,因为它描述的是消息和任务怎么流,不是谁带队。
这一层说的不是工具,不是协议,也不等于所有运行时机制,而是“组织结构”。
如果把 MultiAgent 比作一个团队,这一层回答的就是:
- 谁带队
- 谁做什么
- 谁和谁协作
- 出问题时谁兜底
这一层决定的是角色划分和控制拓扑,不回答独立 Agent 服务跨边界怎么接起来;那是下一层的问题。
Example:同一个问题,编排层的设计为什么会完全改变系统行为
第 4 层:通信与任务层
这一层回答的是:
工作在节点之间怎么移动。
比如:
- 一条消息直接发给某个 Agent
- 写进
shared task list或 task store - 广播给一组订阅者
- 发到 event bus,等订阅者异步接手
- handoff 给更合适的 Agent
- 建一个 task,再持续更新它的状态
这一层更像系统里的“任务流转机制”。
前面讲的 async messaging,基本就落在这一层。它和 workflow 紧挨着,但不是一回事。
为什么很多人会把它和 workflow 混掉?因为它们确实紧挨着。但区别很重要:
workflow更像流程图communication / task layer更像流程图里的线、消息和任务状态
一个系统可以有 workflow,但用 very simple direct message。 一个系统也可以没有固定 workflow,却靠 event bus 和 task lifecycle 协作。
Example:通信与任务层关心的是‘活怎么流’,不是‘谁负责什么’
第 5 层:跨系统互通与服务边界层
这一层回答的是:
独立 Agent 服务跨系统、跨团队、跨框架怎么接起来。
A2A 在这一层更关键,因为它主要解决的是:
- 一个 Agent 服务怎么把任务交给另一个 Agent 服务
- 怎么持续跟踪任务状态
- 怎么交换结果和中间产物
这一层真正关心的是这些问题:
- 这个服务是谁
- 它暴露哪些能力
- 怎么发现它
- 怎么认证和授权
- 怎么保证版本兼容
更关键的是,不是所有 MultiAgent 都必须上这一层的标准协议。
Google 的 ADK 文档 就明确区分 local sub-agents 和 remote agents。如果你的系统主要是本地子代理、共享内存、低延迟内部协作,那跨系统互通这层根本不一定需要很重的标准化。到了真的存在独立 Agent 服务、跨团队边界、跨框架边界时,A2A 这类协议才会开始变得值钱。
Example:什么时候问题已经进入‘跨系统互通与服务边界层’
最容易误写的一句
不要把跨系统互通这一层理解成“所有多 Agent 系统都必须上标准协议”。很多系统在本地 runtime 里就能协作得很好,只有真的跨服务、跨团队、跨框架时,这一层的成本和价值才会同时变高。
设计原则:真正难的不是“多开几个 Agent”
如果把 Anthropic、Microsoft、OpenReview 的 failure taxonomy 和 Why Do Multi-Agent LLM Systems Fail? 放在一起看,比较稳的原则大概有七条。
如果只把这七条原则写成一句话一句话,它们确实很容易发虚。更有用的方式,是把它们放回几个反复出现的工程矛盾里看。
因为真正折磨人的,从来不是 demo 里那种“它能不能跑起来”,而是另一类很现实的问题:它明明跑起来了,为什么老是在奇怪的地方翻车,而且翻车后还没人说得清到底是哪一层先歪了。
做系统评审时,至少先连问四句
- 为什么不是单 Agent 或简单 workflow
- 谁拿什么上下文和工具
- 谁负责独立验收
- 长任务失败后怎么恢复
如果这四句答不出来,系统大概率还没准备好进生产。
第一组:不是“能拆就拆”,而是“拆了以后有没有净收益”
第一条原则其实最重要:
先证明单 Agent 或简单 workflow 不够,再上 MultiAgent。
这句话听起来保守,但它其实是在帮系统省掉大量伪复杂度。
很多团队一上来就想加更多 Agent�,本质上是把“任务定义不清、工具接入混乱、验证链不完整”这些更底层的问题,伪装成“需要更多角色”。结果不是系统更强,而是混乱被复制了更多份。
这组原则真正对应的是两个判断:
- 当前任务到底有没有明显的可拆分收益?
- 拆完之后,职责是不是更清楚了,而不是更模糊了?
