🧮Tokenizer
👾Transformer
手撕
Self Attention
MHA
Decoder



🎛️位置编码

绝对位置编码 VS 相对位置编码

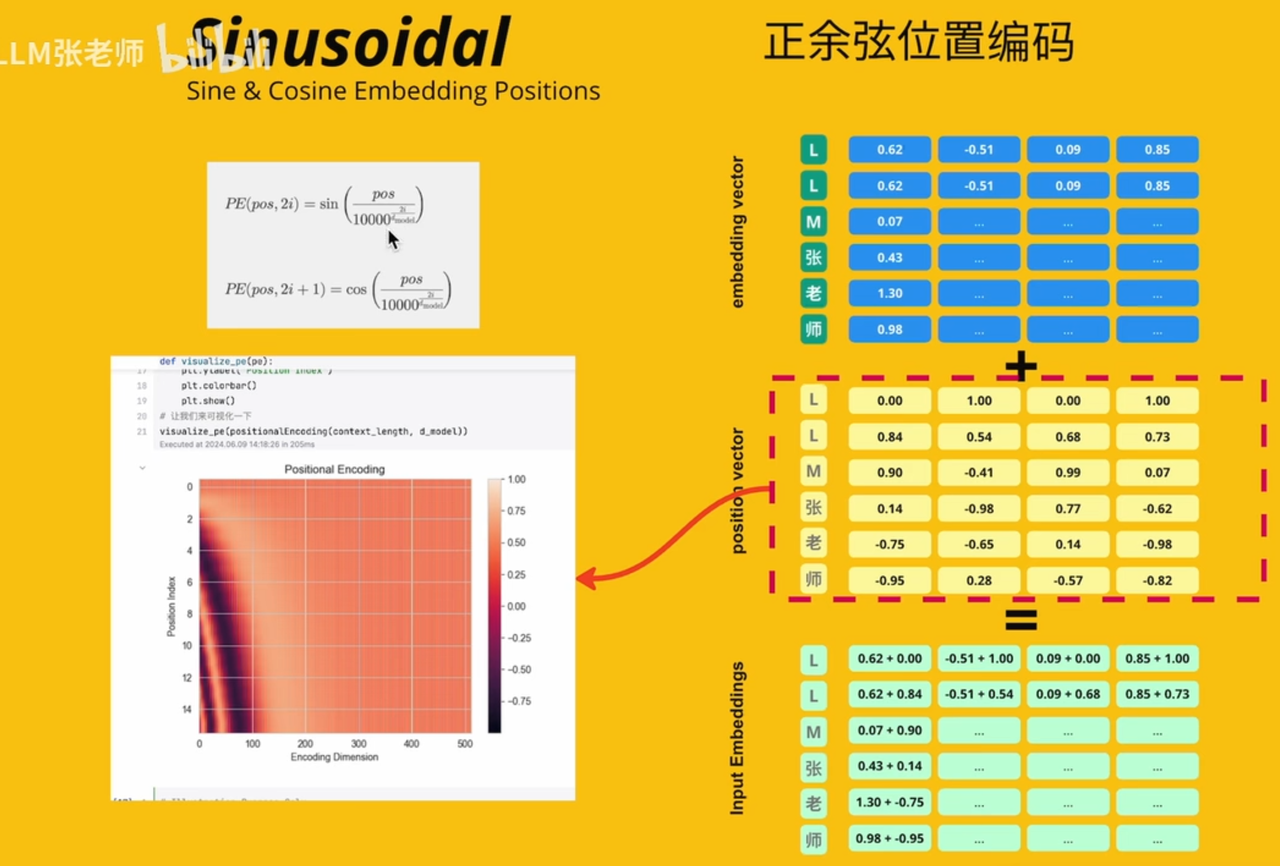
Sinusoidal(绝对)
RoPE(即相对又绝对 但是相对)
为什么需要RoPE?正余弦不够吗?







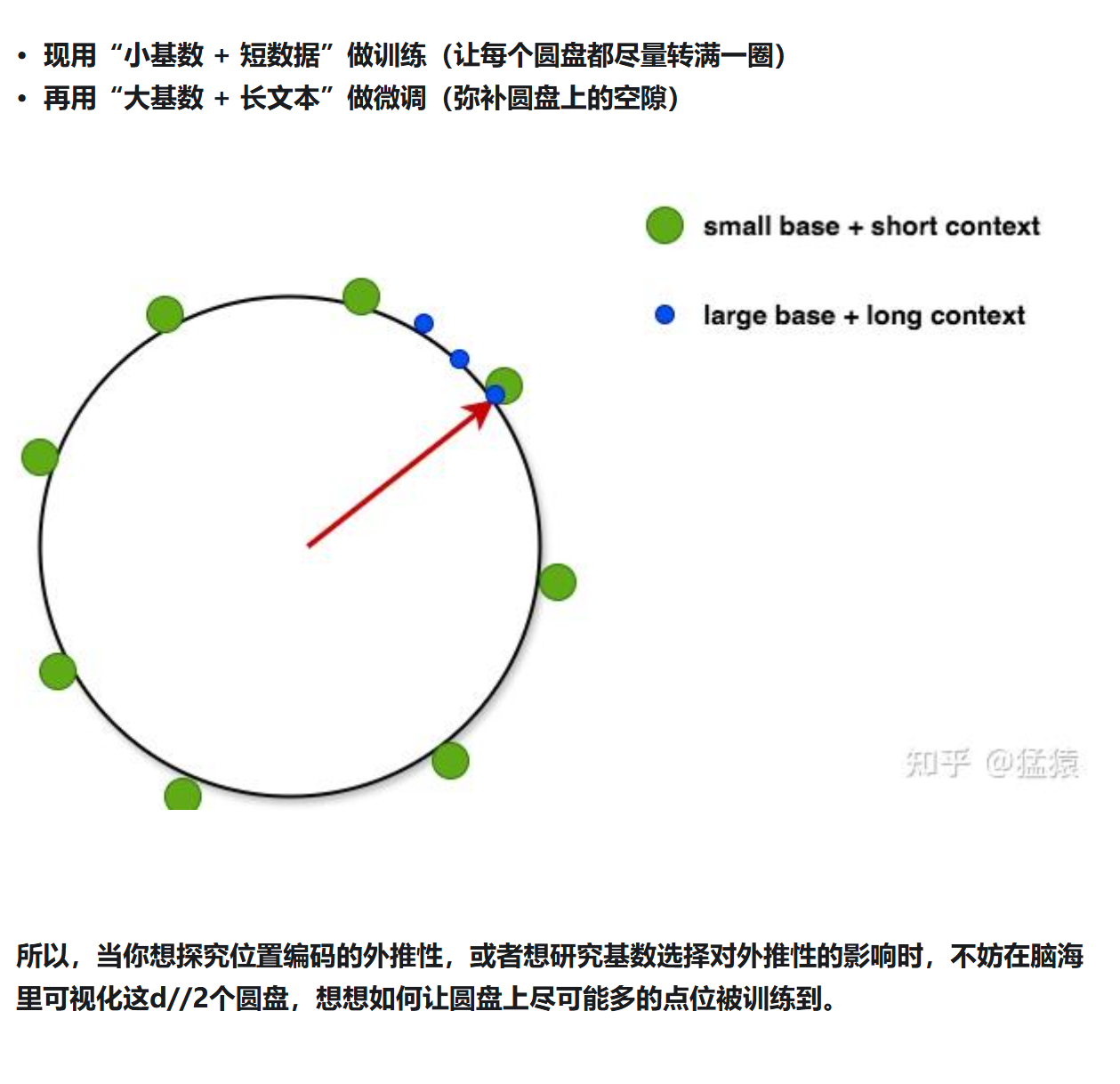


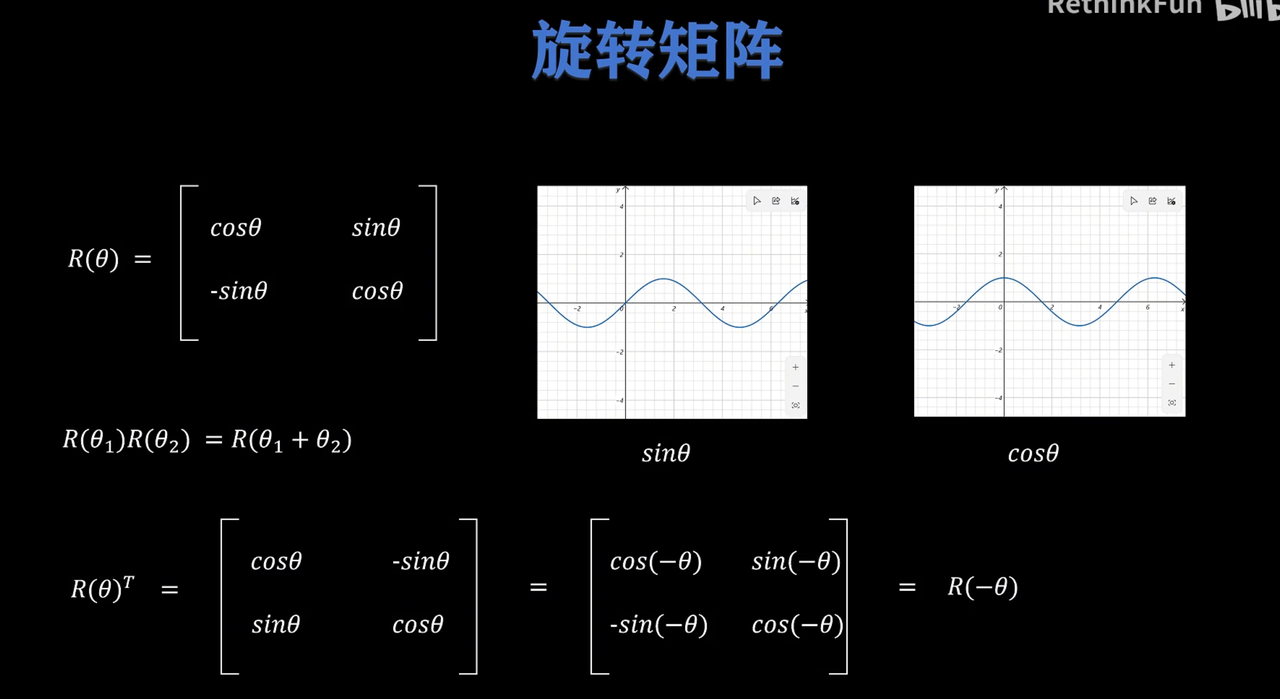



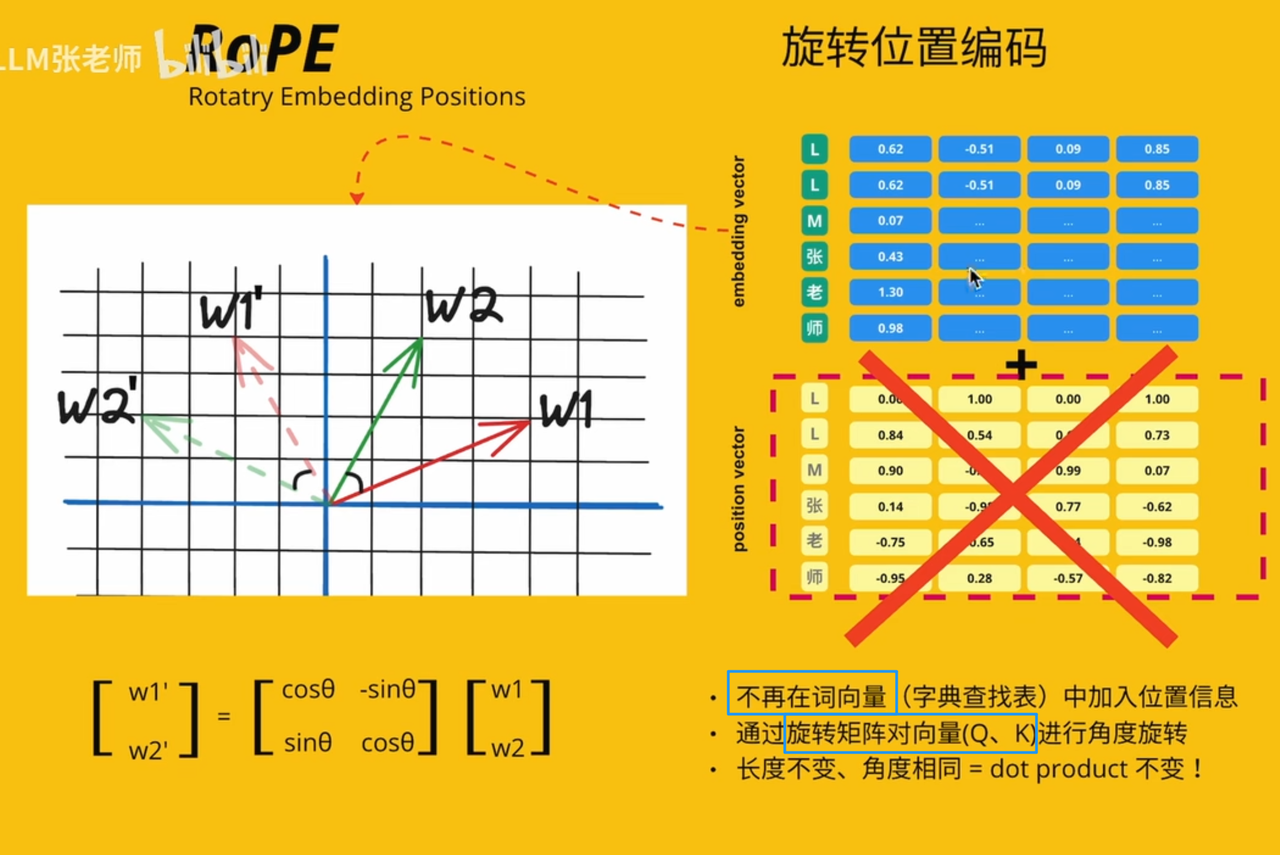
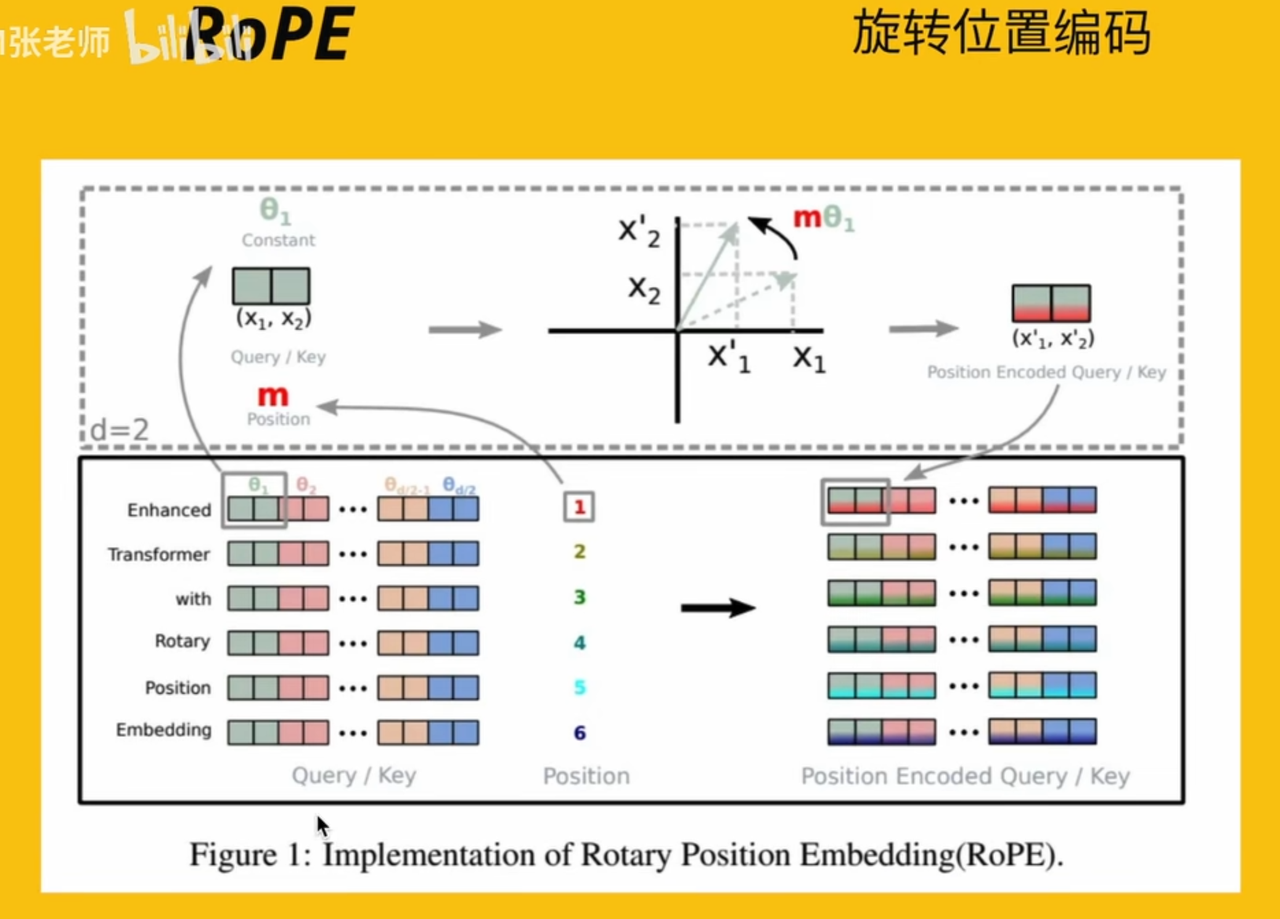

