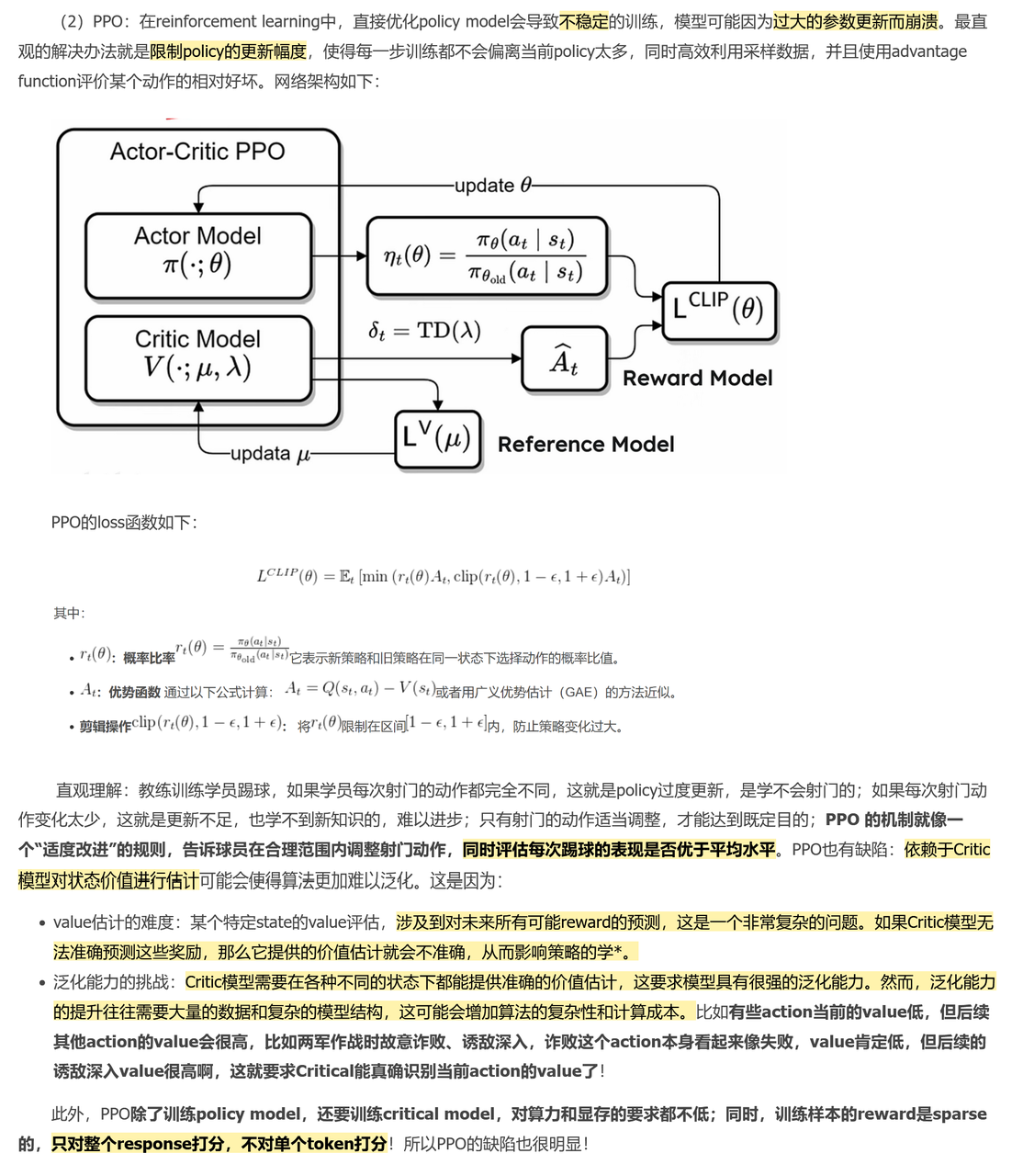
💯PPO/DPO/GRPO
梗概
策略
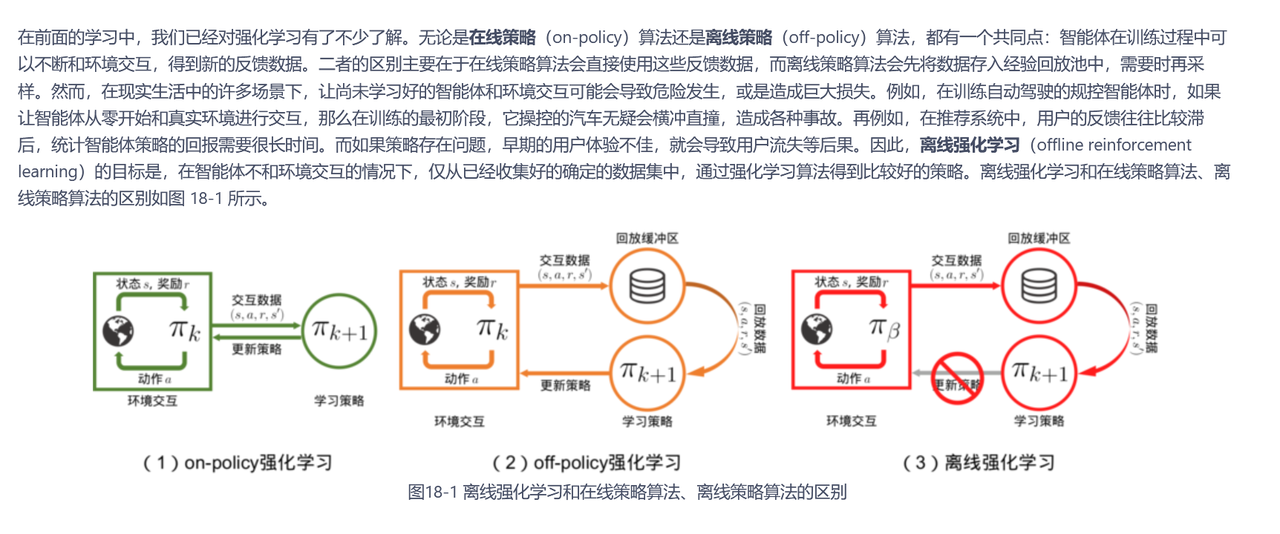
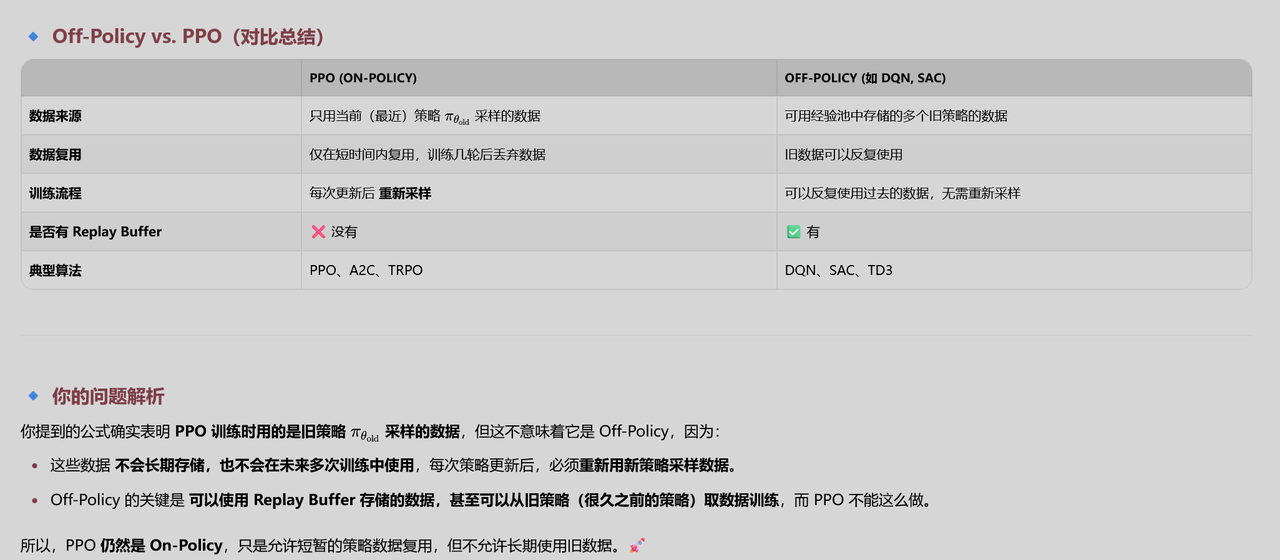
On-Policy/Off-Policy