所以这组里有两条常常要一起看:
- 先证明单 Agent 或简单 workflow 不够
- 职责分离比堆数量更重要
真正值钱的拆法,通常不是“从 1 个 Agent 变成 8 个 Agent”,而是把原来混在一起的几种责任拆开,比如:
- 规划和执行分开
- 执行和验收分开
- 对外沟通和内部分析分开
如果拆完之后,每个 Agent 还是在做一团混合职责,那它只是从“一个大黑盒”变成了“三个小黑盒”。
第二组:不是“上下文越多越好”,而是“上下文和工具都要做减法”
很多 MultiAgent 系统看上去像是因为模型不够强才翻车,实际上更常见的原因是:
- 每个 Agent 拿到的上下文太杂
- 工具挂得太多
- 同类能力重叠太严重
所以第二组原则,核心其实是“减法”:
- 上下文要最小高信号,不要做全量广播
- 工具和 Agent 都不是越多越好,过多会互相干扰
这两条放在一起看,意思就很清楚了:
一个 Agent 不应该因为“也许有用”就被塞进全部历史、全部规则、全部工具。真正稳的系统,通常会把上下文裁成任务需要的最小集合,把工具裁成角色需要的最小集合。
否则就会出现两种非常典型的故障:
- 上下文噪声过高,模型抓不住真正权威的信息
- 工具过载,模型在一堆相似能力里来回试错,最后反而更慢、更乱、更贵
这类问题在单 Agent 里已经常见,到了 MultiAgent 里只会被放大。
第三组:不是“能跑完就行”,而是“谁来证明它真的做对了”
很多多 Agent 系统的危险,不在执行,而在验收。
如果一个系统里:
- 负责做事的 Agent 自己判断自己有没有做好
- 负责写结果的 Agent 自己决定结果够不够可信
- 负责调用工具的 Agent 自己解释工具输出有没有问题
那它很容易一路自洽到底。
所以第三组原则是:
- 验收权最好和执行权分开
- 可观测性必须内建,而且不能只看日志
这两条之所以经常要放在一起,是因为它们本质上都在回答一个问题:
系统拿什么来反驳自己。
执行权和验收权分开,解决的是“不要让同一个脑回路从头判到尾”。
可观测性内建,解决的是“即使它做错了,人能不能看见它到底错在哪”。
Reflection 很有用,但它不等于独立验收
很多团队会把
Reflection当成万能纠错机制,比如让 agent 在完成后再自我复盘一轮、再挑一轮自己的漏洞。这当然有价值,但它解决的更像“同一个执行链能不能自我修正一点”,不是“系统有没有独立的证明机制”。
如果执行者、反思者、总结者本质上还是同一条脑回路,那它仍然可能一路自洽到底,只是自洽得更认真了一点。 evaluation 真正回答的是“怎么证明它做对了”
到了多 Agent 系统里,
evaluation不该再只是“最后看起来像不像对”。更稳的
evaluation往往至少要落到这些东西里:
- end-state checks:最终状态到底有没有达到目标
- constraint checks:有没有触碰明确禁止的边界
- regression checks:有没有把原本正常的链路带坏
- judge / reviewer:有没有独立于执行链的审查视角
- trace-based review:出了问题时,能不能顺着轨迹定位是哪一层先歪了
换句话说,
Reflection更像过程内自检,evaluation才是系统级验收。
而且今天讲 observability,已经不能再只理解成:
- 有没有日志
- 有没有 trace id
- 有没有耗时指标
更关键的其实是:
- 有没有看得懂的任务轨迹
- 有没有中间状态
- 有没有失败分类
- 有没有办法知道是 spec 错了、路由错了、工具错了,还是验收错了
否则系统一复杂,最后就只剩一句“它又跑偏了”,但没人知道到底哪里偏了。
第四组:不是“能 demo 出来”,而是“能不能长期跑而不失控”
到了生产环境,很多问题就不再是“这次能不能跑通”,而是:
- 跑到一半挂了怎么办
- 升级部署时断了怎么办
- 长任务能不能从中间恢复
- 权限和边界出了问题谁负责
所以最后一组原则是:
- 长任务系统必须支持持久化、检查点和恢复
这条看起来像运行时细节,但它其实很核心。因为一旦进入多 Agent 长任务,错误不再只是“一次答错”,而会变成:
- 状态错着往后传
- 子任务错着继续扩散
- 中途失败后全部从头再来
- 系统越来越贵,但没有越来越稳