二维
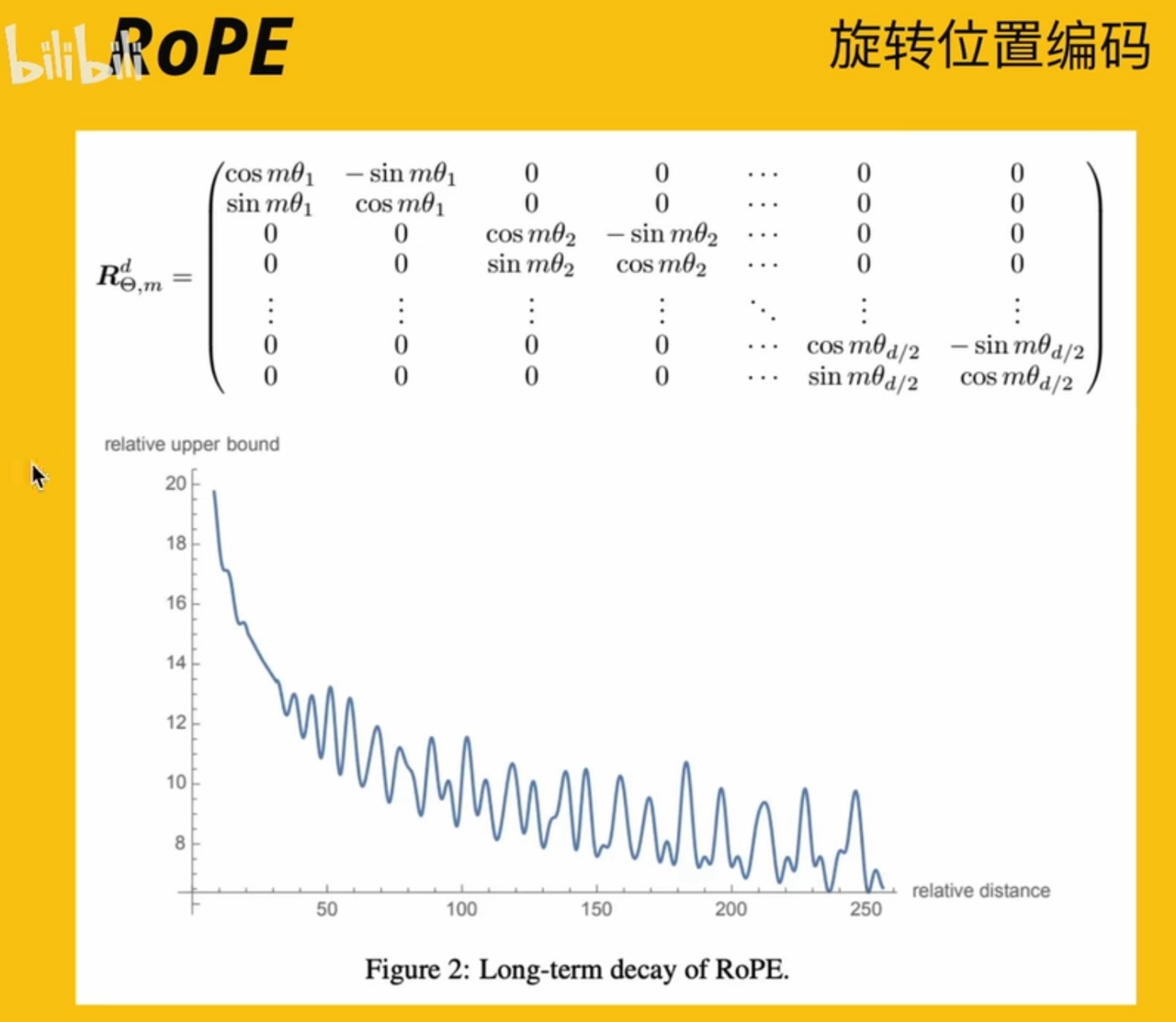
多维
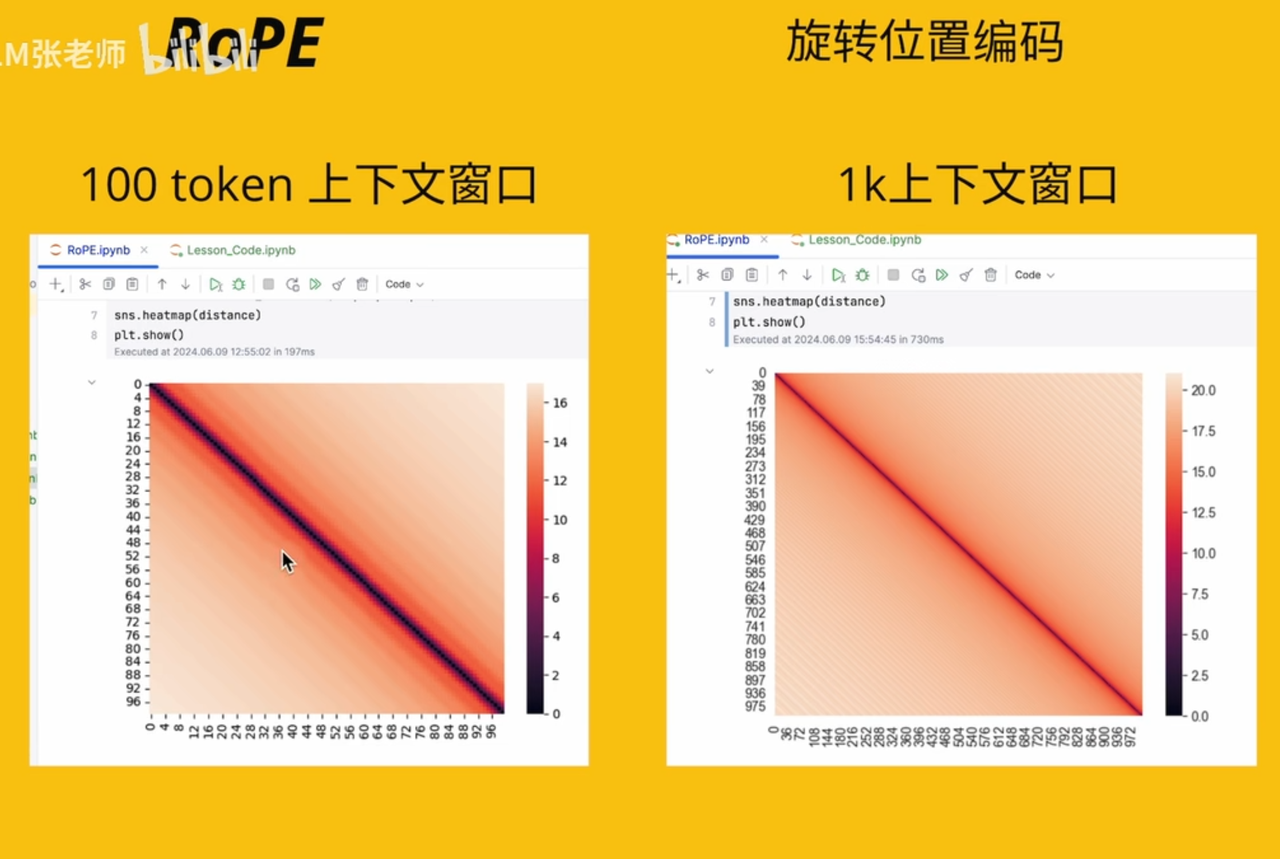
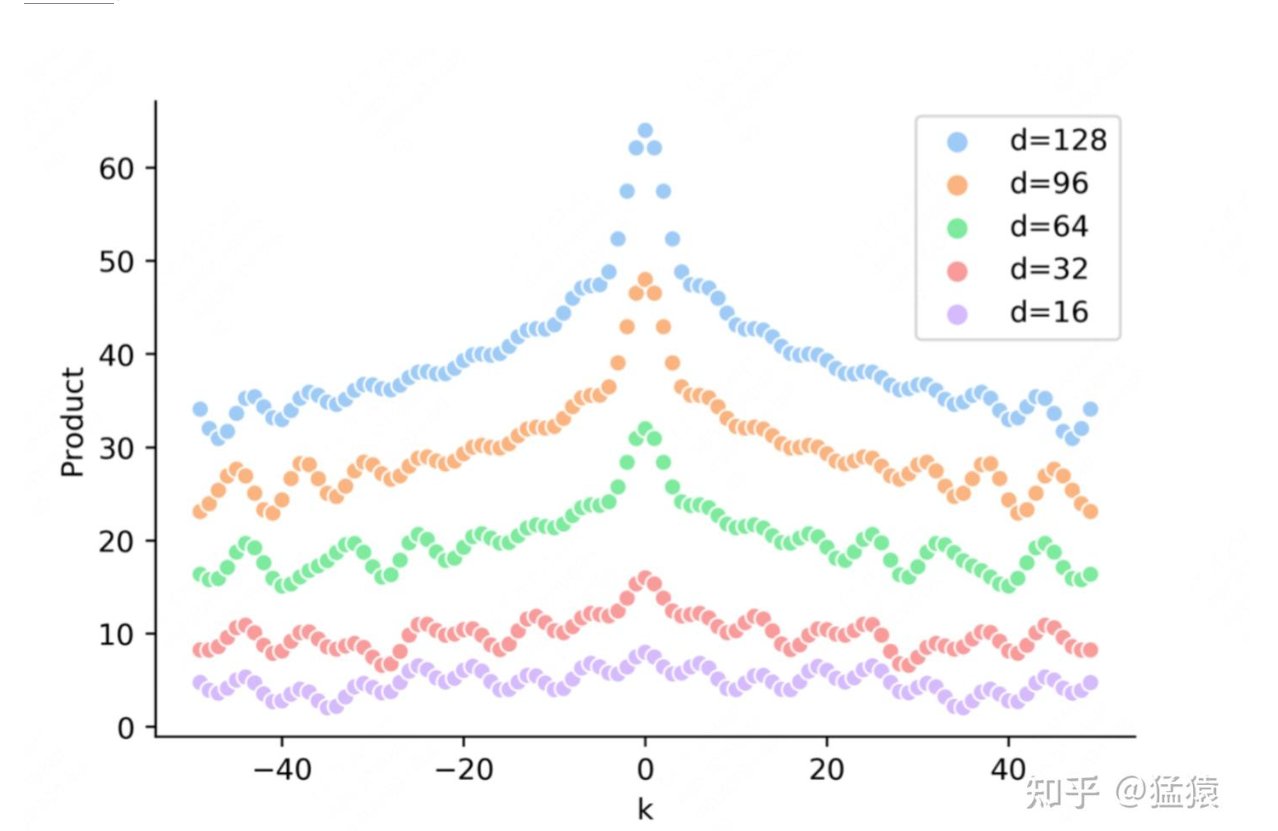
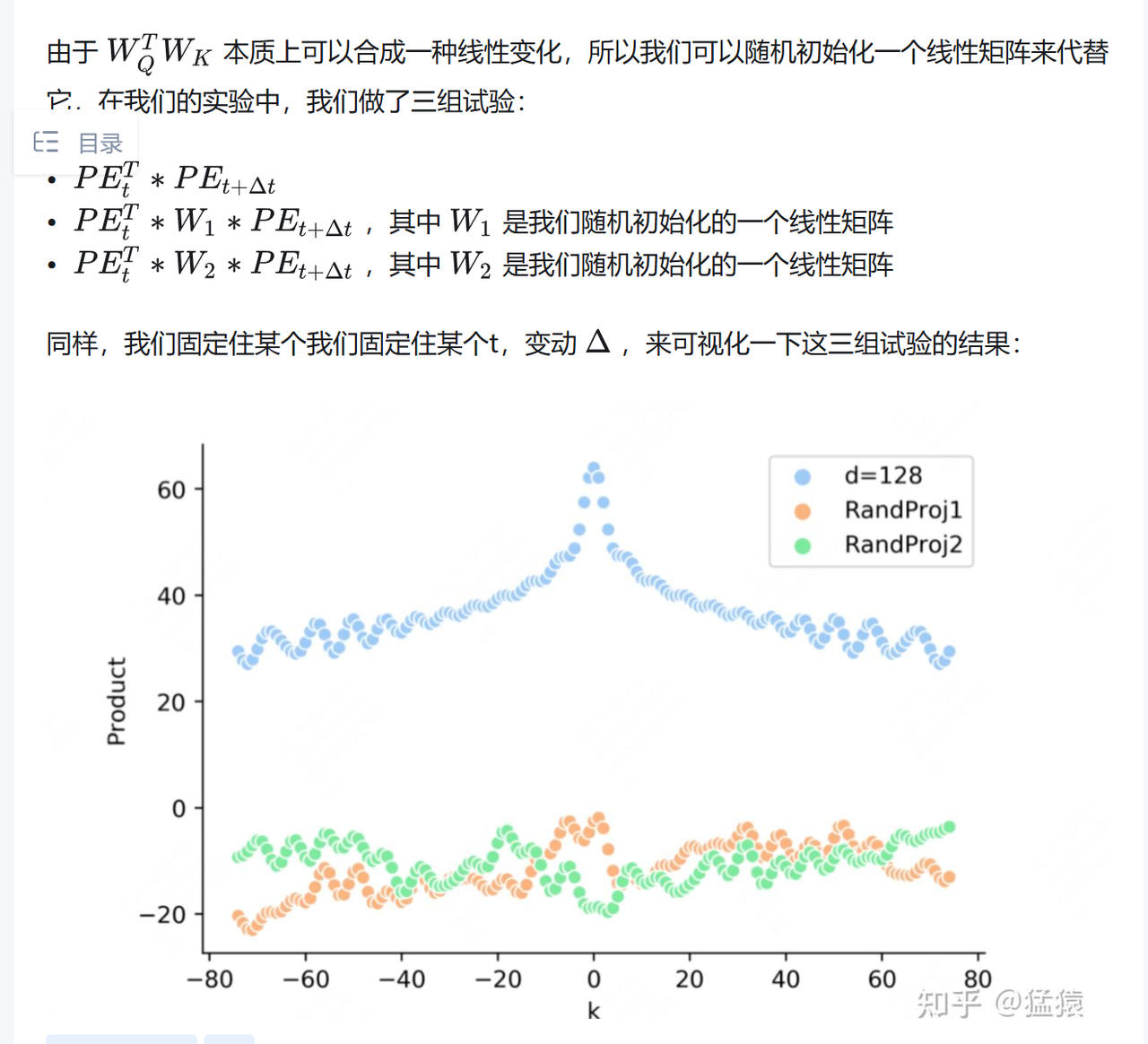
离得越远,attn越低,且呈波纹

RoPE特点


YaRN(调整版RoPE 相对)