-
On-Policy:训练过程中,需要模型亲自参与“生成”来收集新的数据样本。
-
Off-Policy:训练过程中,不需要“在线”生成,更多依赖事先收集到的(或由别的策略产生的)数据进行离线学习。


大语言模型RLHF全链路揭秘:从策略梯度、PPO、GAE到DPO的实战指南
Group Relative Policy Optimization (GRPO) Illustrated Breakdown & Explanation
DeepSeek-R1技术剖析:没有强化学习基础也能看懂的PPO & GRPO



-
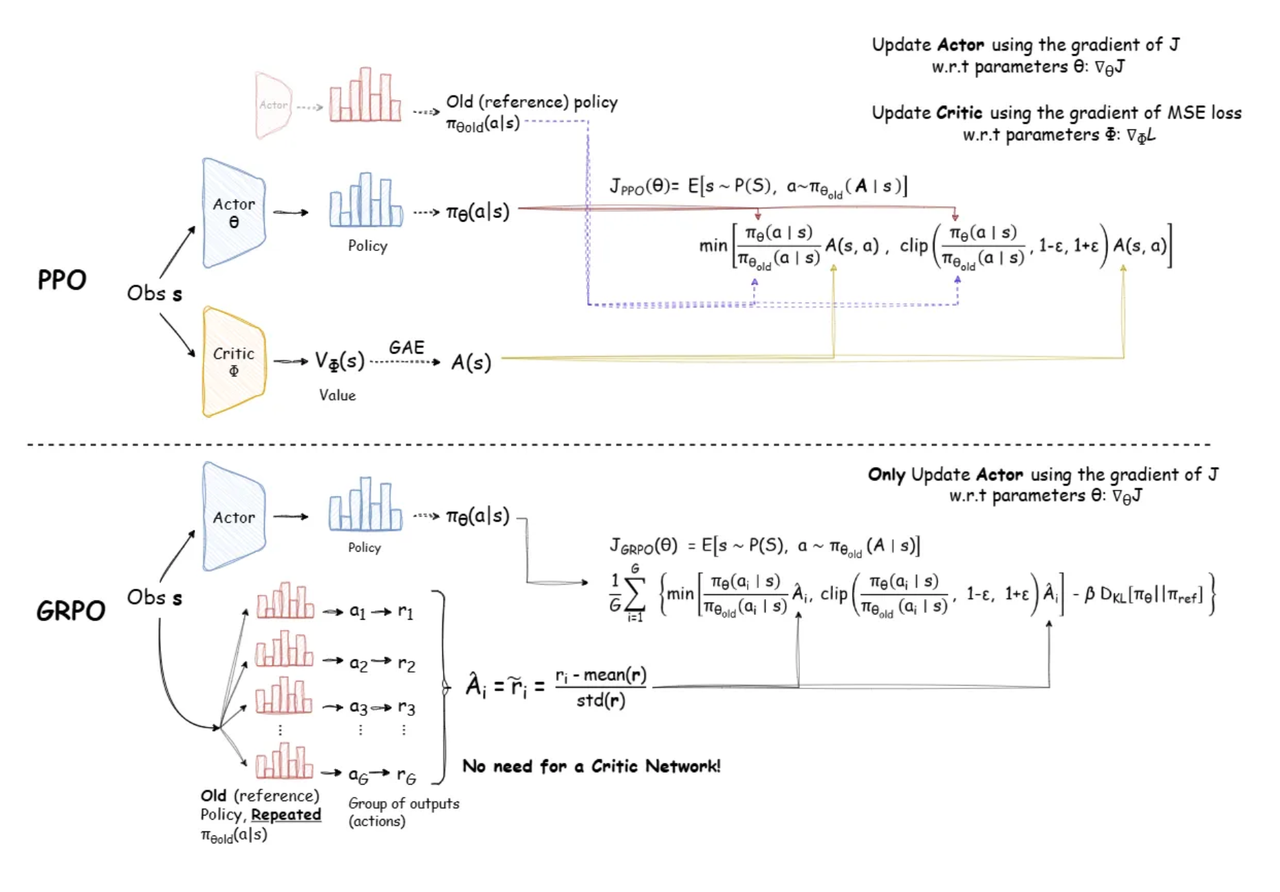
Actor 就是“我大脑里的决策机制”,不断学着如何选动作。
-
Critic 就像“我的内在预期模型”或“家长给的预期分数线”,不断修正对当前学习状态的评估。