这也是为什么很多公开的一手经验最后都会落到同一个方向:MultiAgent 不是玩一次性的编排炫技,而是要把状态、恢复、治理和失败隔离都做成长期机制。
这些原则到底在防什么
如果把这些原则压回 failure taxonomy,它们大概在防四类大坑:
| 原则组 | 主要在防什么 |
|---|---|
| 先证明单 Agent 不够;职责分离优先于堆数量 | 规格层失败、组织层失败 |
| 上下文做减法;工具和 Agent 不要过载 | 协调层失败、工具生态失败 |
| 验收权分离;可观测性内建 | 验证层失败、可观测性失败 |
| 持久化、检查点、恢复 | 运行时失败、安全与治理失败 |
| 失败类型 | 最常见表现 |
|---|---|
| 规格层失败 | 角色定义模糊、目标不清、完成条件缺失 |
| 组织层失败 | 任务拆分差、边界不清、delegate 错位 |
| 协调层失败 | 多个 Agent 冲突、状态不同步、异步级联错误 |
| 验证层失败 | 没有独立验收,只看过程,不看结果 |
| 运行时失败 | 长任务错误累积、恢复困难、部署打断运行中任务 |
| 可观测性失败 | trace 太长找不到问题,只能靠猜 |
| 工具生态失败 | 工具过多、能力重叠、schema 和 description 不清 |
| 安全与治理失败 | 权限失控、隐私泄露、跨 Agent collusion、缺少问责 |
我很喜欢这类 failure taxonomy 的原因就在这儿:
它逼着我们承认一件事:MultiAgent 的难点从来不只是“让它们协作起来”,而是“让它们在现实系统里长期不失控”。
到 2026 年 4 月,再看 MultiAgent:真正收束出的几件事
把最近 3 到 6 个月的一手资料放在一起看,至少有五个判断已经比较稳定。
如果前面信息密度有点高,这一节可以直接当复盘看。这里不再重新讲术语,只讲到 2026 年 4 月,哪些判断已经比较能站住。
第一,它先收束成“有组织的执行系统”,不是“更多聊天角色”
最近半年最有代表性的公开材料,其实已经把方向讲得很清楚了。
Anthropic 在 2026 年 2 月 5 日发布的《Building a C compiler with a team of parallel Claudes》 讲得很具体:真正难的不是多开几个 session,而是任务怎么锁、结果怎么合、review 怎么插进去、harness 和测试怎么兜底。另一边,模型侧也已经开始把更大规模的动态拆分和并行调度往前推,像 K2.5 技术报告 里展示的,就是让 orchestrator 去动态拆任务、回收结果,而不是先把流程全写死。
这几条线合在一起,其实已经很说明问题了:
MultiAgent 到今天先成熟的,不是“大家一起聊”,而是“有人负责任务组织,有人负责并行执行,有机制负责把结果收回来”。
第二,它先收束成“长任务 runtime”,不是“一次性 prompt 技巧”
最近 3 到 6 个月里,最明显的变化之一,就是大家已经不再把 agent 当成一次性会话了。
Anthropic 在 2025 年 11 月 26 日写 long-running harnesses,核心就是怎么跨上下文窗口持续推进任务;OpenAI 现在的文档里也把 background mode、conversation state 这些能力直接做成平台原语。
这背后其实说明了同一件事:
真正可用的 MultiAgent,已经越来越像一个长任务 runtime。
它必须解决的,不再只是“这次能不能答出来”,而是:
- 任务跑很久怎么办
- 中途断了怎么办
- 上下文滚太长怎么办
- 哪些信息该进
memory,哪些该进state,哪些该落成artifact
也就是说,前面文章里讲的那套分层,到这里已经不是写作框架,而是产品现实了。
第三,它先收束成“可验收、可追踪、可恢复”,不是“能跑完就算赢”
如果只看最近一两个月的官方文档,这个信号已经非常强。
OpenAI 现在把 Agent evals、trace grading、Agent Builder 放在一条线上讲;Microsoft 则在 2026 年 3 月 28 日更新的 Foundry tracing 文档 里,直接把 multi-agent observability 往 OpenTelemetry 语义约定上推。
这说明什么?