PI

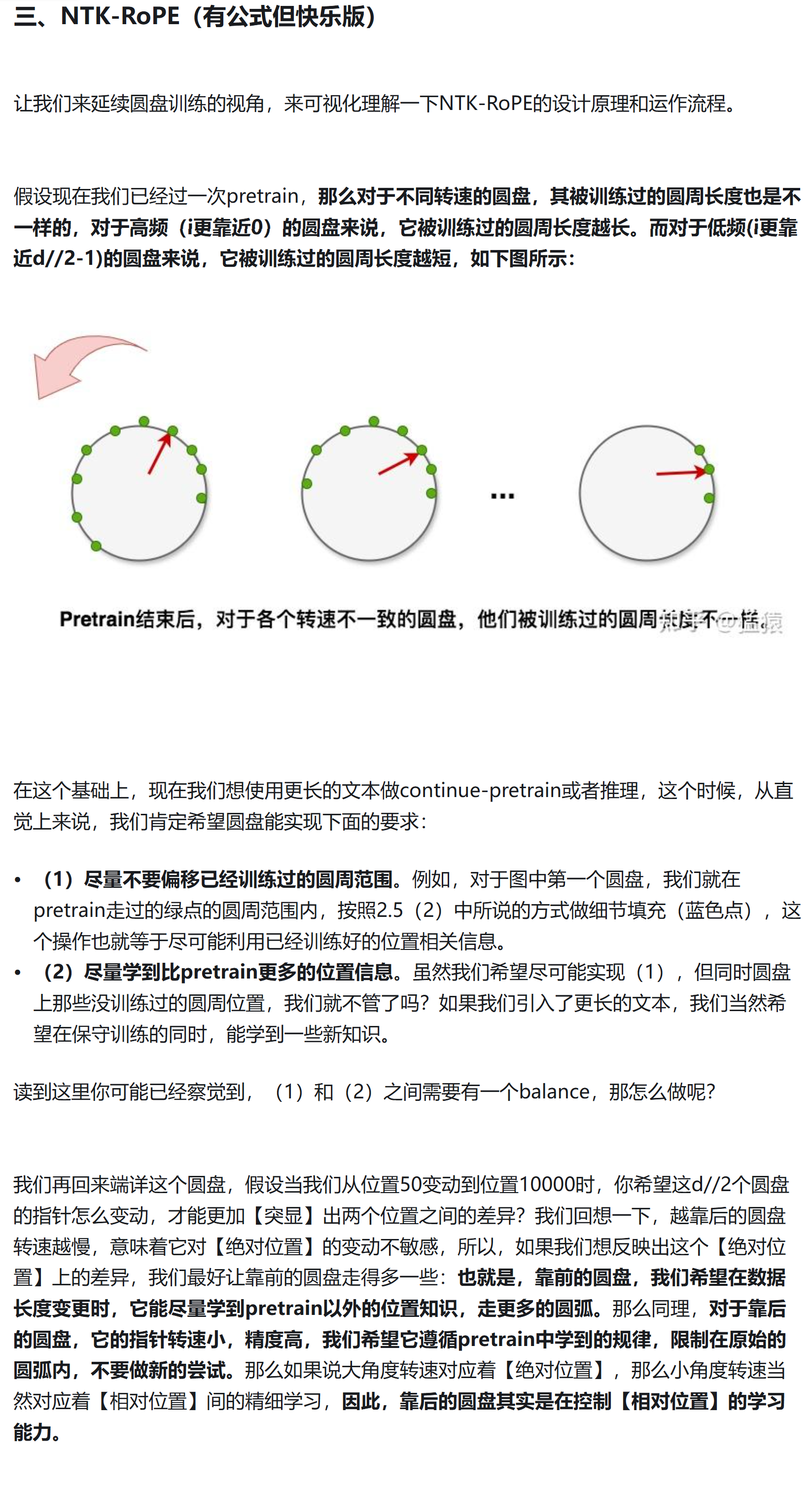
NTK-Aware

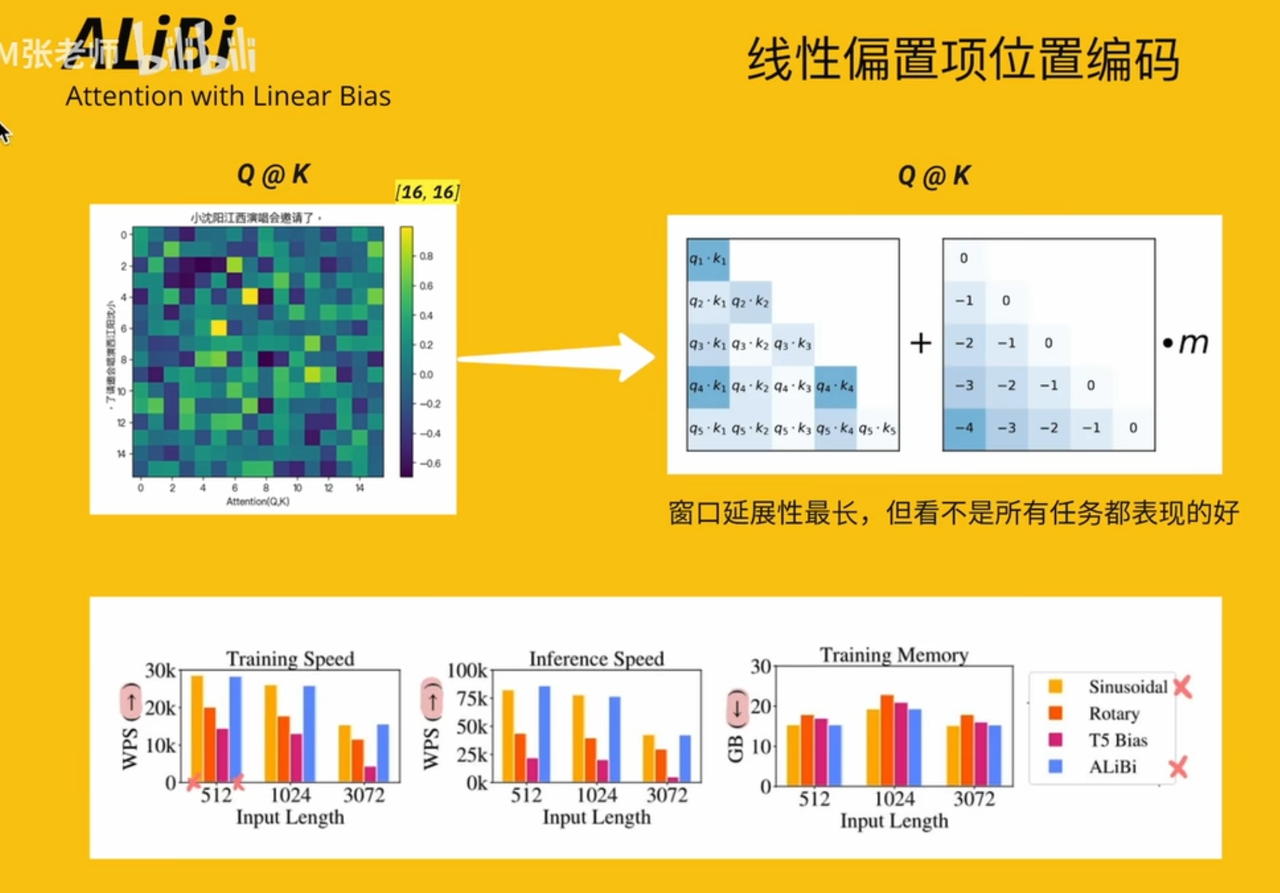
ALiBi(相对)
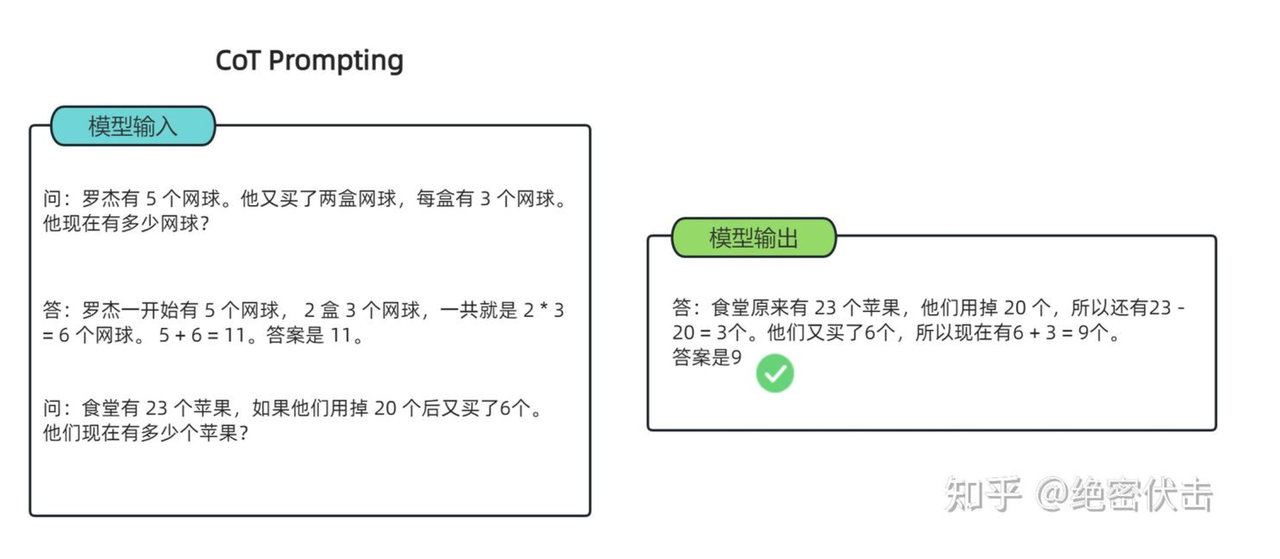
⛓思维链(CoT)
Q:为��什么需要思维链?
A:

e.g.
多数投票提高CoT性能——自洽性(Self-consistency)

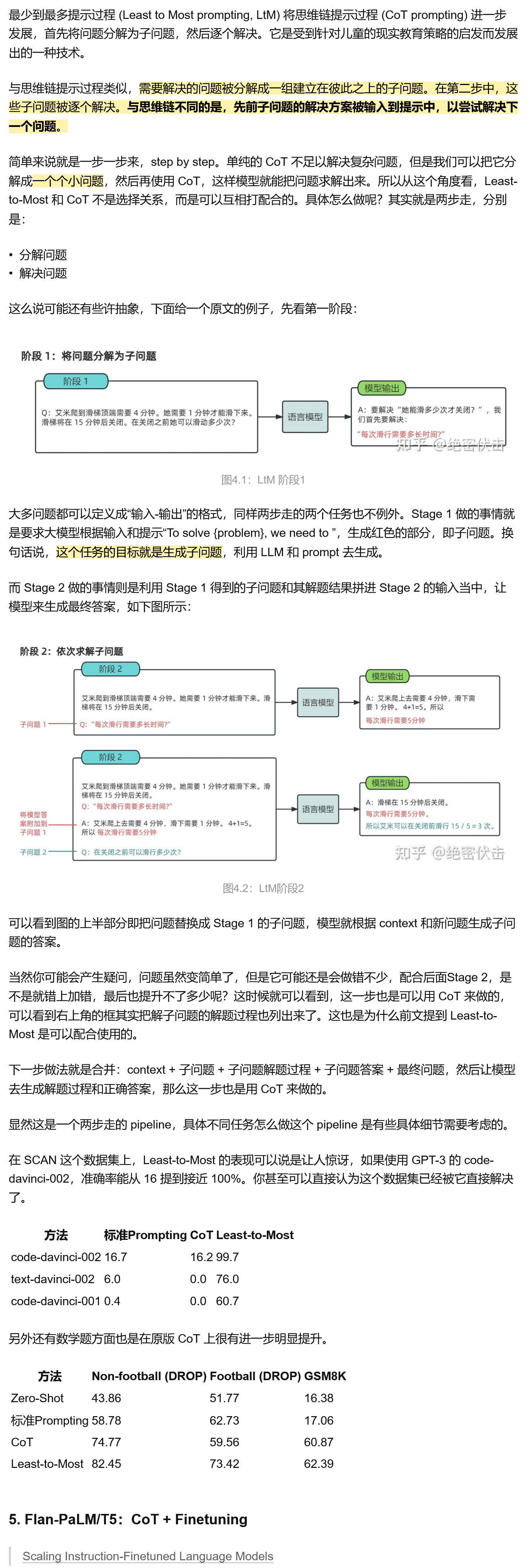
LtM (Least to Most prompting)提示
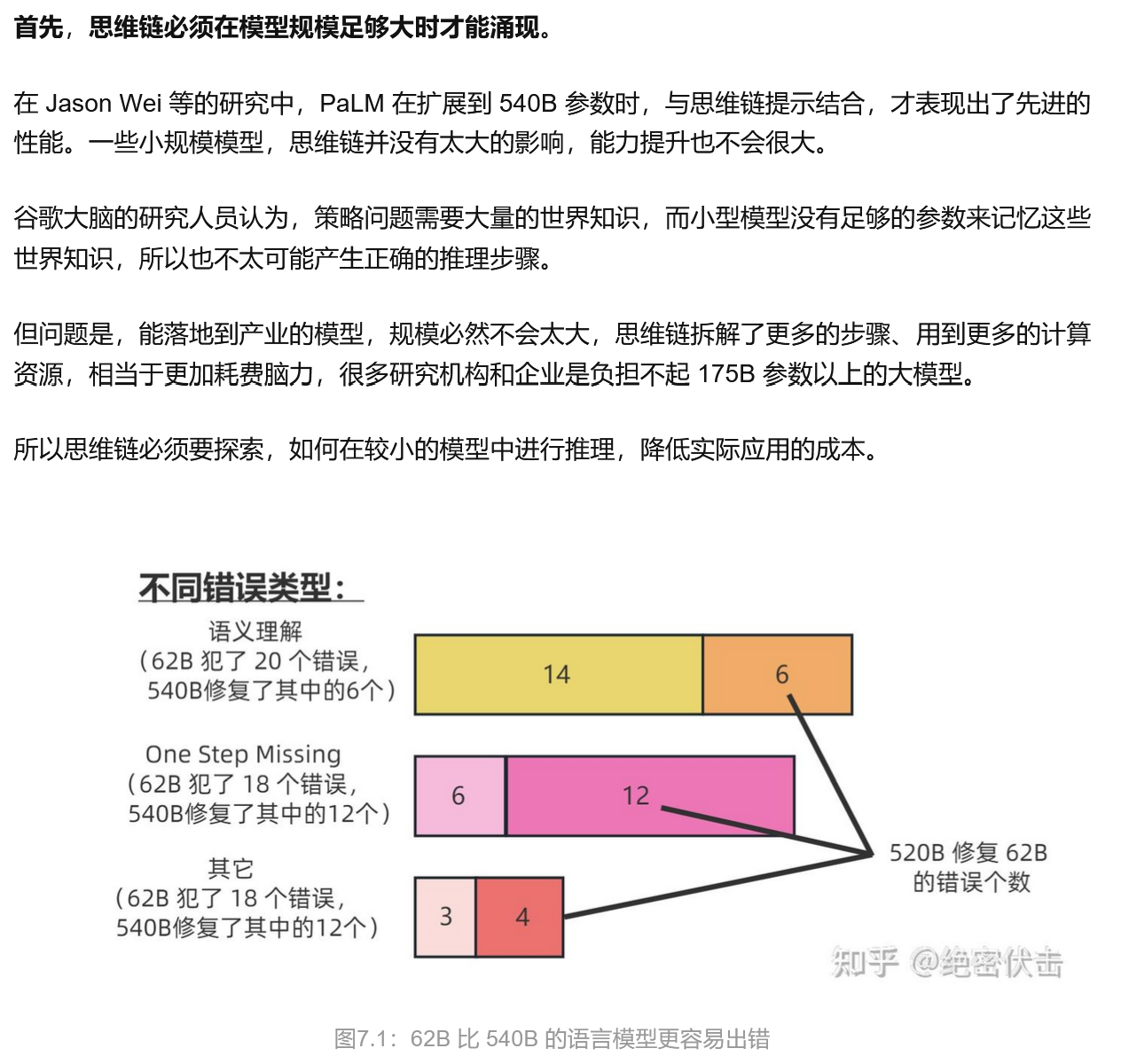
缺陷

Reference:大模型思维链(Chain-of-Thought)技术原理
💭知识蒸馏
🪄模型量化


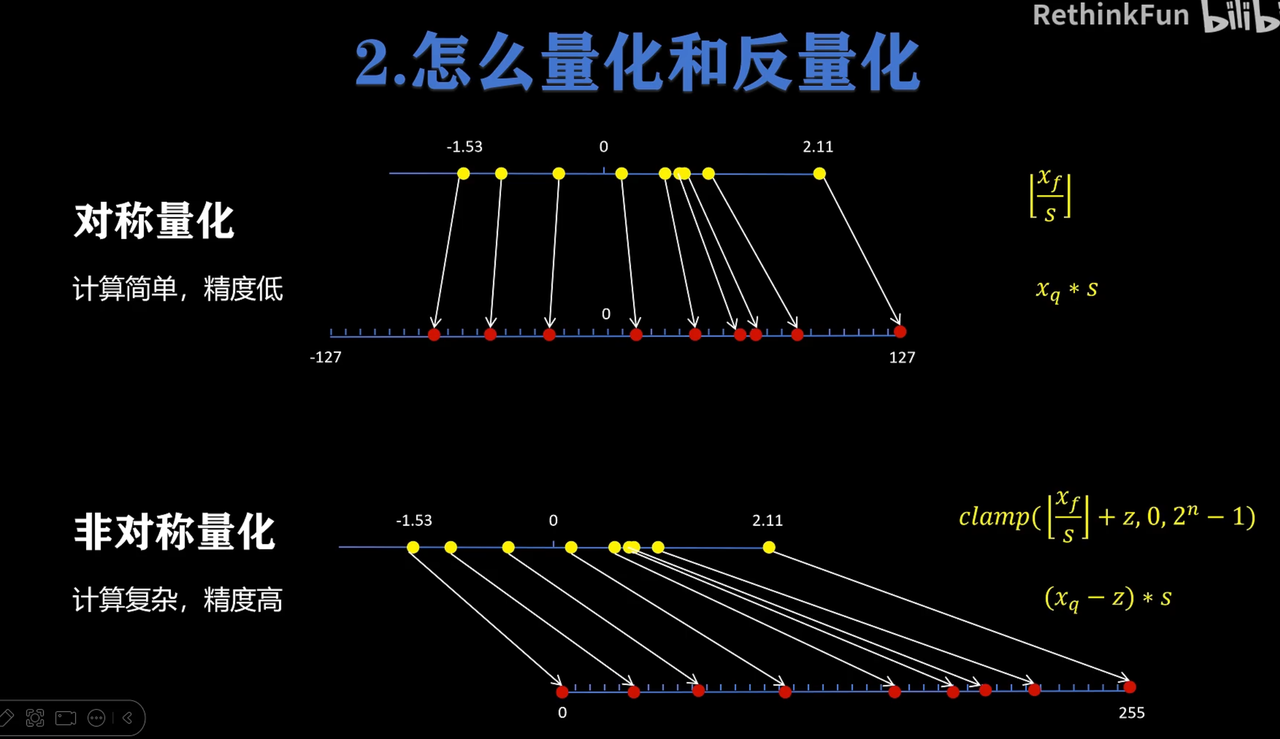
对称量化(但有区间浪费)
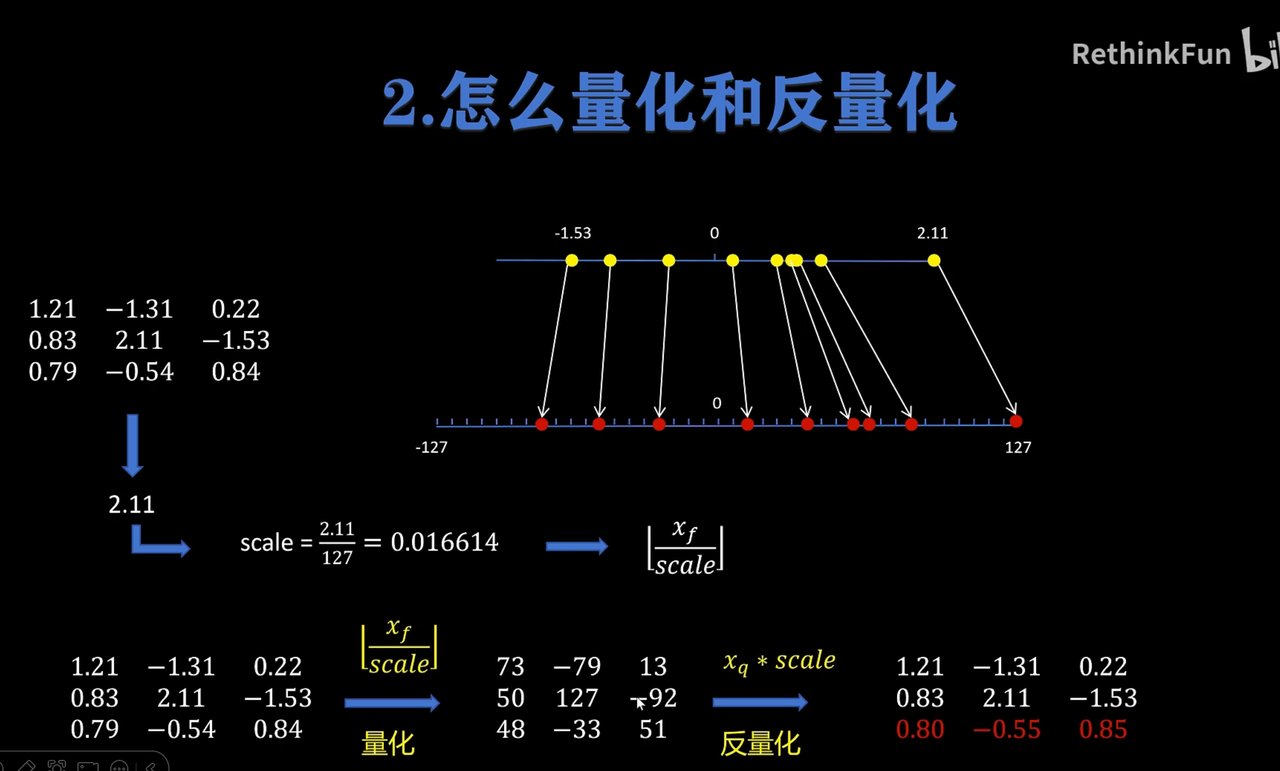
非对称量化(无符号数)
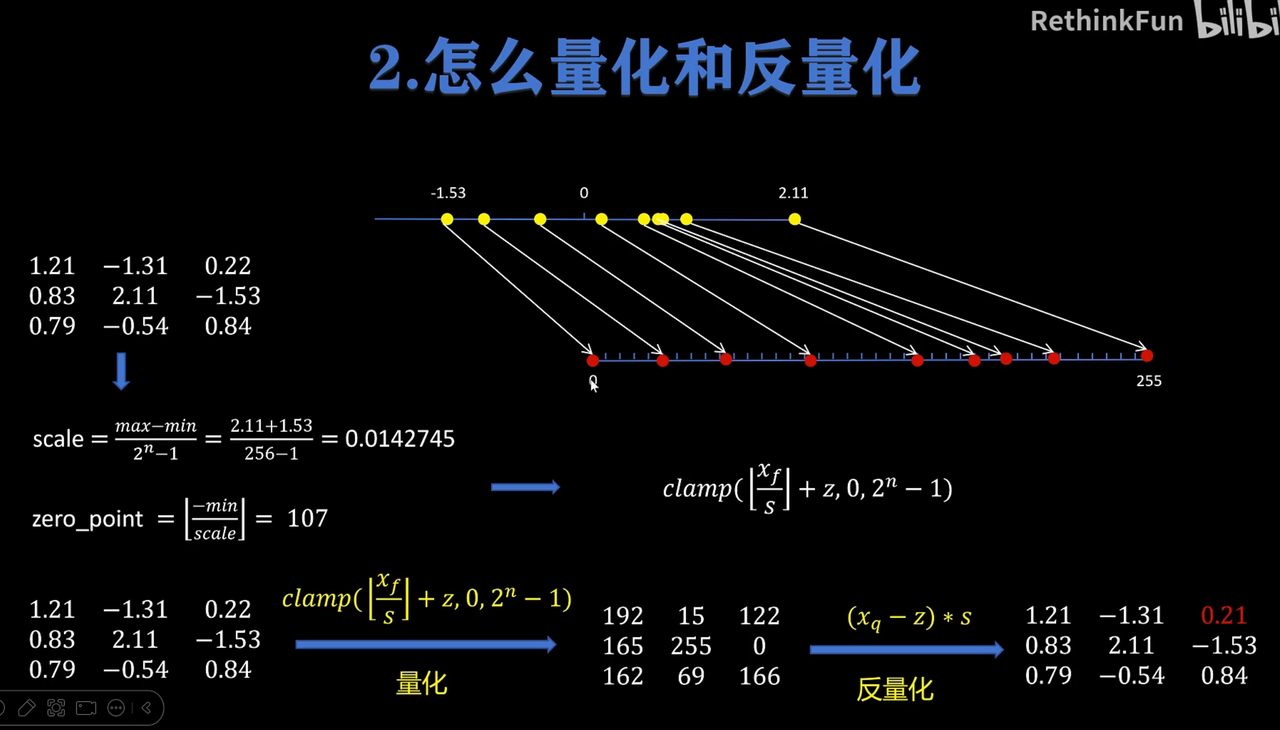
比较