-
最终的 Loss 把这两个部分的误差结合在一起,让二者相辅相成地共同进步。
优势
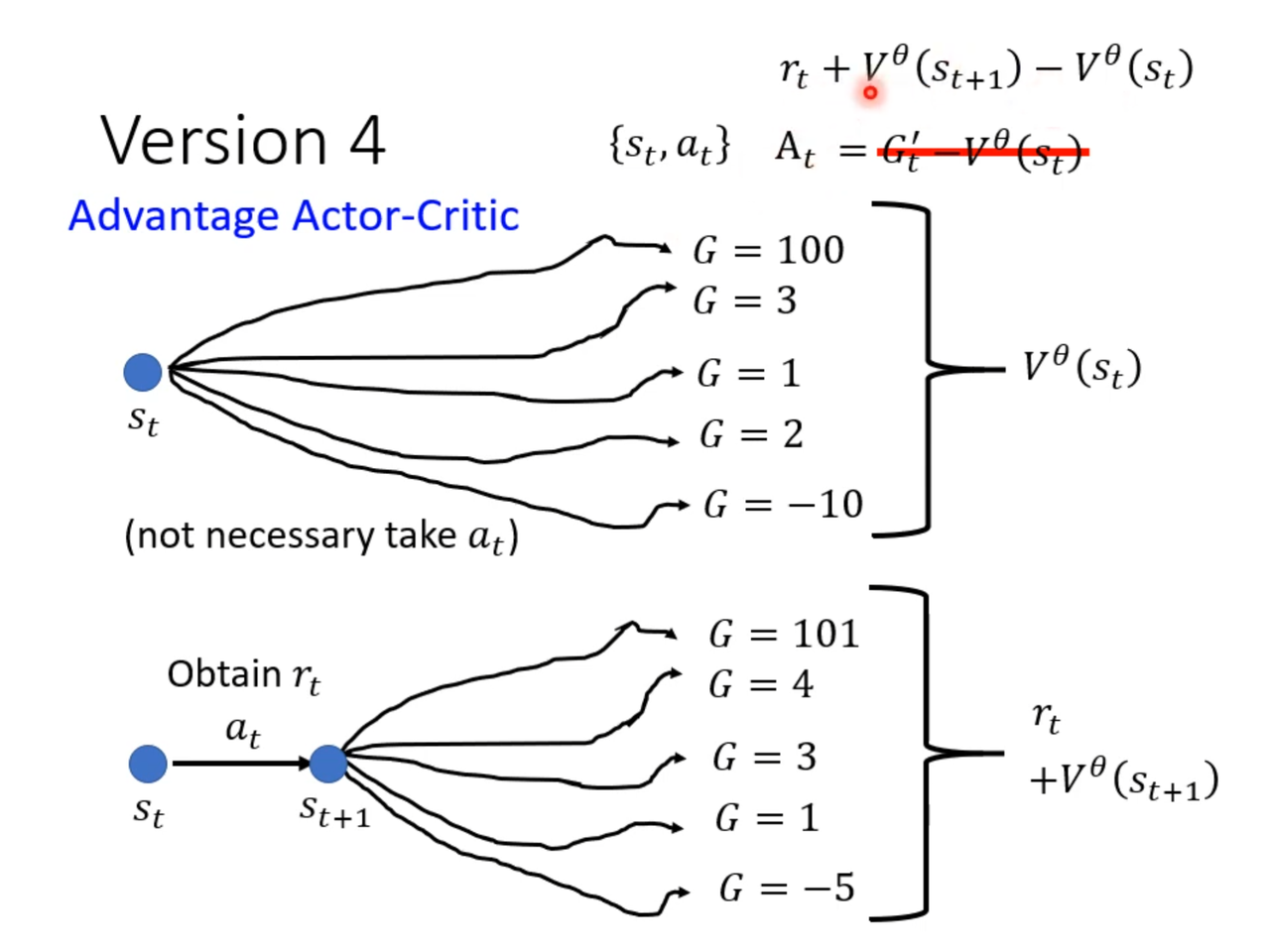
估计优势 -> 全蒙特卡洛/单步时间差分/广义优势估计
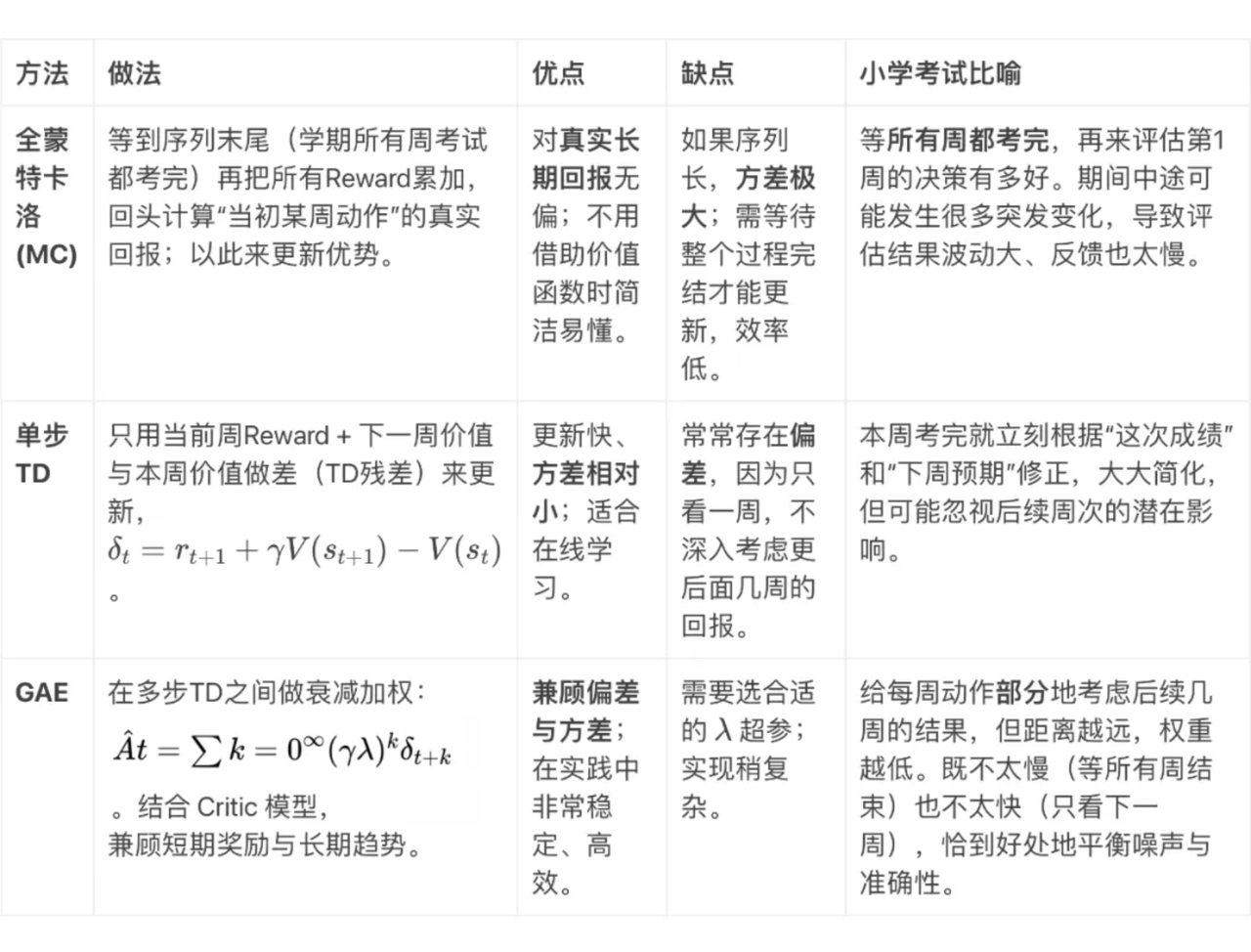
全蒙特卡洛(Monte Carlo, MC)基于完整轨迹(Episode)计算回报,直接使用�实际累积奖励作为优势估计。
TD 残差(Temporal Difference Error)就是对“本周价值估计”和“下周实际得到奖励+下周价值估计”之间的差异做一个衡量。
GAE(Generalized Advantage Estimation)就像一个“在单步 TD 与全局蒙特卡洛之间”找折衷的办法——用参数来控制“我们想考察多少步以后的反馈”。
为单步TD 为MC