说明行业已经不再把“agent 跑起来了”当成终点,而是开始把下面这些问题当成一等问题:
- 最终结果到底做没做对
- 哪一步先歪了
- 是路由错了,还是工具错了,还是验收错了
- 出问题之后能不能从中间恢复,而不是整条链重跑
所以今天真正拉开差距的,已经不是“谁的 prompt 更玄”,而是:
谁的系统能被看见,能被验收,能被恢复。
第四,它先收束成“边界协议化”,但不是“一个协议统一世界”
到 2026 年,这一层真正发生的变化,是 agent 的边界开始被正式协议化。
Anthropic 在 2025 年 12 月 9 日把 MCP 捐给 Agentic AI Foundation,已经说明它不再只是某一家公司的私有约定;MCP 在 2026 年 1 月 26 日把 MCP Apps 变成官方扩展,说明它开始覆盖 UI 和交互能力;2026 年 3 月 9 日的 roadmap 又把 agent communication、enterprise readiness 这些问题摆上主线。
如果把这些变化压成一句话,就是:
过去大家是在写胶水代码接边界,现在大家开始认真把边界本身做成协议。
但这不等于会出现一个“一统天下”的协议。到今天为止,更像是:
- 能力接入是一层边界
- UI / 人机交互是一层边界
- 远程 agent / 服务互通又是另一层边界
所以真正收束出的,不是“大一统”,而是“分层协议化”。
第五,它没有收束成“多 Agent 默认更强”
这一点反而是最近的官方文档里越来越诚实的地方。
OpenAI 最新的 evaluation best practices 已经直接写了:是否使用 multi-agent architecture,应该由 evals 驱动。也就是说,多 Agent 不是默认答案,而是结构选择。
这和前面讲过的案例也一致。并行开发、review、任务拆分边界清楚的工作,很适合团队式多 Agent;复杂长任务、宽搜索、动态拆解收益很高的工作,也确实能从更大规模的并行协同里获益。
但没有任何一条严肃的一手材料在认真说:“从现在开始,所有高级 agent 都必须 multi-agent。”
所以到 2026 年 4 月,更稳的总结其实不是“MultiAgent 已经证明自己一定是未来”,而是:
MultiAgent 已经证明自己在某些任务形态下非常值钱,但它依然是一种结构优势,不是默认信仰。
这一节最后只记一句
到 2026 年 4 月,MultiAgent 真正收束出的,不是一个更响的新名词,而是一套更像工程系统的共识:有组织、有状态、可验收、可恢复、边界清楚,而且只在真正值得拆的时候才去拆。
延伸阅读
如果想继续往下挖,我建议按三组来读。
官方工程与协议
- Anthropic: Building Effective AI Agents
- Anthropic: How we built our multi-agent research system
- Anthropic: Effective context engineering for AI agents
- OpenAI: New tools for building agents
- OpenAI: Introducing deep research
- Model Context Protocol 官方文档
- MCP Specification Overview
- Google Developers Blog: A2A
- A2A Specification
综述与失败分析
- IJCAI 2024: Large Language Model Based Multi-agents: A Survey of Progress and Challenges
- OpenReview: Large Language Model based Multi-Agents
- OpenReview: Multi-Agent Collaboration Mechanisms: A Survey of LLMs
- OpenReview: Why Do Multiagent Systems Fail?
- OpenReview: Why Do Multi-Agent LLM Systems Fail?
- OpenReview: Multi-LLM Debate
- OpenReview: AgentNet
- OpenReview: Large Language Models Miss the Multi-agent Mark
Agent 工程全景图
| Agent 工程 | 对标的软件/计算机概念 | 一句话本质 |
|---|---|---|
| Prompt engineering | 语句 / 表达式 | 单条指令怎么写,一行 print |
| Loop engineering | 控制流(for/while/递归) | 把单次调用变成迭代、重试、收敛 |
| Harness engineering | 运行时 / 解释器 / VM | agent 的 JVM,执行壳与 I/O 管道 |
| Context engineering | 内存管理 / 手动 GC | 上下文窗口是 RAM,手动 evict �和 compact |
| Memory engineering | 持久化 / 数据库 | 跨 session 落盘,INSERT INTO |
| Eval / Verifier engineering | 类型系统 / 断言 / 单元测试 | 校验 agent 的"返回值"对不对 |
| Orchestration engineering | 并发 / 多线程 / actor 模型 | 多 agent 调度、死锁、竞态 |
| Protocol engineering | FFI / ABI / 接口规范 | agent 间和工具间的调用约定(MCP) |
| Policy / Guardrail engineering | 权限模型 / 异常处理 | sudo + try/catch,哪些动作要人点头 |
| Tool engineering | 标准库 / API 设计 | 给 agent 造好用的工具和函数签名 |
| Retrieval engineering | 索引 / 查询优化 | RAG,怎么把对的资料喂进去 |
| Skill / Module engineering | 库 / 包 / 模块化 | 可复用的能力封装 |
| Router engineering | 调度器 / 负载均衡 | 把任务分给哪个模型/agent/路径 |
| State engineering | 状态机 / checkpoint | 显式管理状态转移与回滚 |
| Sandbox engineering | 虚拟化 / 容器 / 隔离 | 限制 agent 能碰什么,别 rm -rf / |
| Observability engineering | 日志 / trace / profiling | 看清每一步在干嘛、卡在哪 |
| Cost engineering | 性能剖析 + 经济学 | 每次求值都烧钱,复杂度换算成美元 |
| Caching engineering | 缓存(prompt / KV cache) | 别重复烧 token,命中率就是省钱 |
| Security engineering | 安全 / 注入防御 | prompt injection 是新版 SQL 注入 |
| Alignment / Spec engineering | 形式化规约 / 契约式设计 | 把"想要什么"精确钉死,防止跑偏 |
| Meta / Compiler engineering | 编译器 / 代码生成 | 把人�类意图自动降级成上面所有层 |