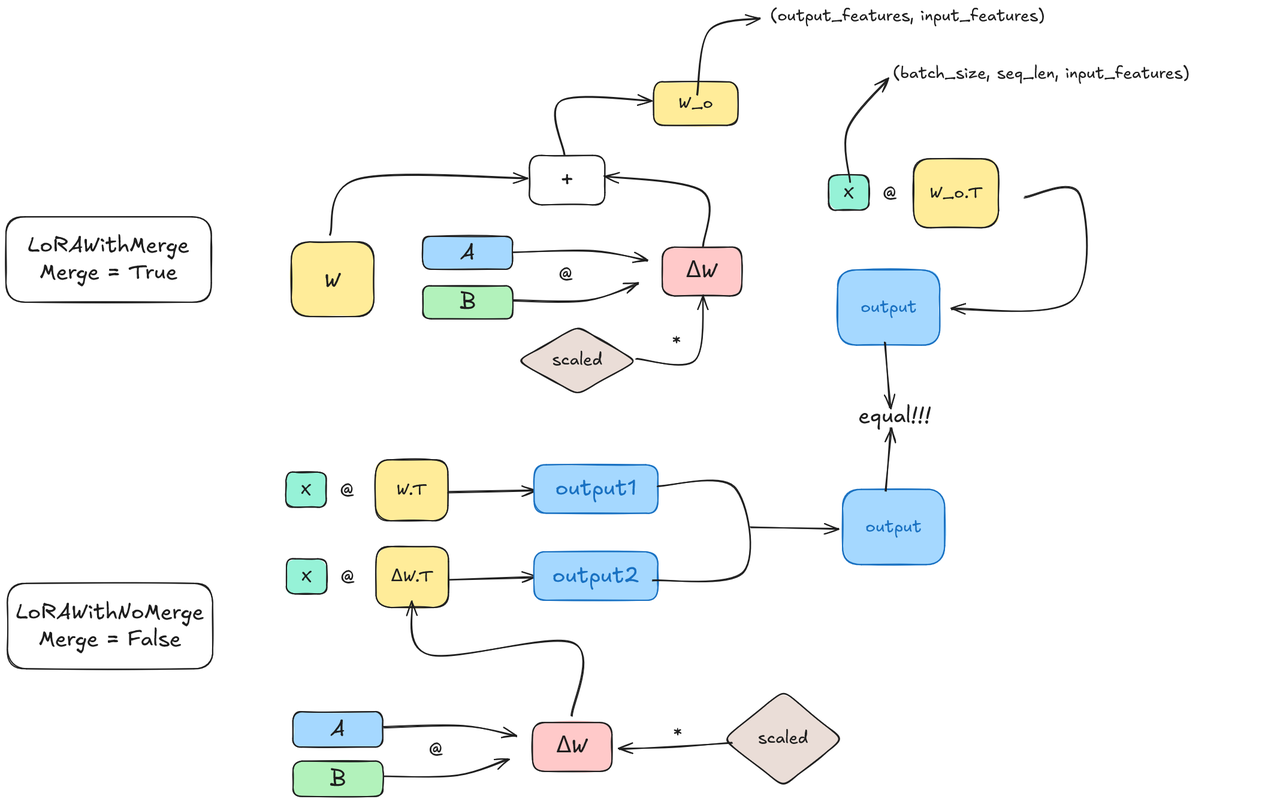
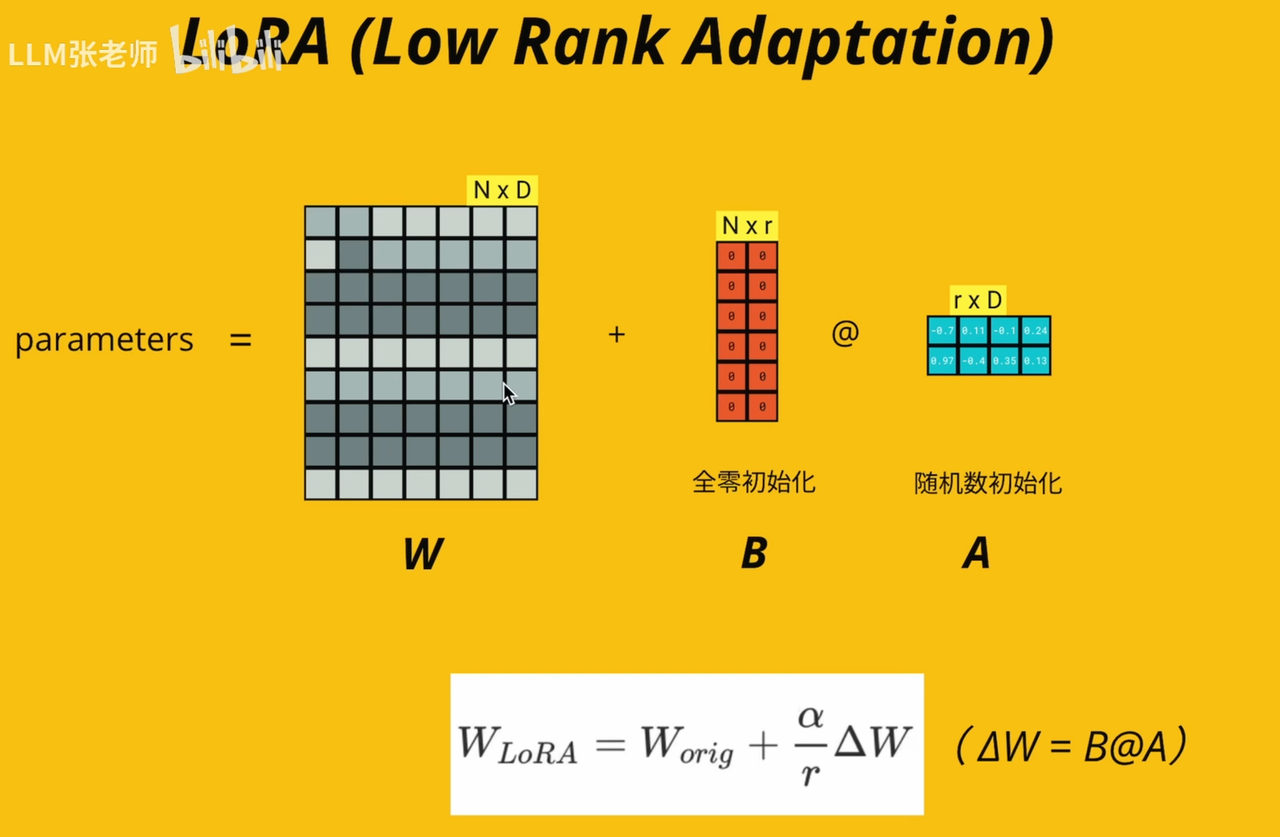
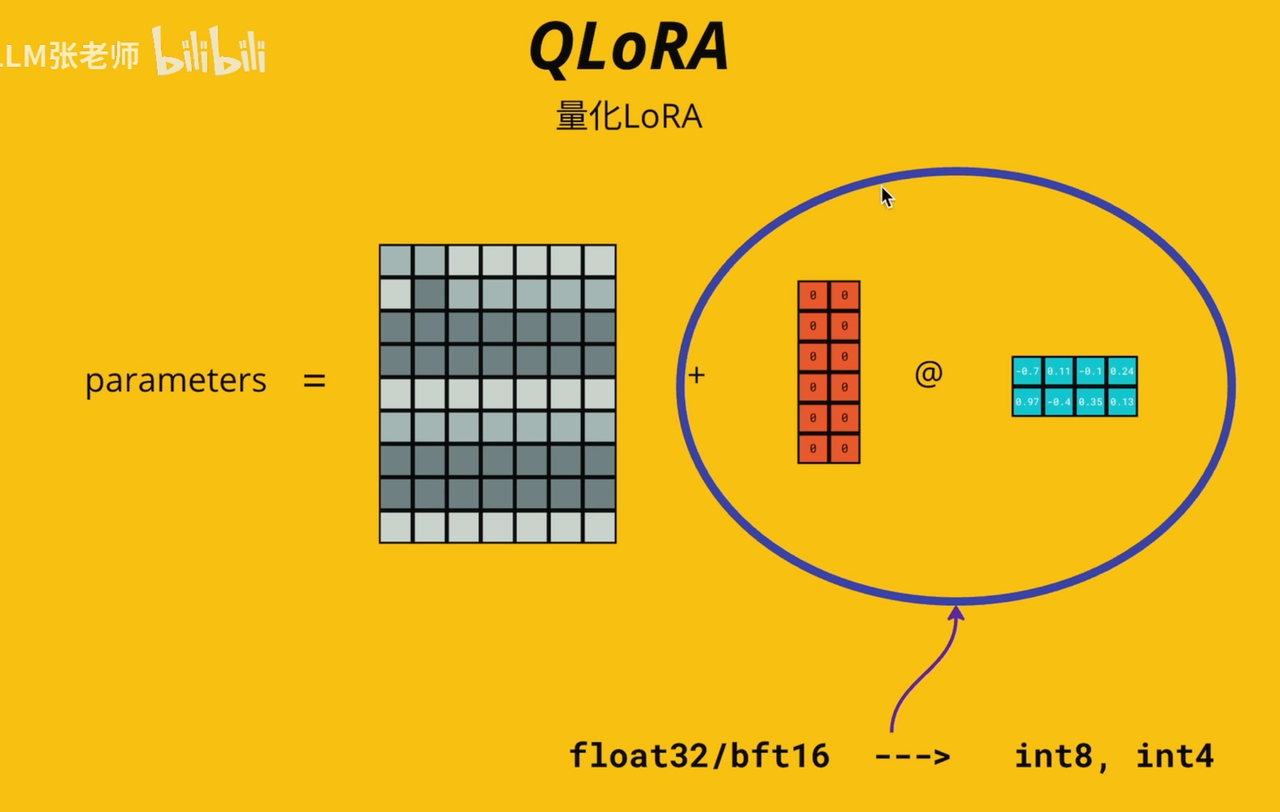
⚖️LoRA
手撕