-
如果我们过早地停止累加真实的奖励项:就会产生高偏差(high bias),因为只使用了对价值函数的小部分近似和极少的真实奖励。
-
如果我们累加过多的奖励项:则会引入高方差(high variance)�,因为依赖更多真实采样会让估计量不稳定。
-
为平衡这一偏差-方差问题,我们可以采用对这几项进行加权求和的做法,也就是广义优势估计(Generalized Advantage Estimation, GAE)
PPO
Zheng 等 - Secrets of RLHF in Large Language Models Part I PPO
PPO 的 Loss

PPO是ON-POLICY!!!



👆此处与GRPO进行甄别👆
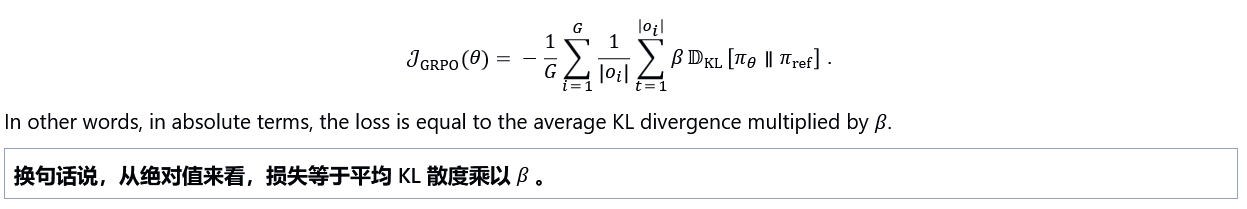