🧑🏫MoE

⚡KV cache

😮ATTENTION
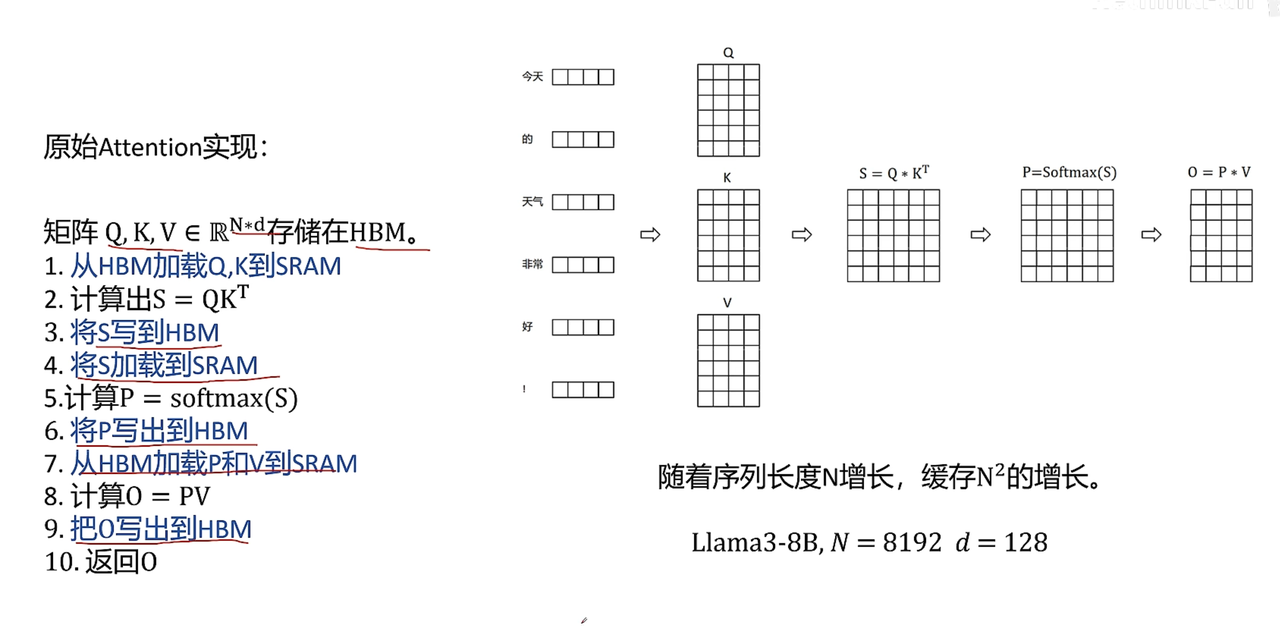
原始Attention
⚡Flash Attention

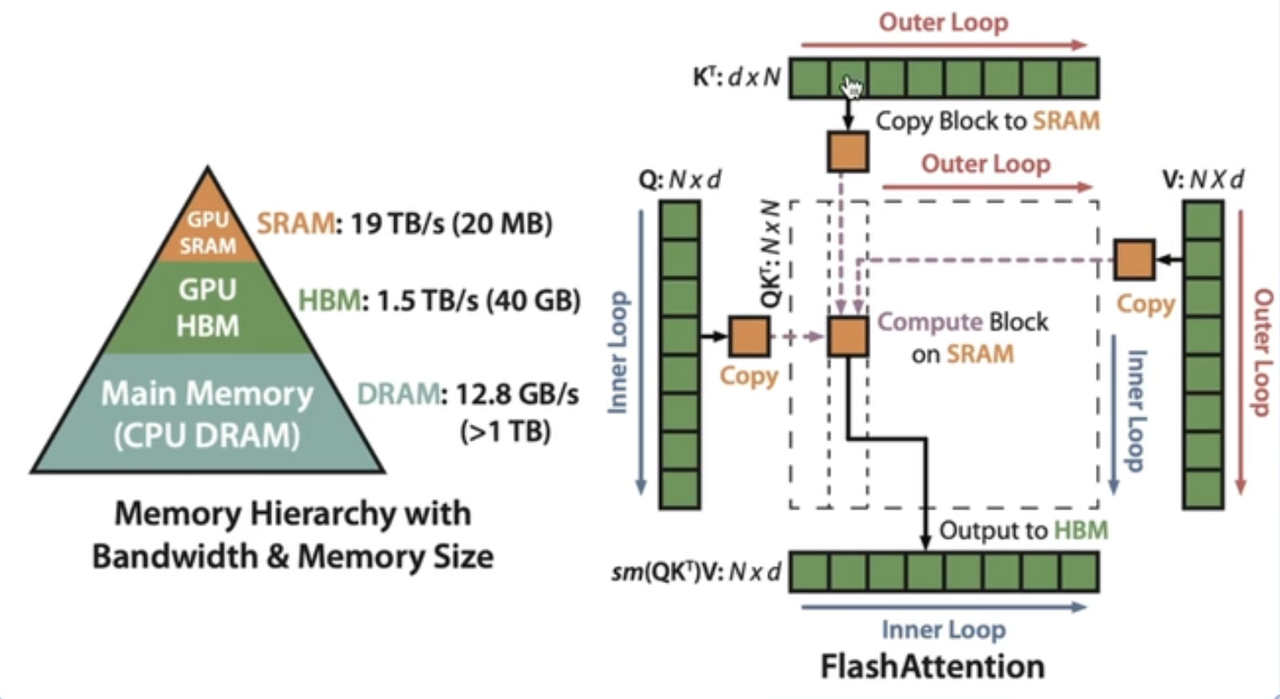
解决Memo-bound
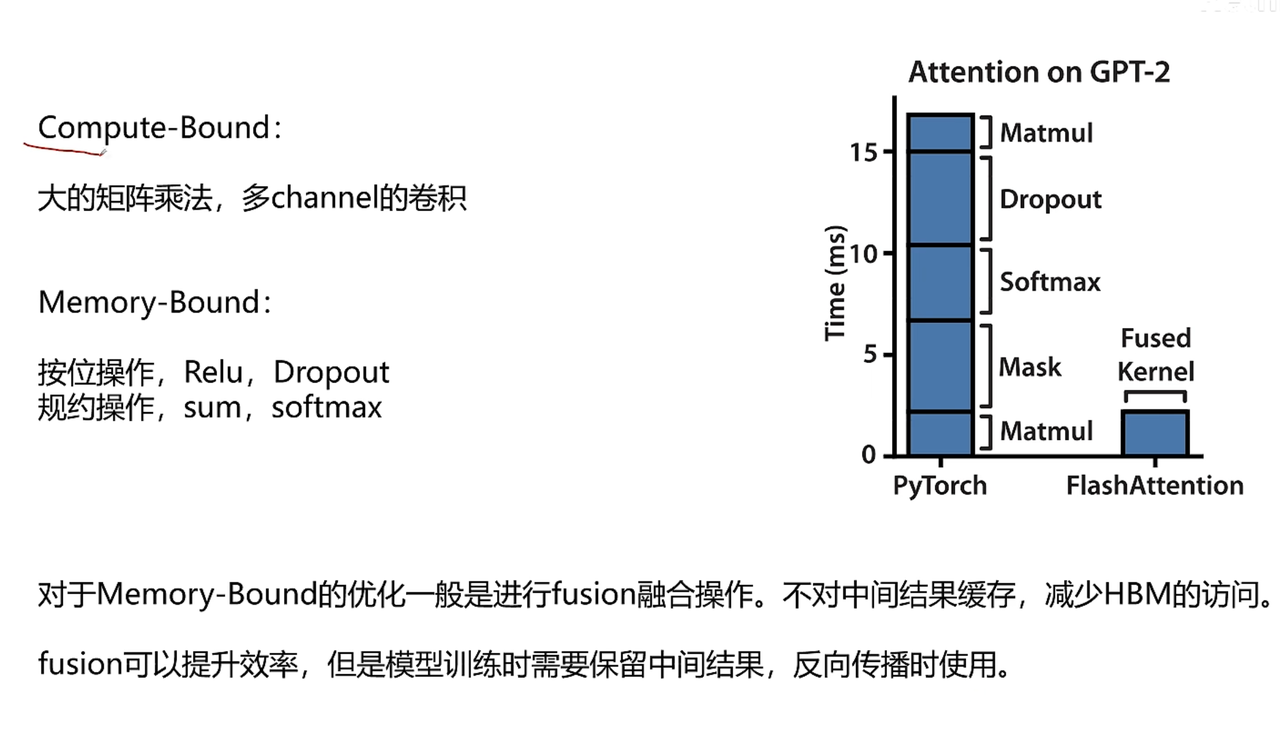
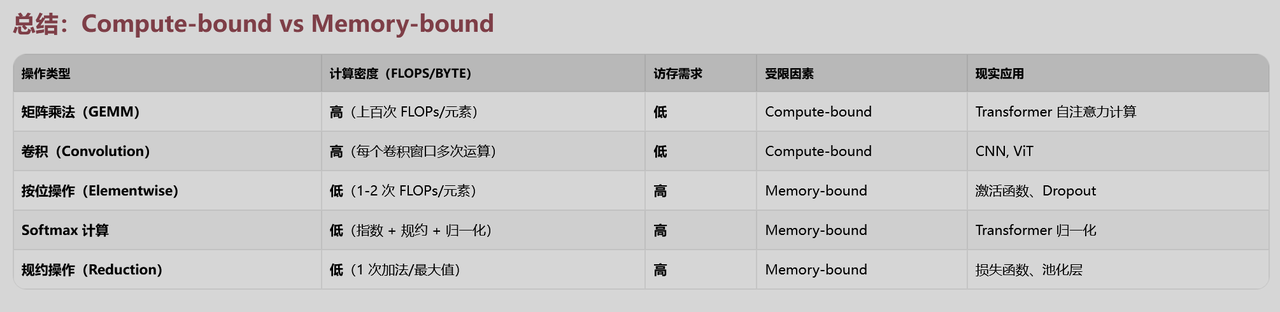
分块进入HBM,分块算
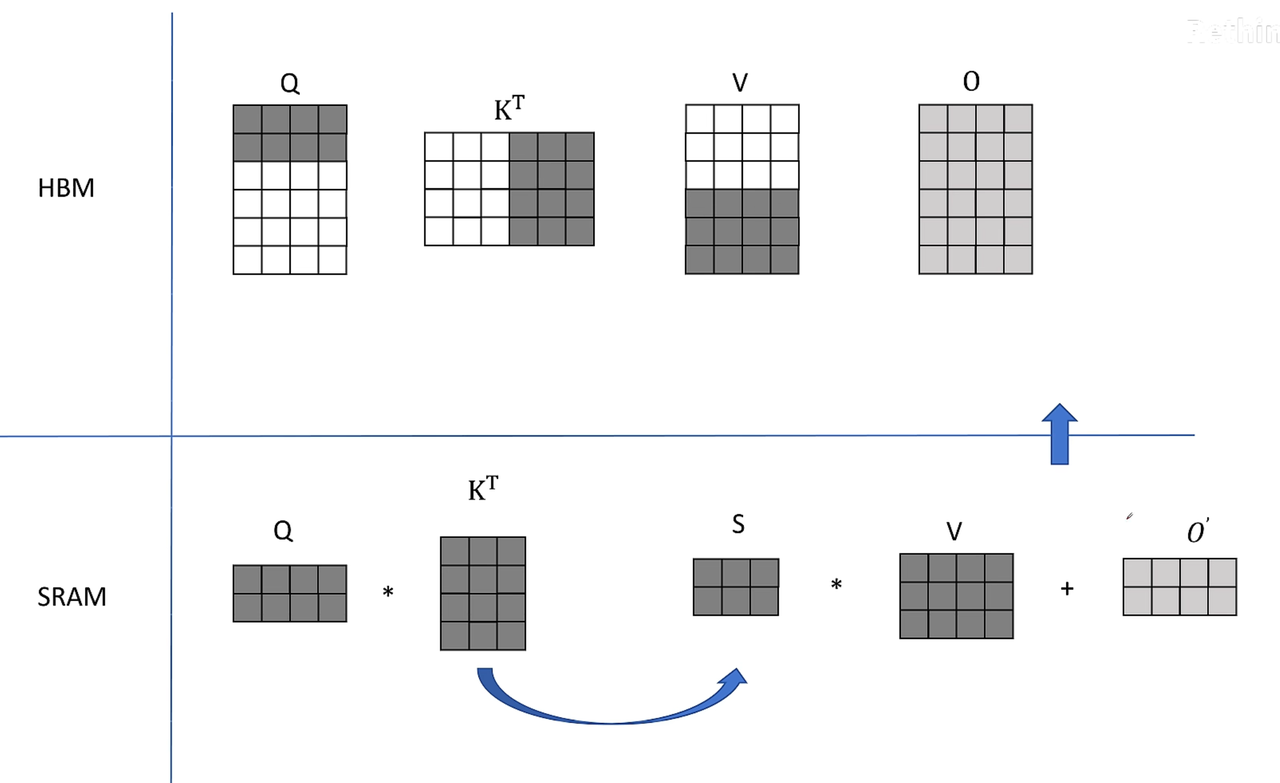
但是SM是按行算的,如何SM分块计算
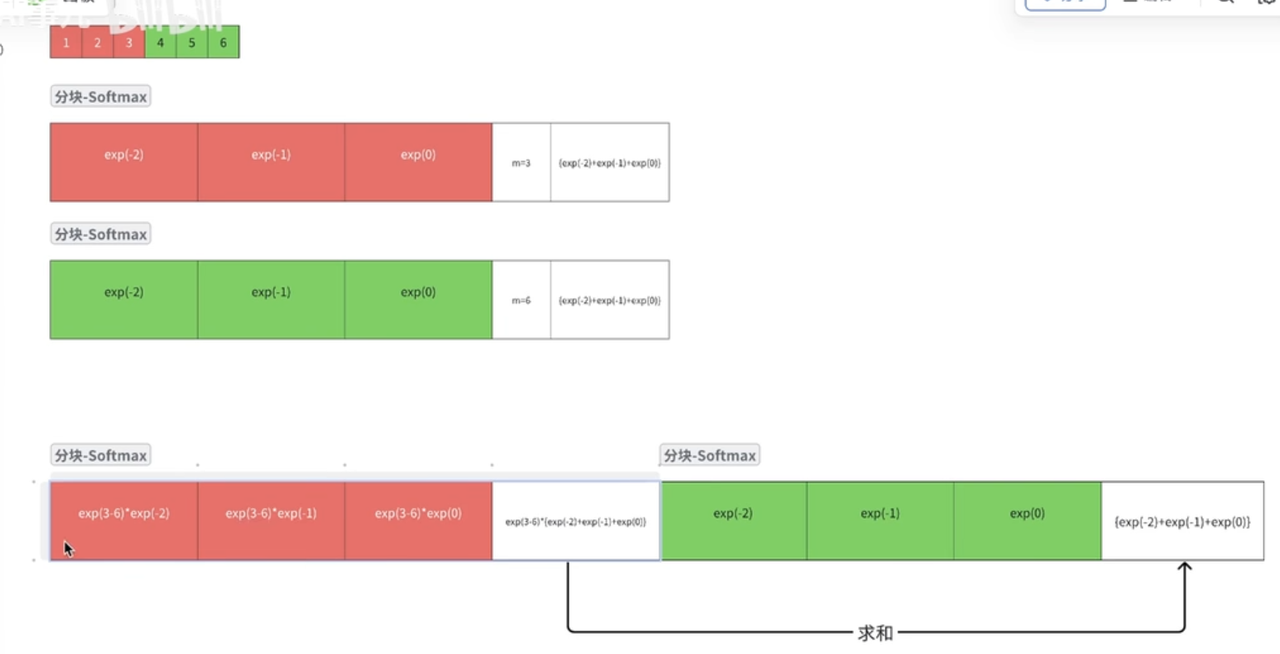
Safe-SM, 减去最大值防止float16溢出
基于Safe-SM,进行分块

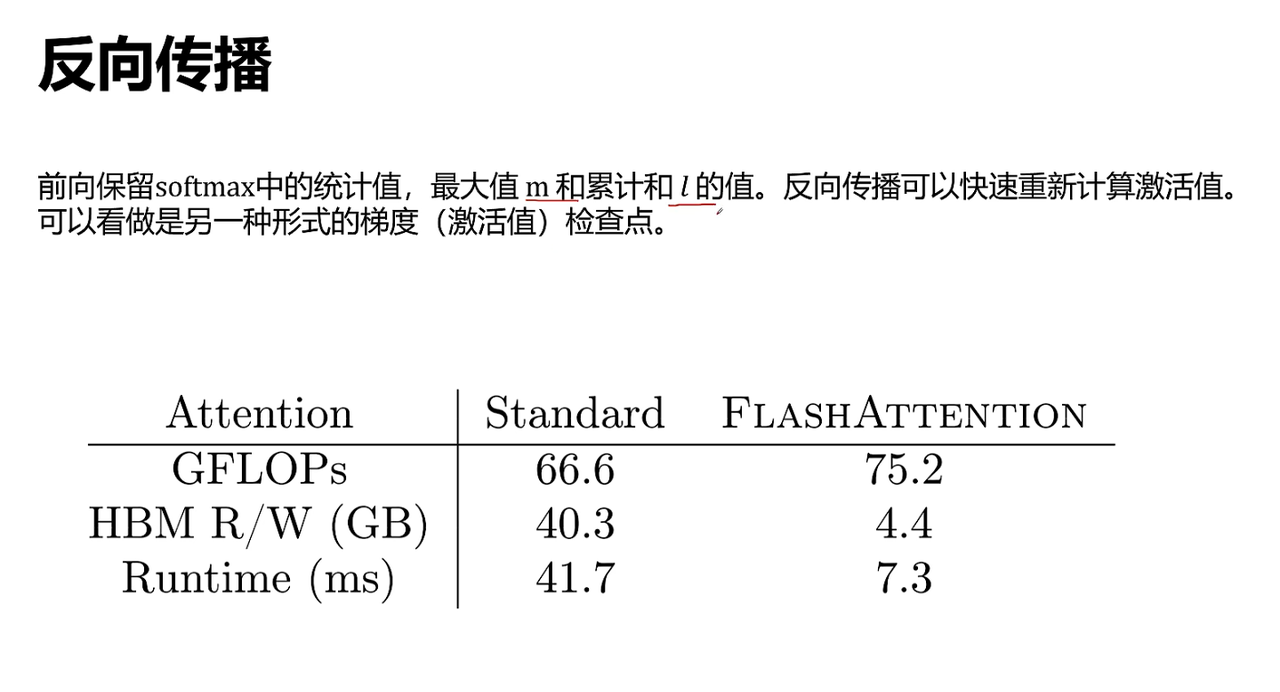
算法流程


⚡Sparse Attention
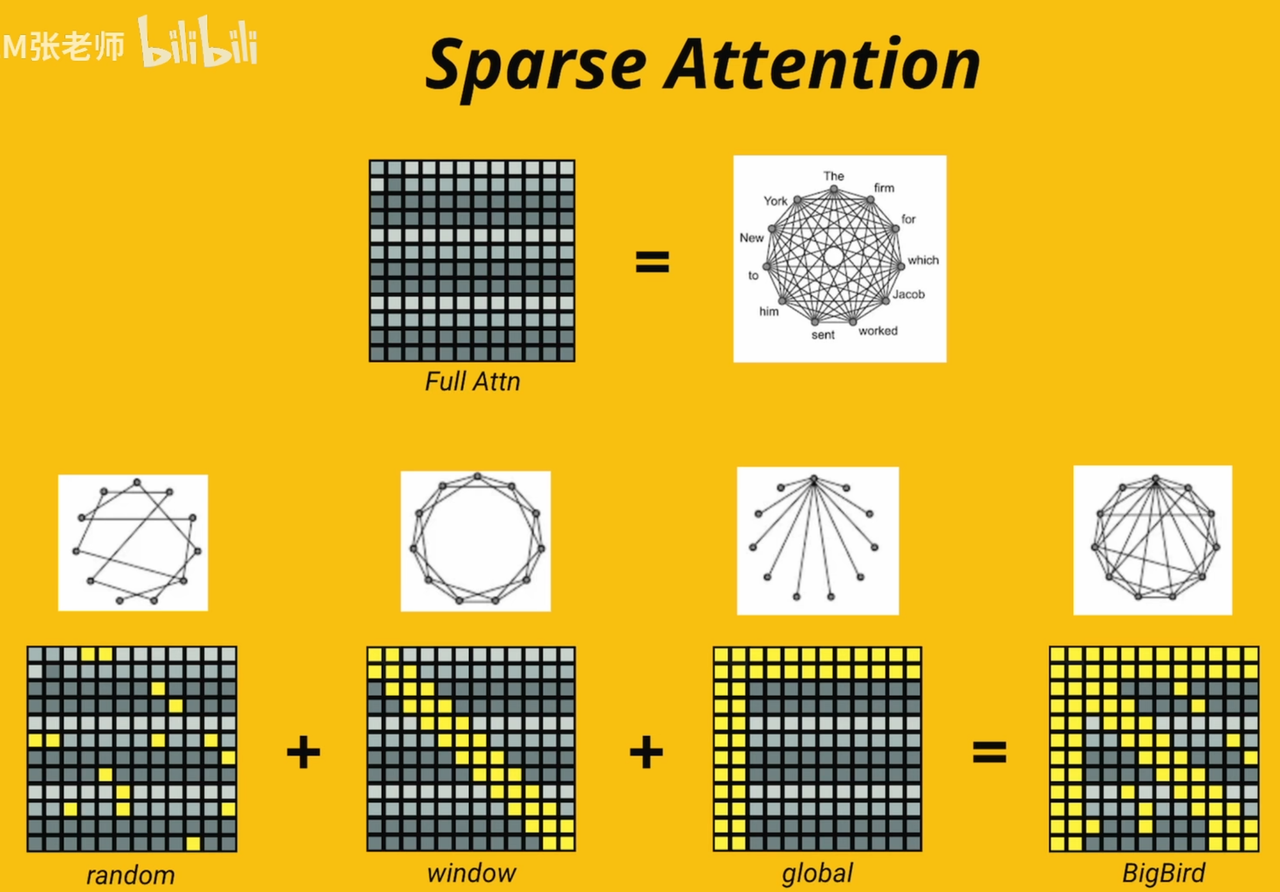
⚡DeepSeek Native Sparse Attention
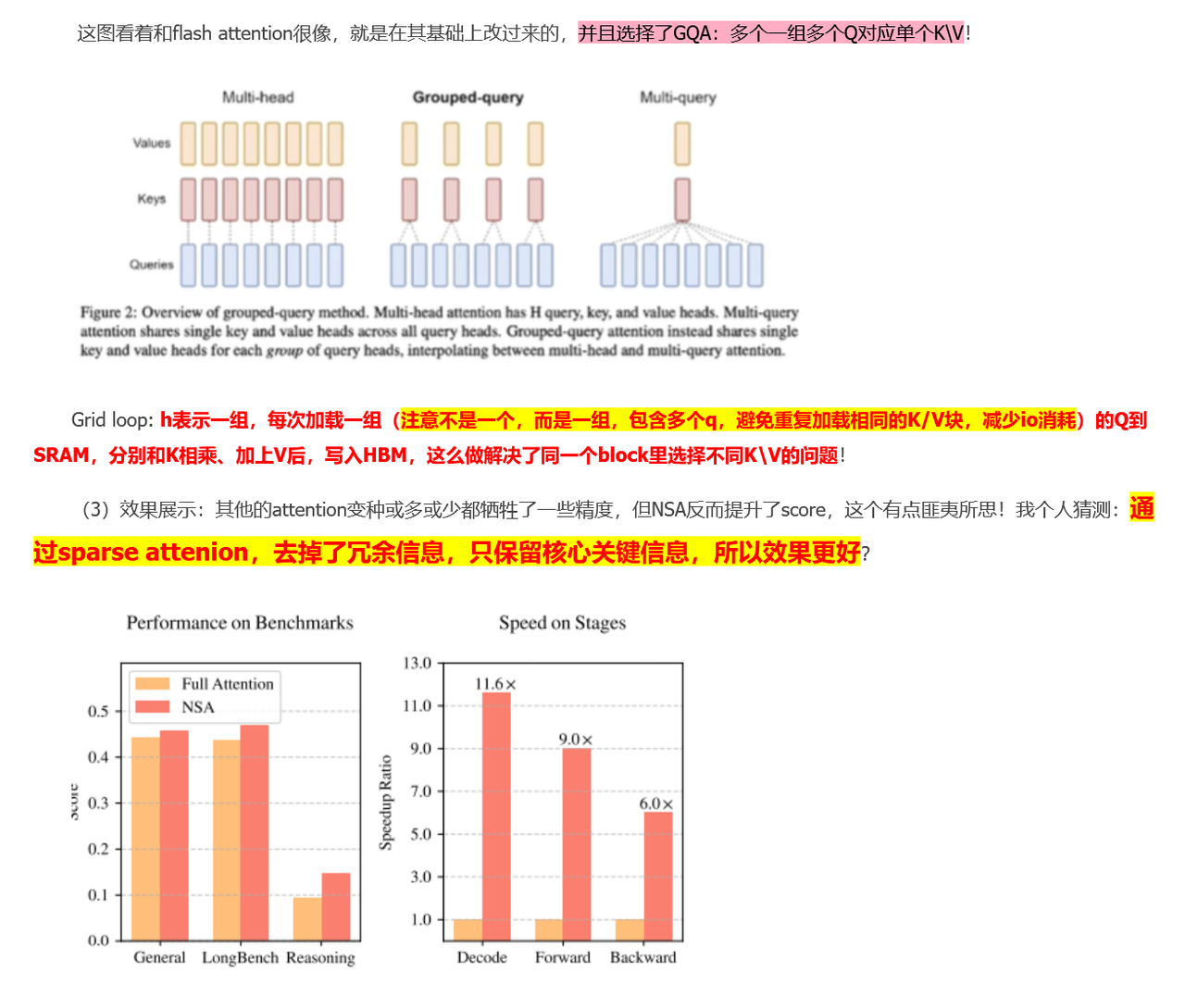
整体优化部分
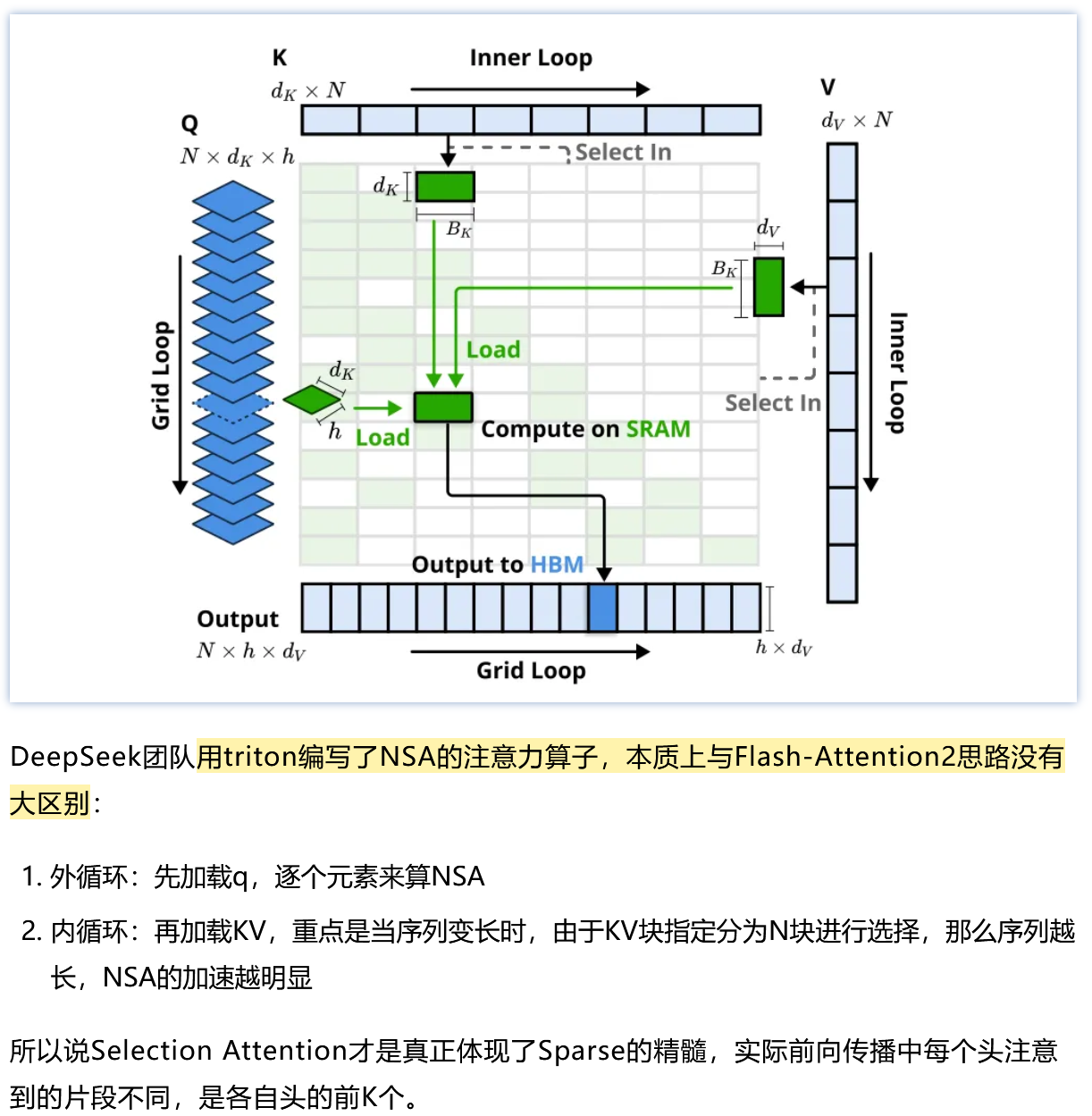
Kernel优化