vs

DPO
DPO 的 Loss
从PPO 的 Loss 开始
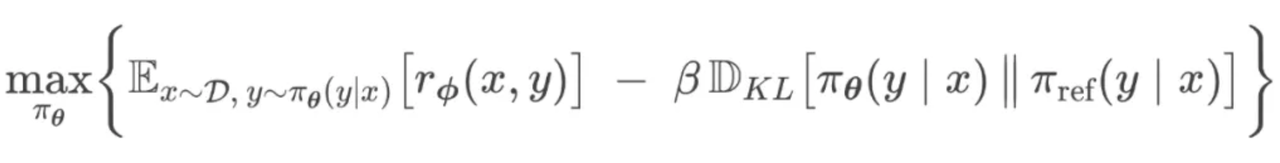
进行推导


BT模型(生成2个回答) 与 PT模型(生成个回答)
BT模型
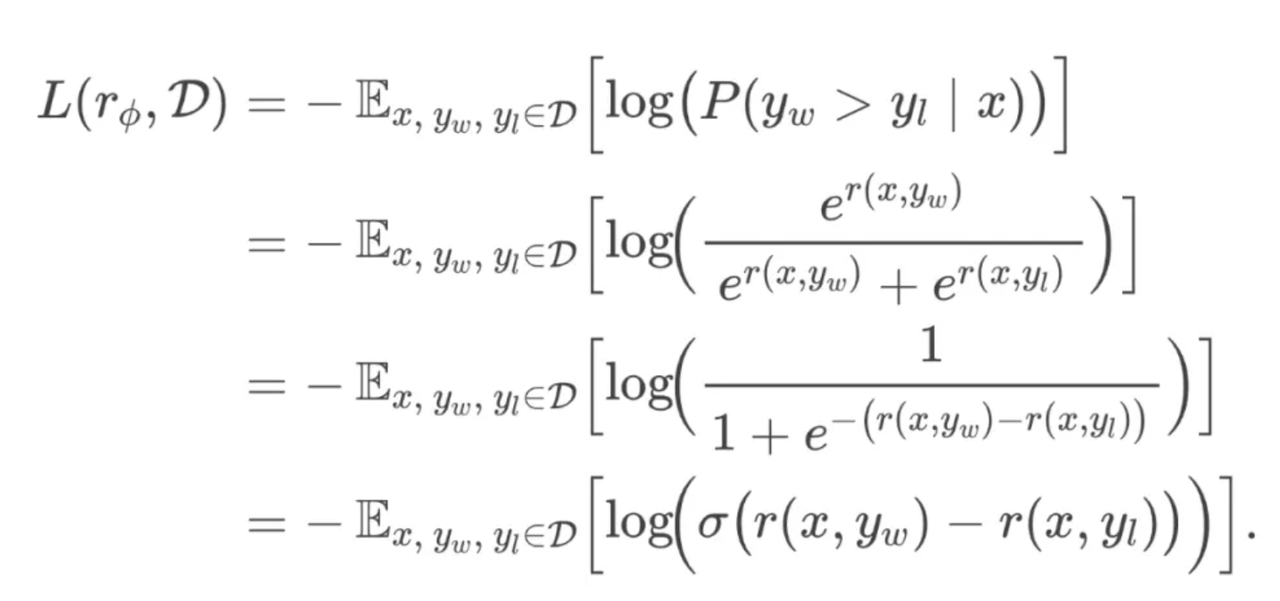
带入奖励函数
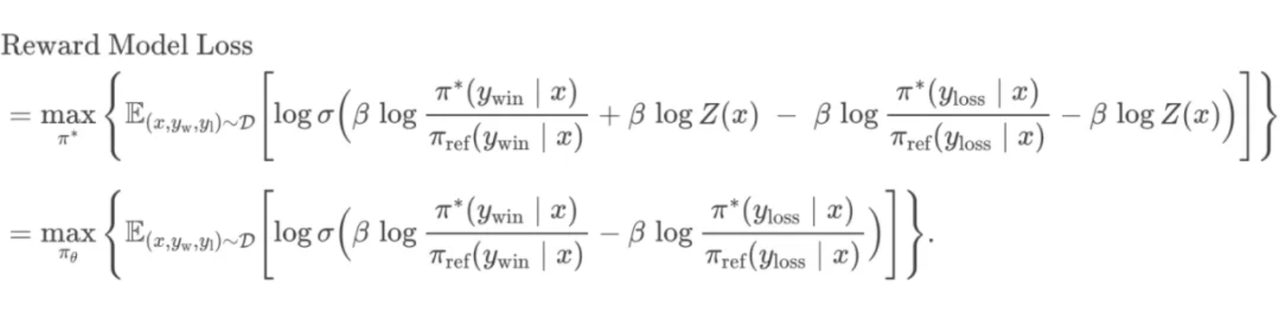
PT模型
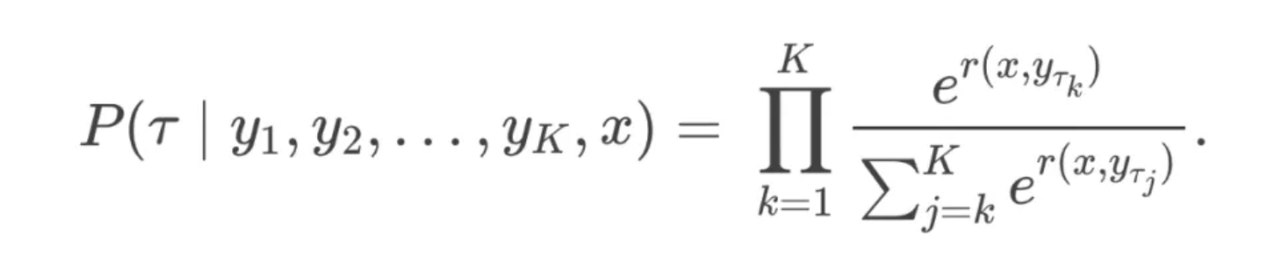
同理得
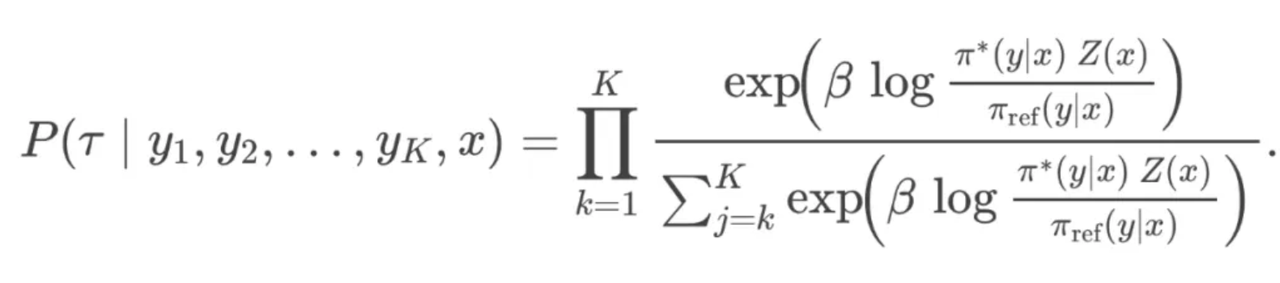
即得
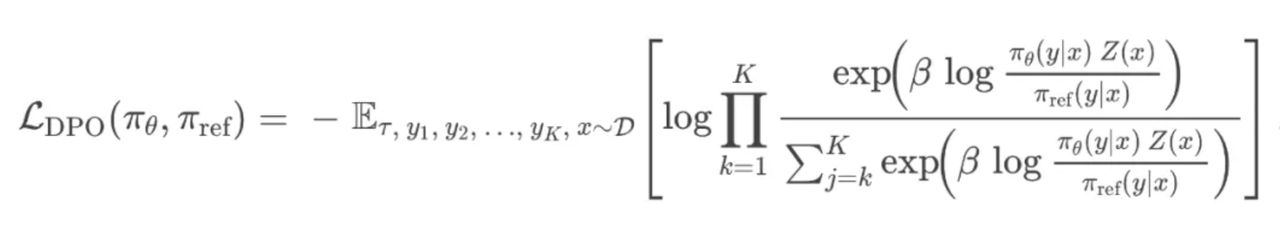
GRPO