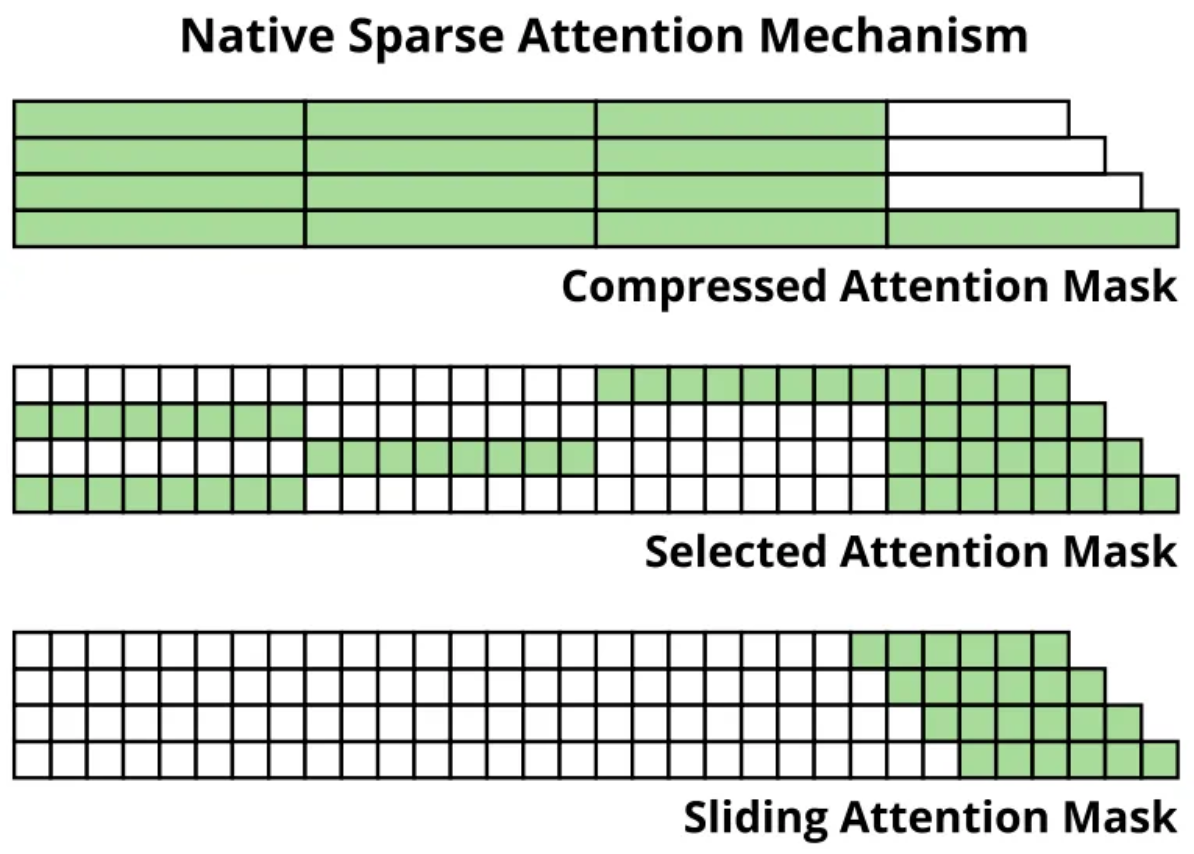
- 压缩注意力:把控全局粗粒度信息
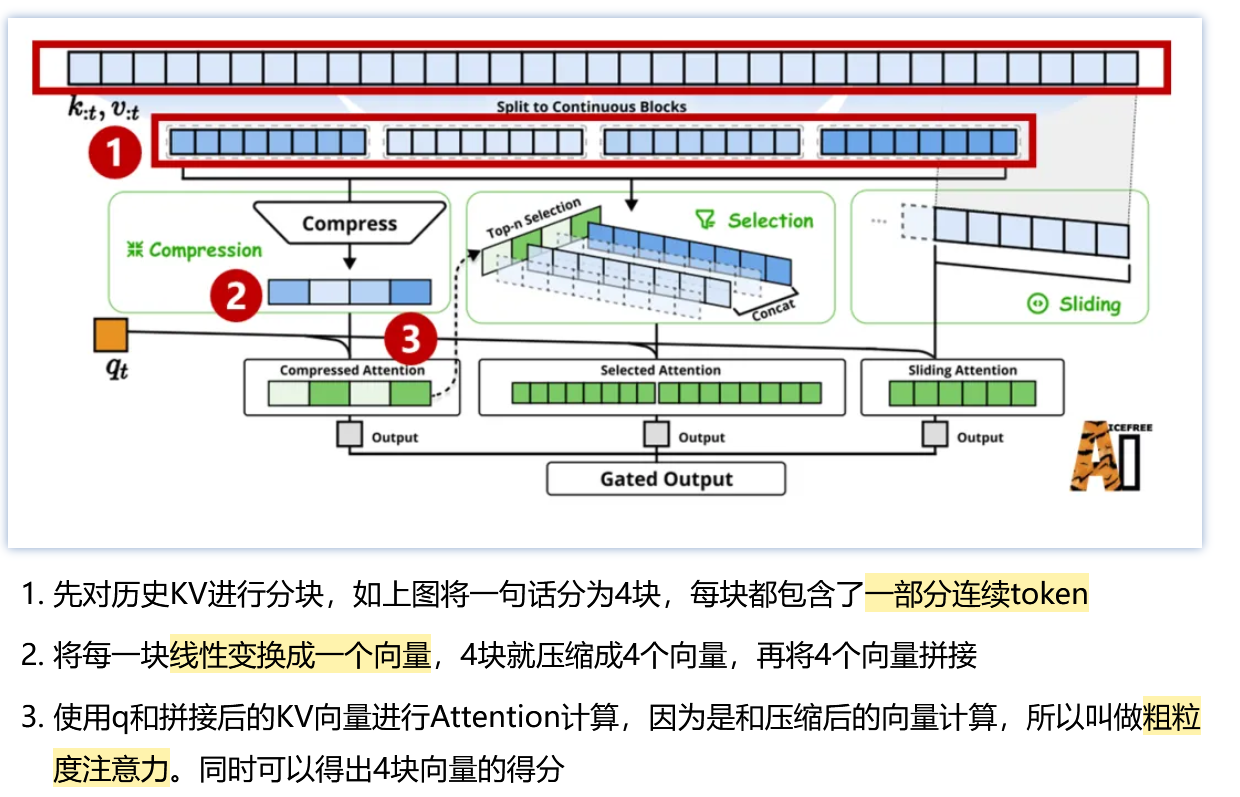
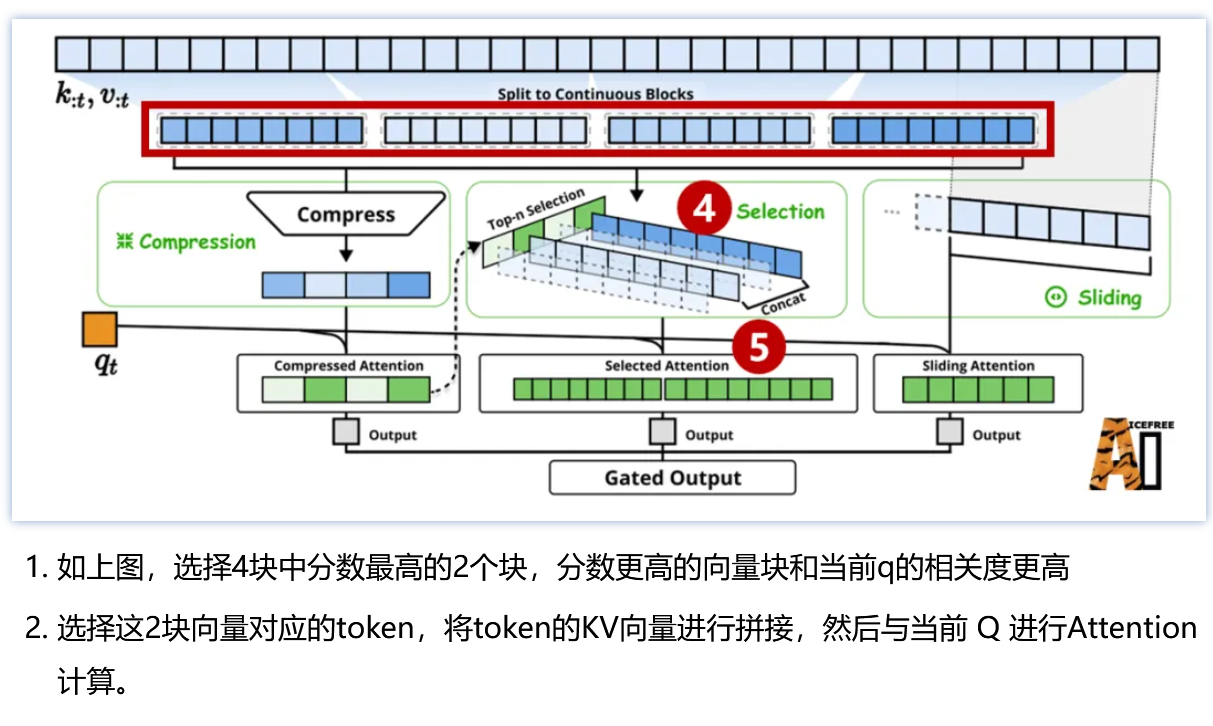
- 选择注意力:把控局部相关重要信息
- 滑窗注意力:把控临近紧密信息
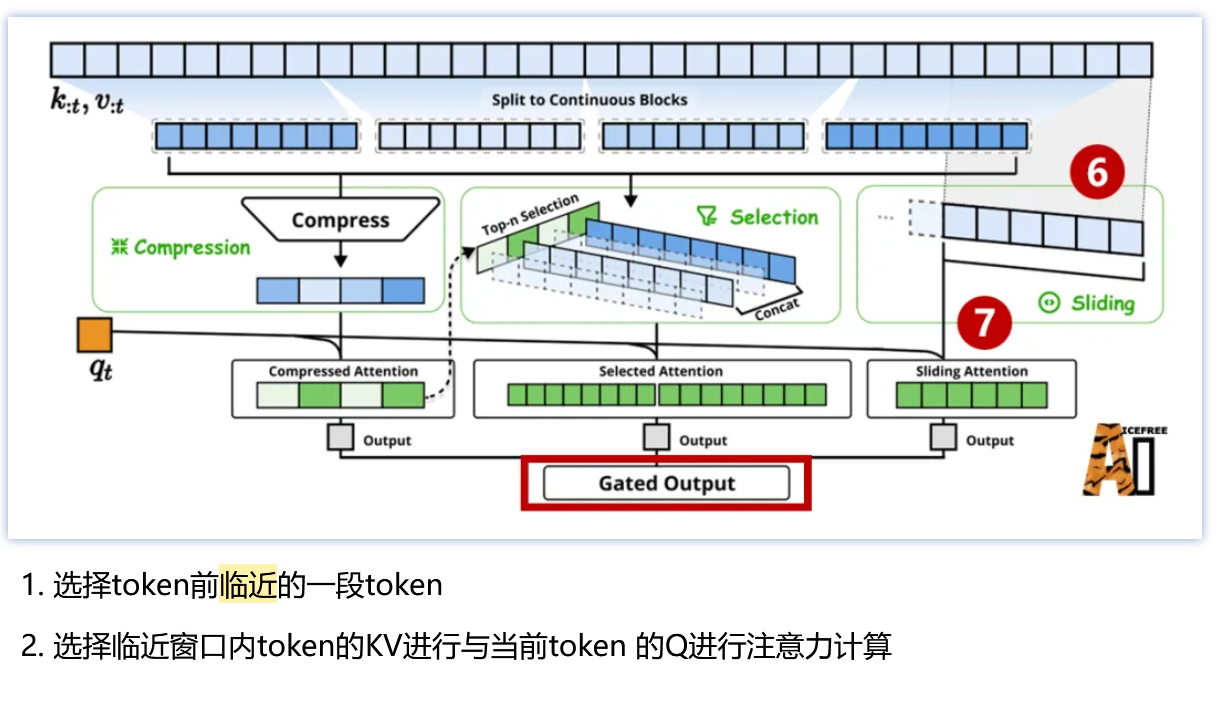
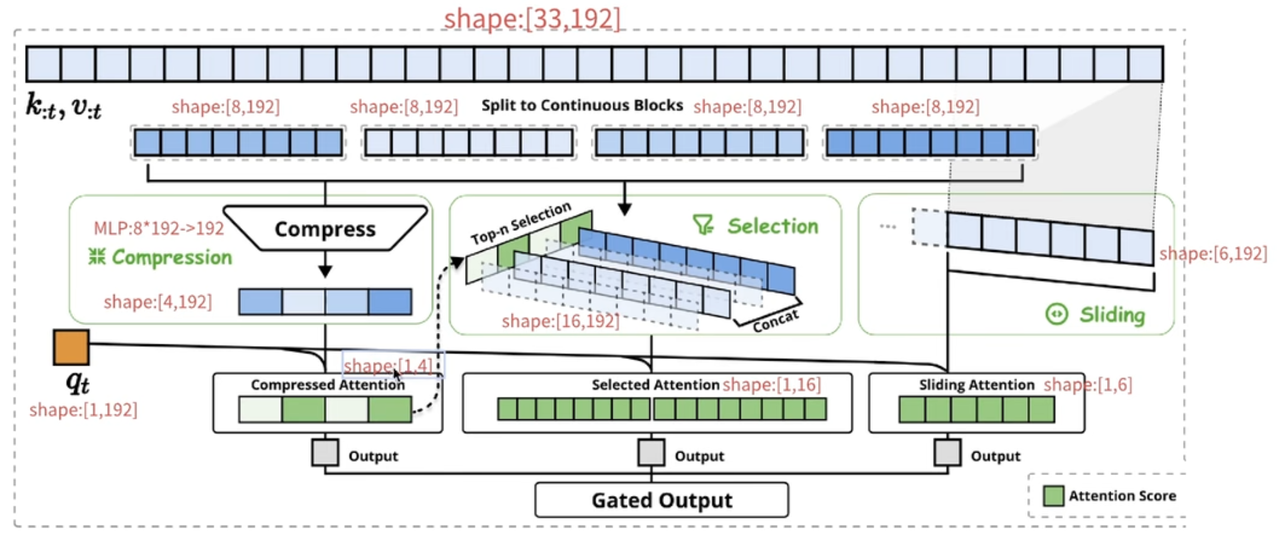
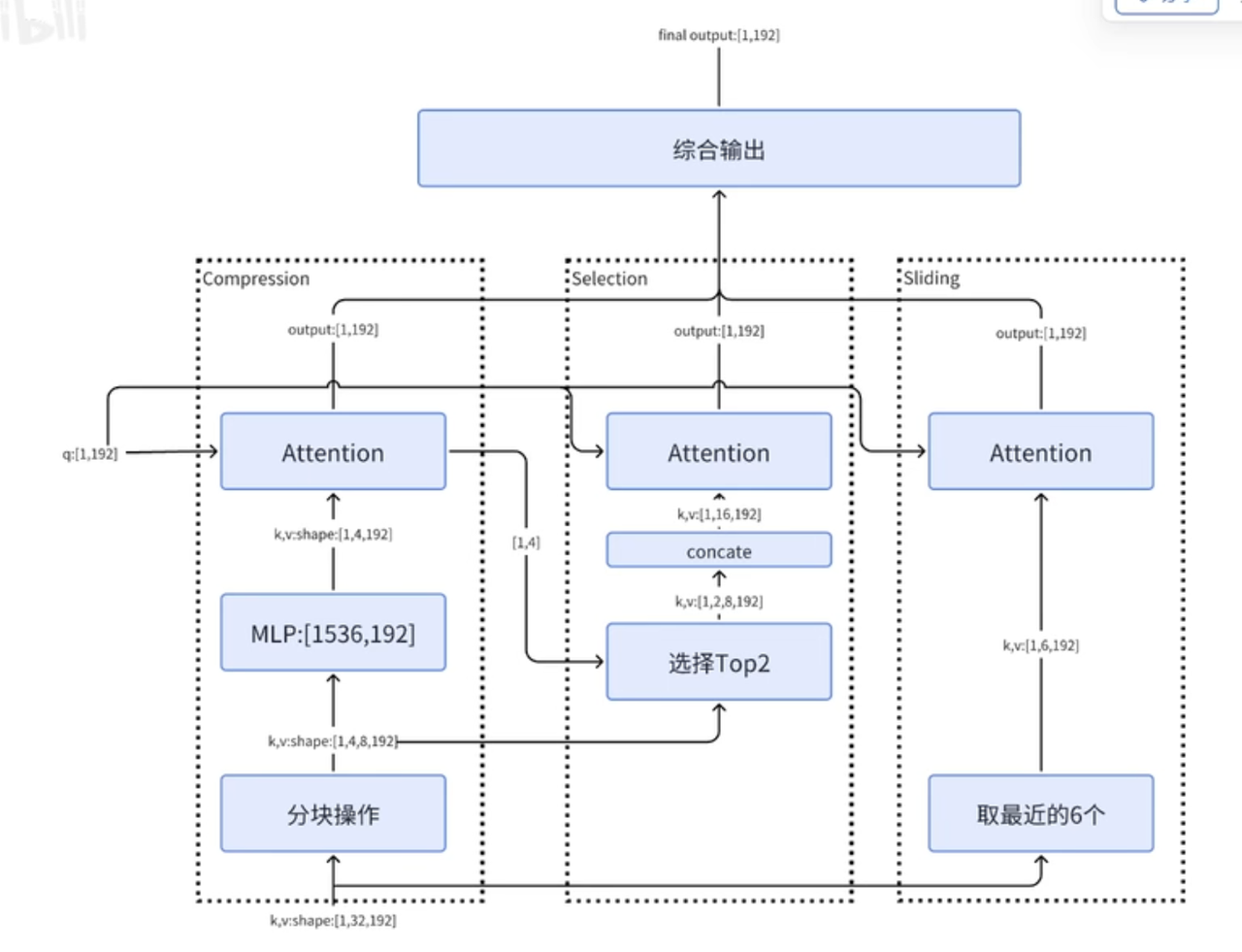
把三种注意力输出进行合并,通过门控机制(线性变化+sigmoid)为最终注意力输出
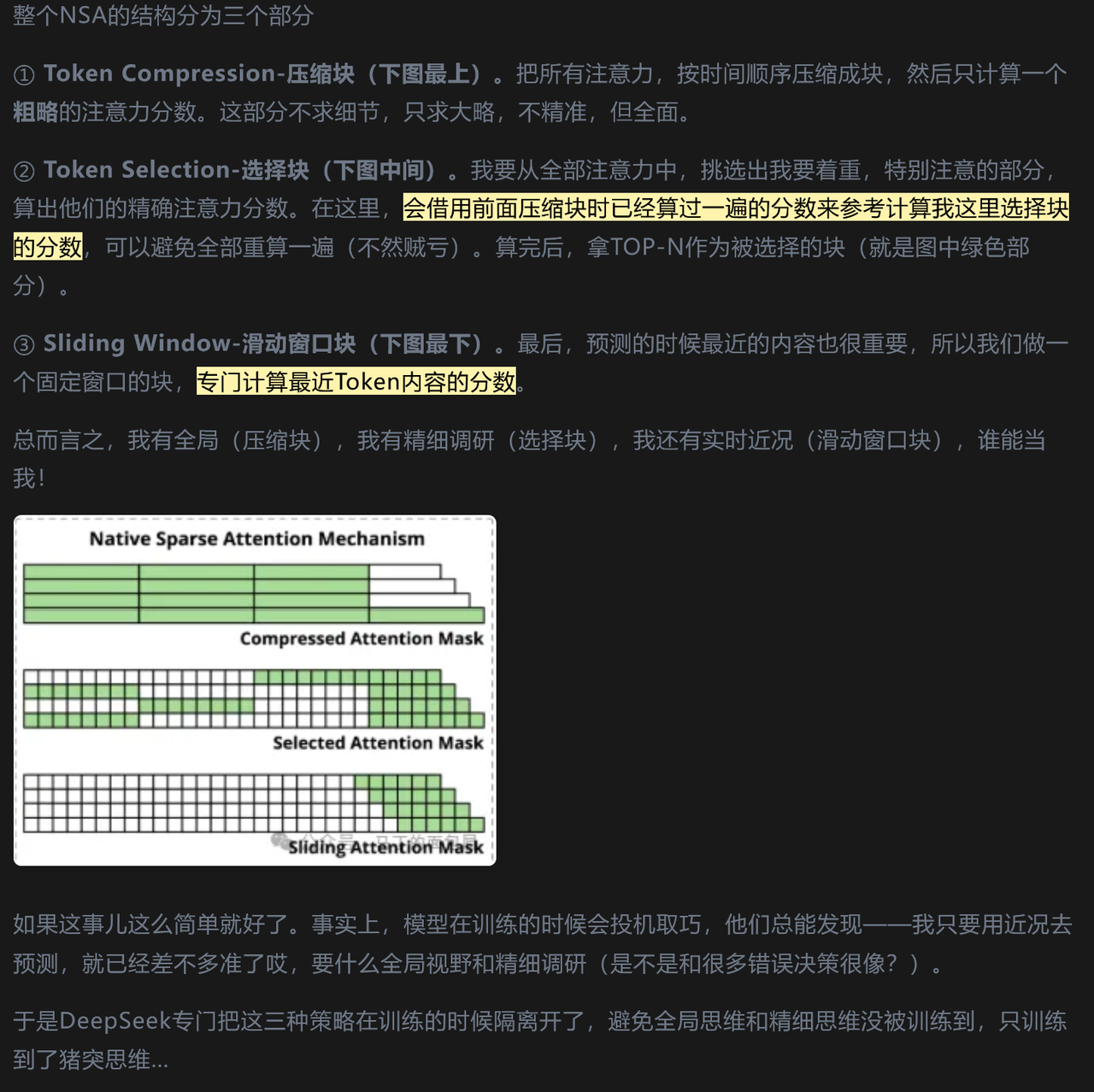
⚡(Efficient) Linear Attention
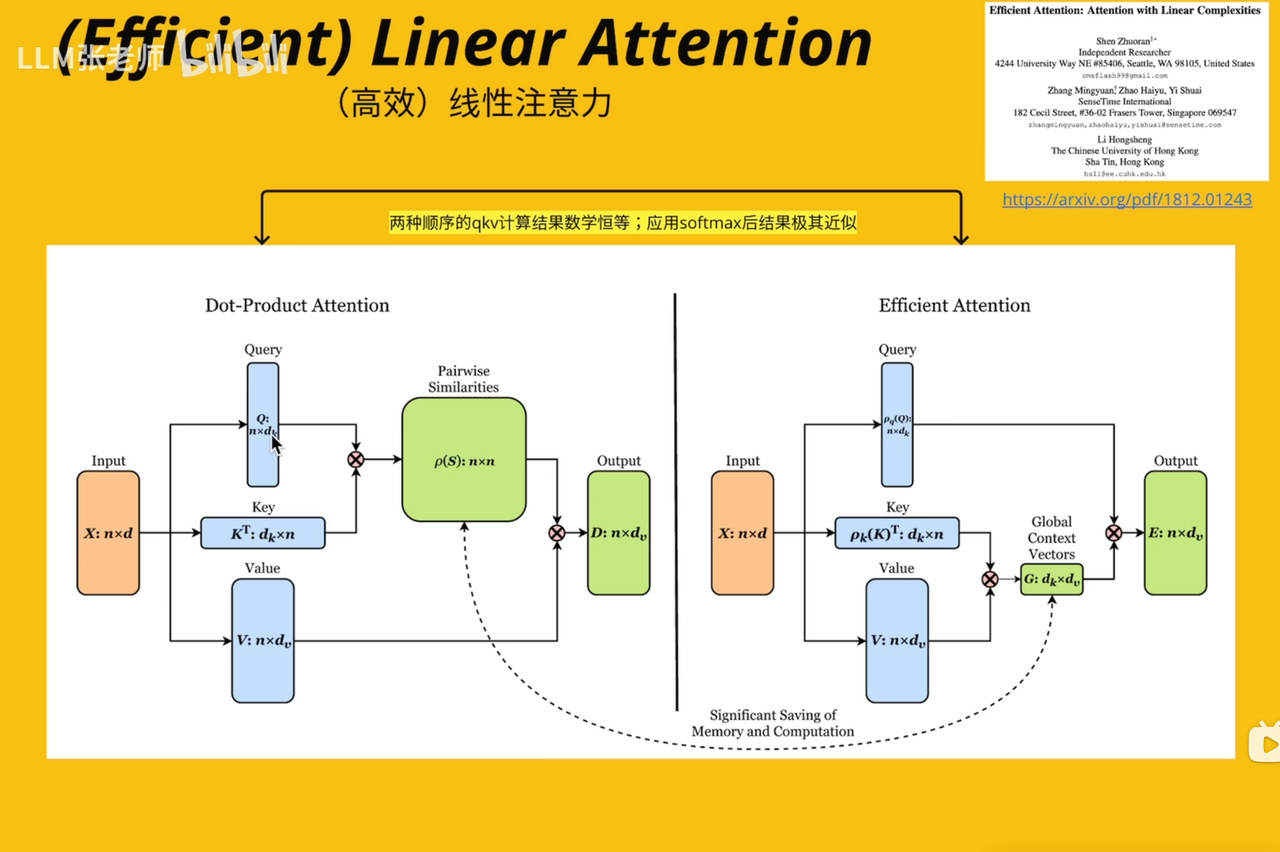