Loss\Advantage
PPO Advantage

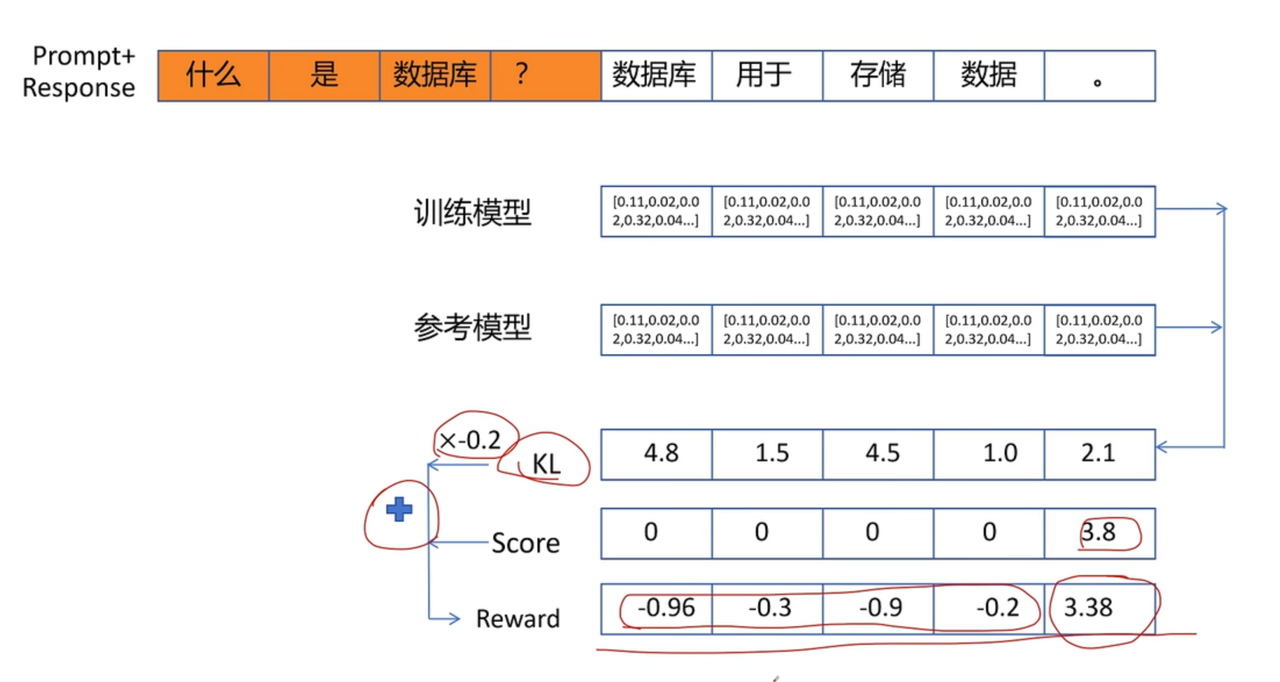
GRPO Advantage
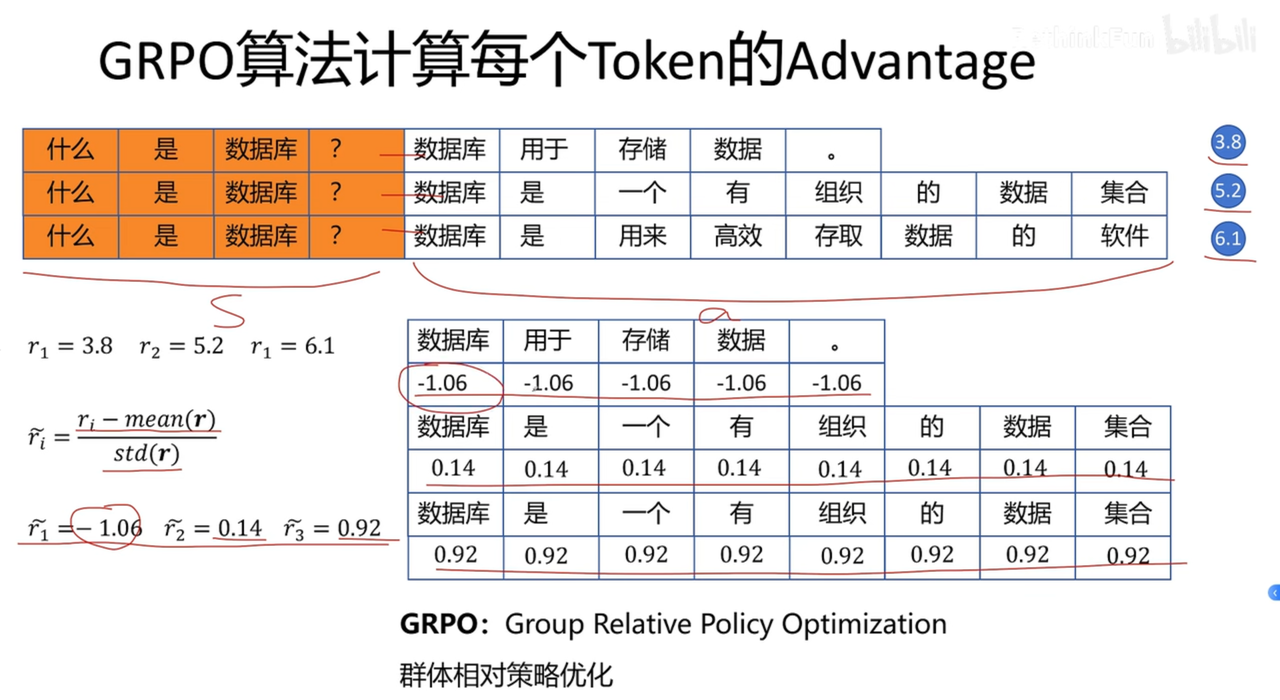



公式属于off-policy,但由于一步更新,退化为on-policy 即GRPO从始至终都是基于重要性采样的on-policy,由于单步更新,导致,即重要性采样系数为1

最终优势是output级别的,与token无关,故不依赖于t

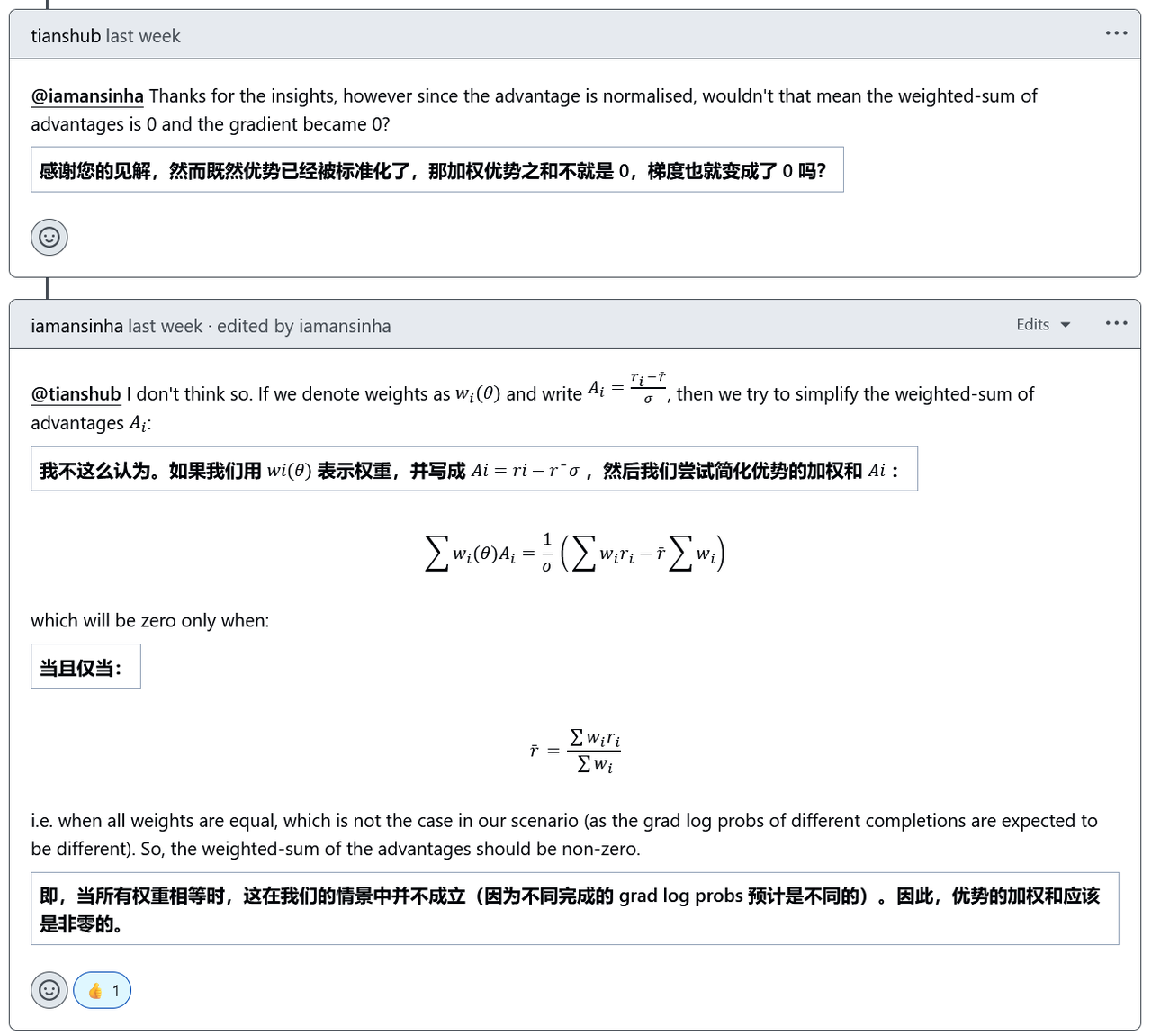
loss为0,梯度为何不为0?