⚡Infinity Attention
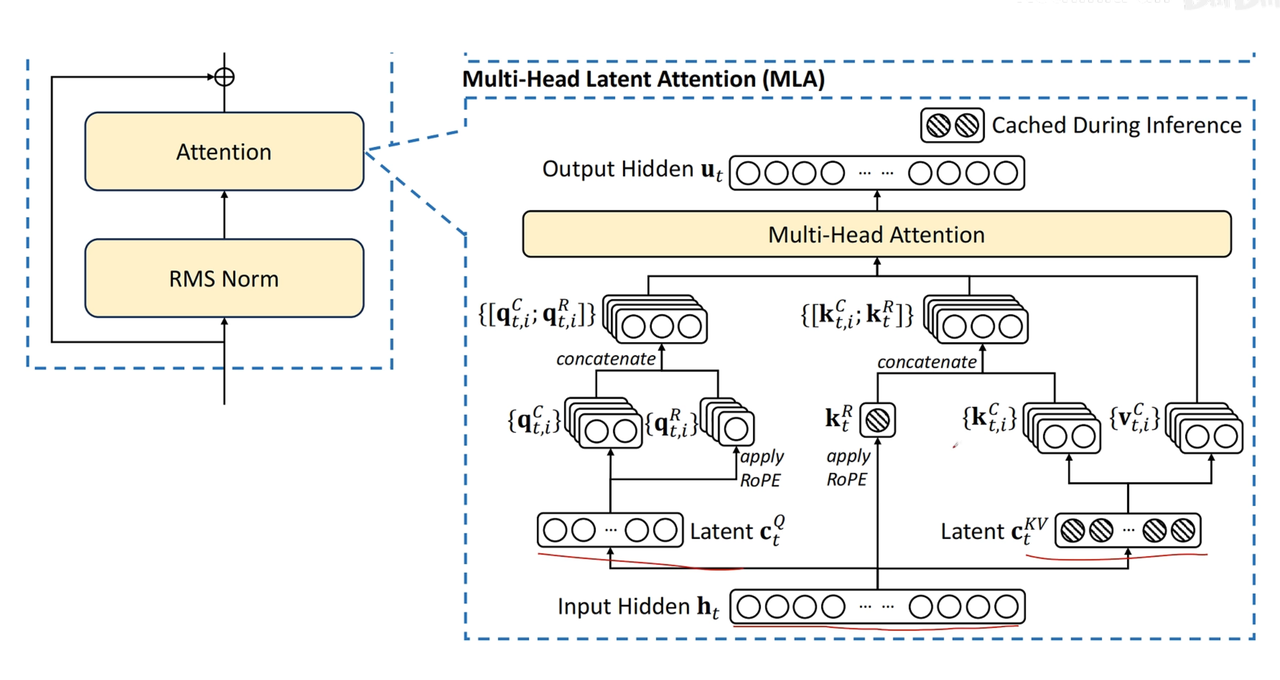
⚡MHA/MQA/GQA/MLA
DeepSeek-v2 MLA 原理讲解_哔哩哔哩_bilibili
三者的缓存量
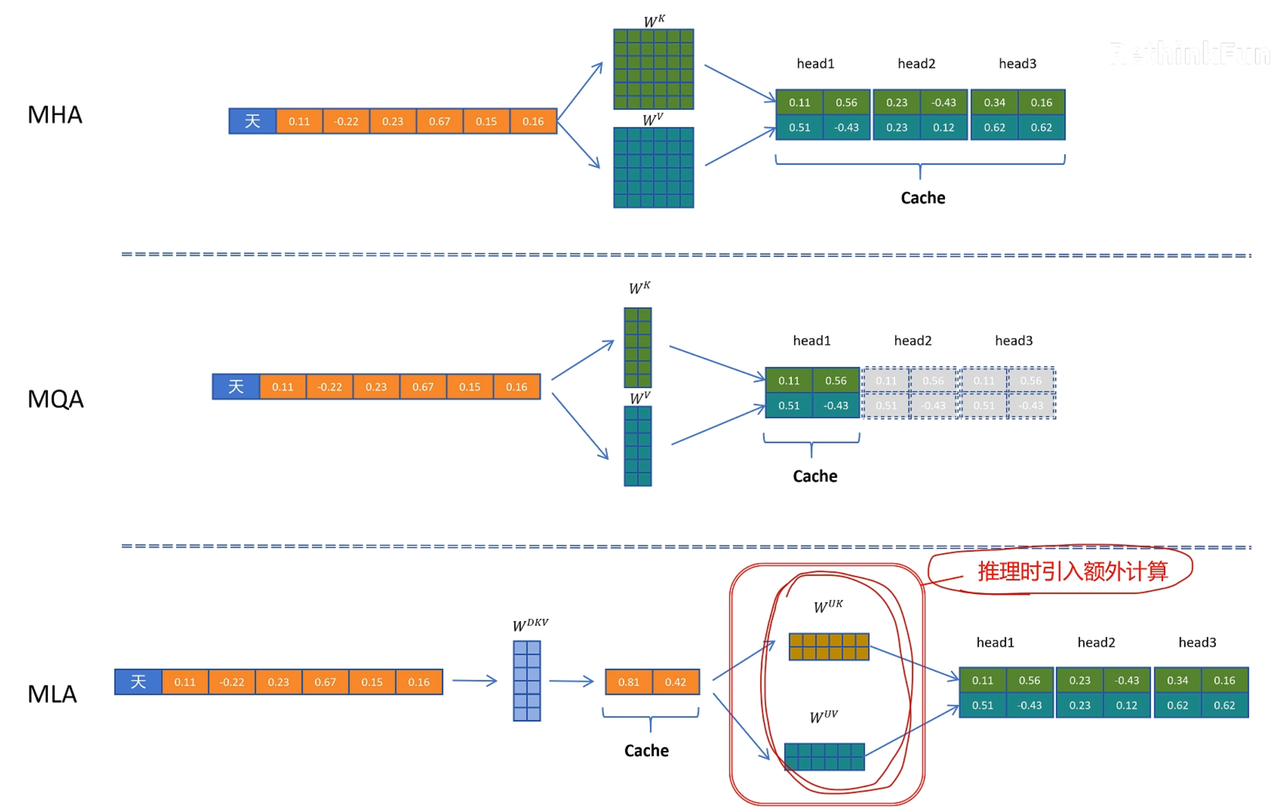
MLA的矩阵融合
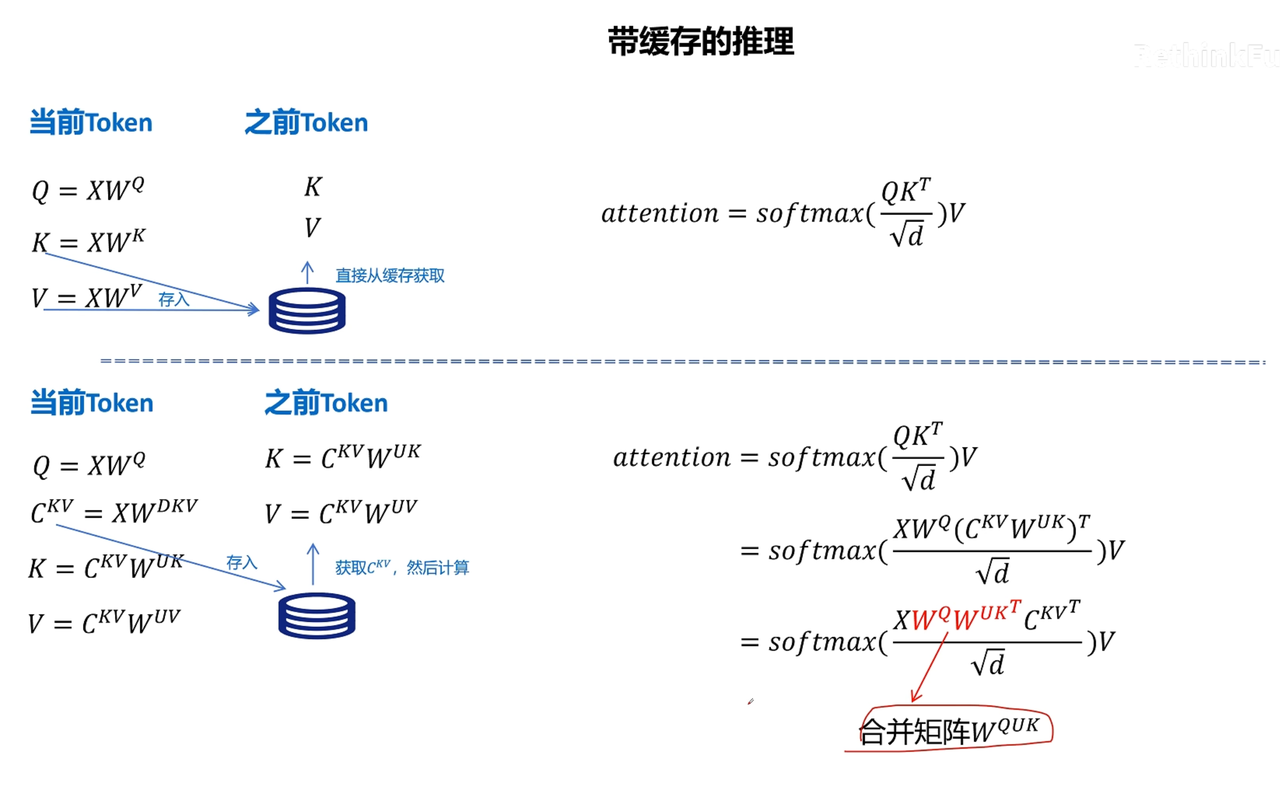
考虑RoPE,无法矩阵融合
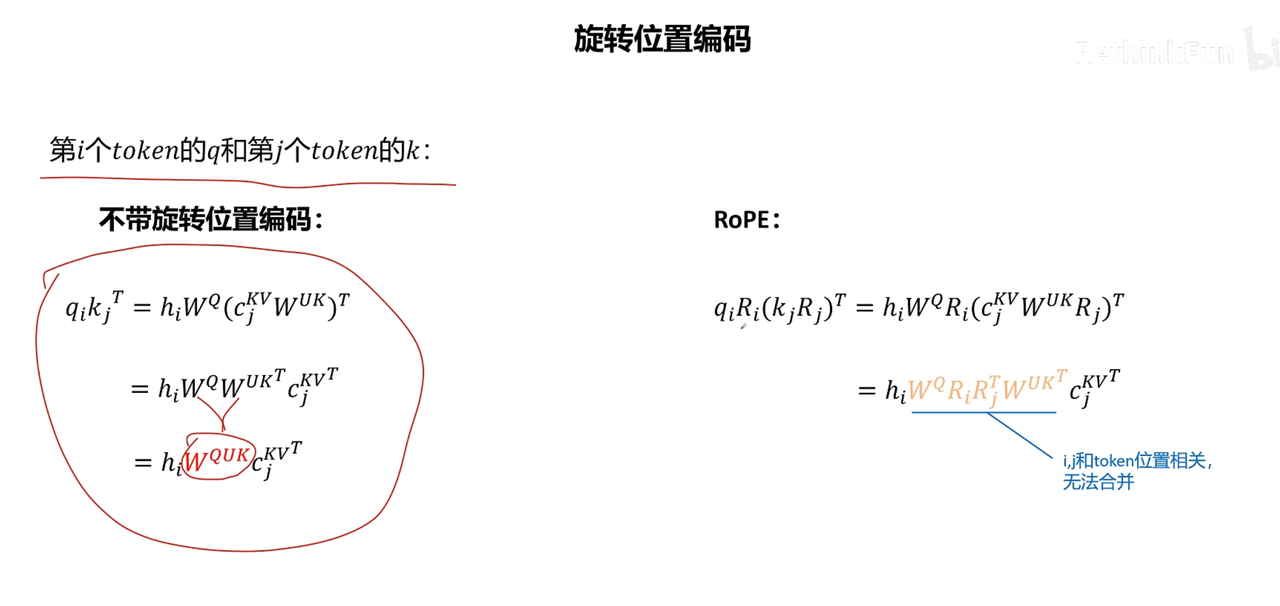
考虑拼接,但需缓存一共享特征(此特征用于计算带位置编码的K向量)
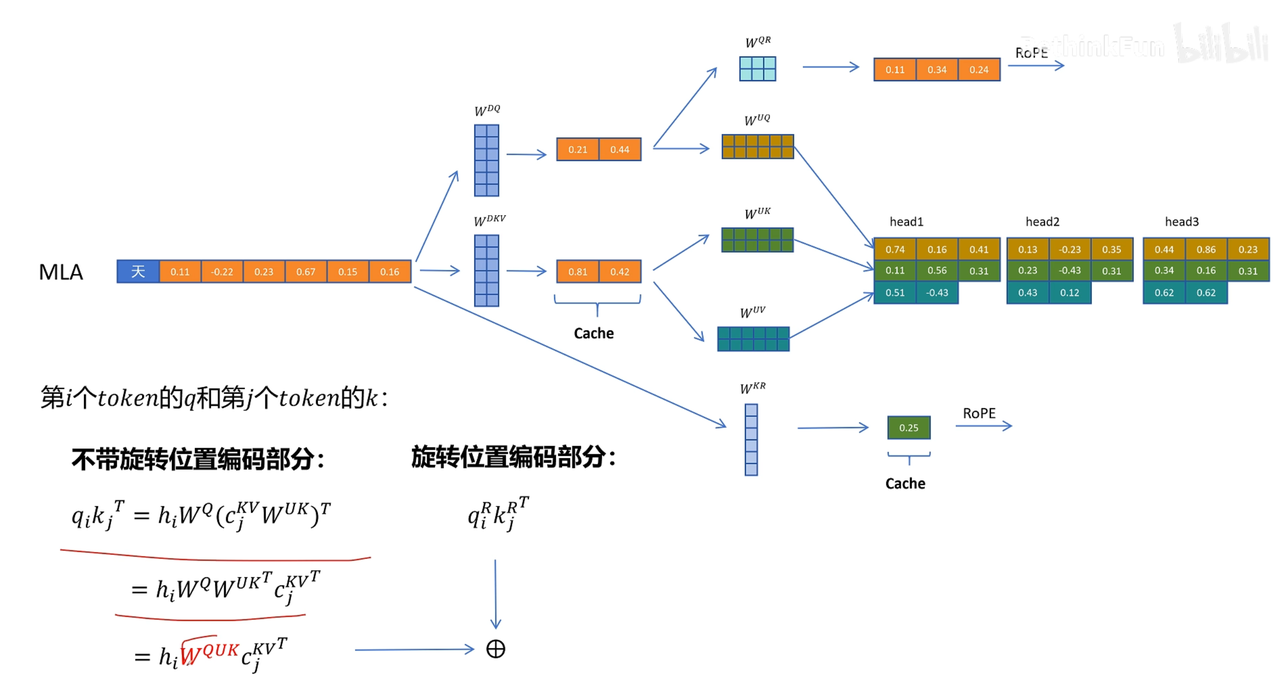
再看原论文图像
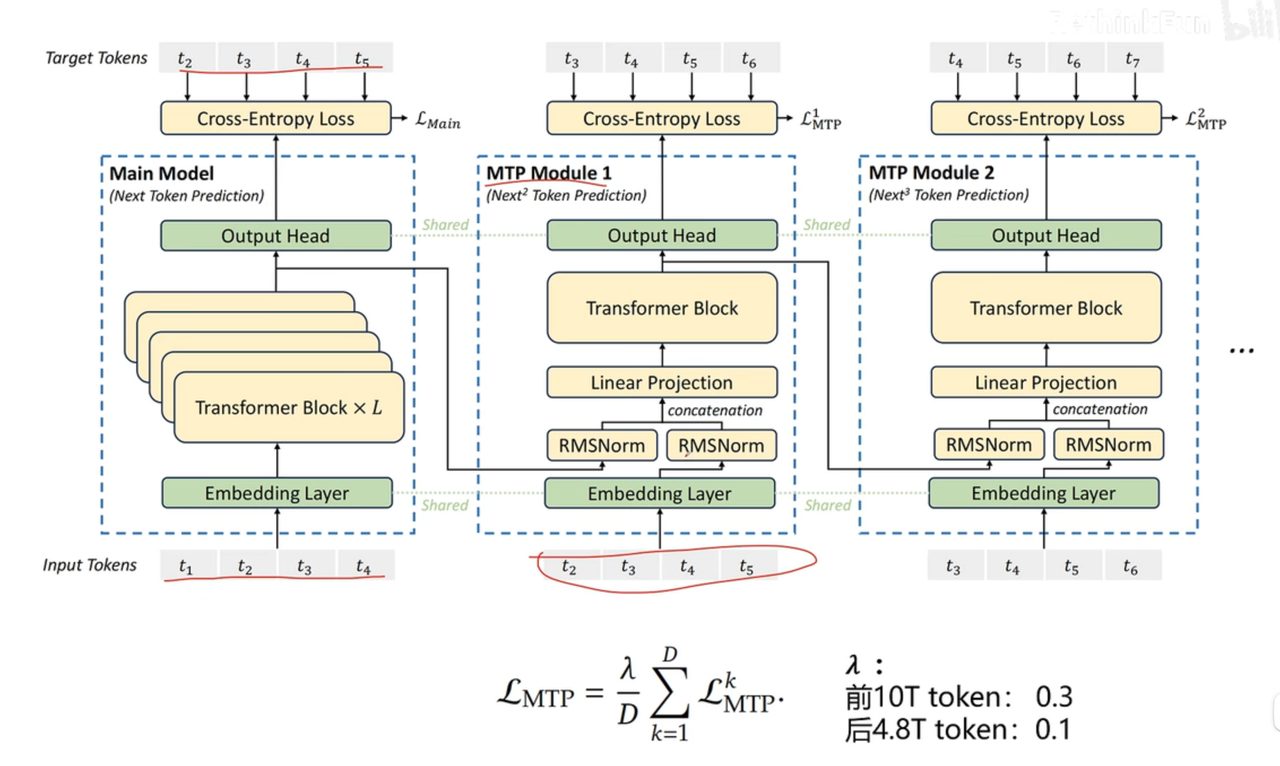
🔢MTP
直觉理解
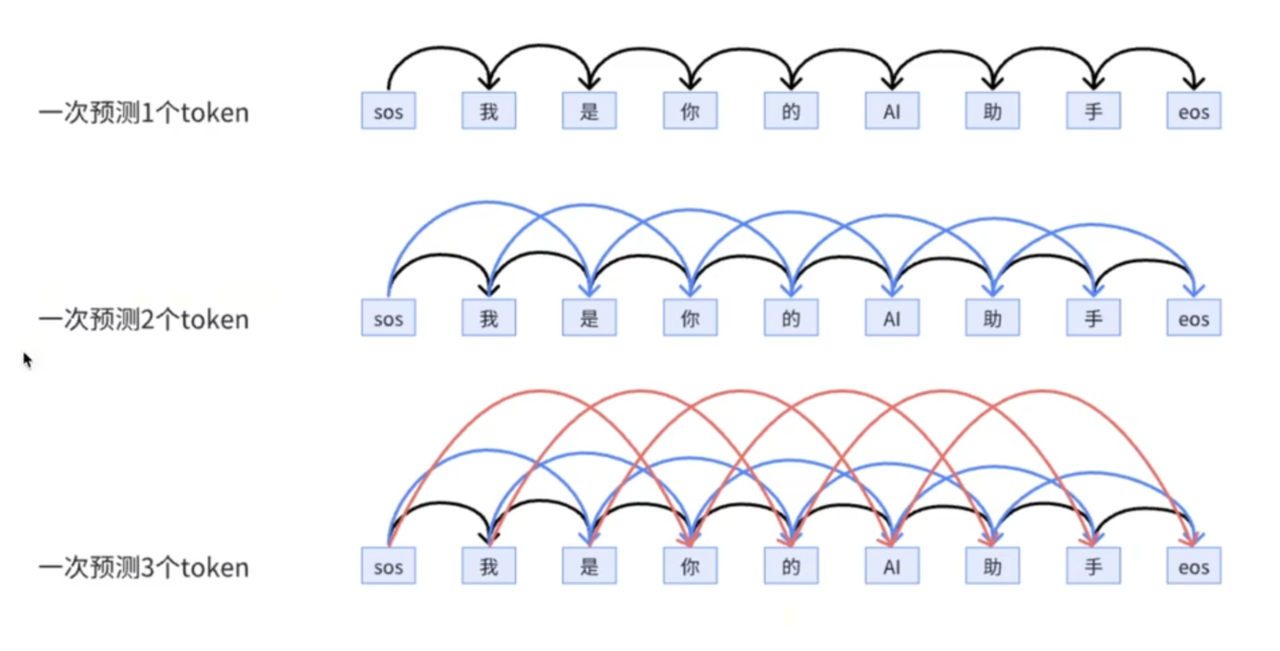
原始MTP

DeepSeekMTP