算法流程

🌟DeepSeek-R1相关
LLM大模型:deepseek浅度解析(二):R1的GRPO原理 - 第七子007 - 博客园
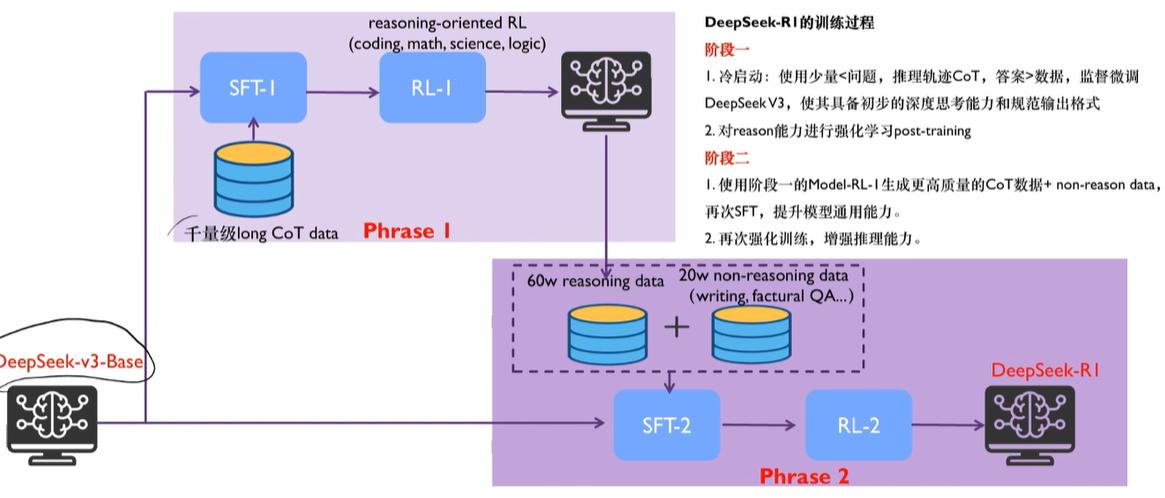
整体流程
LLM常见面试题(五十二) -- DeepSeek专题_哔哩哔哩_bilibili

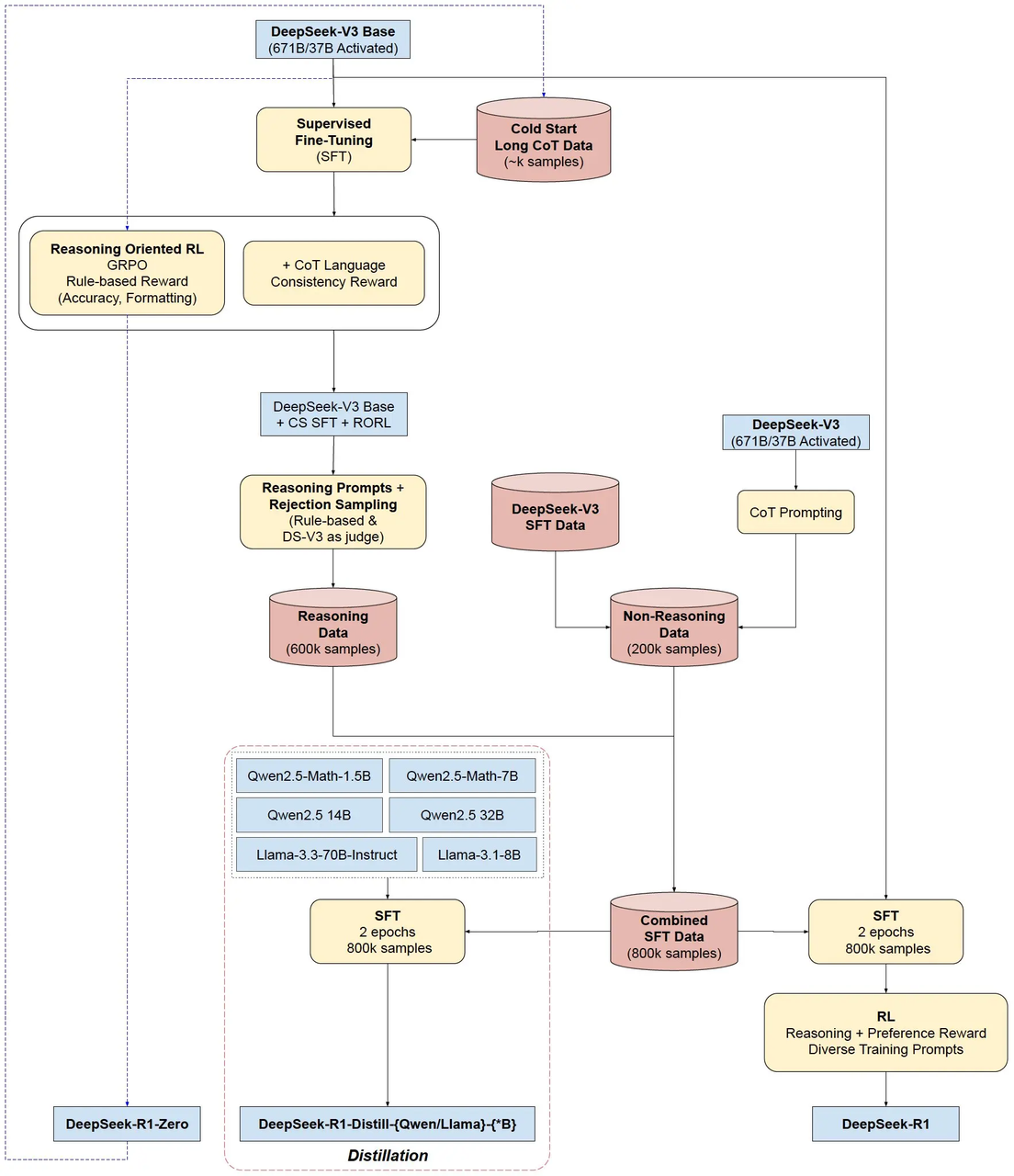
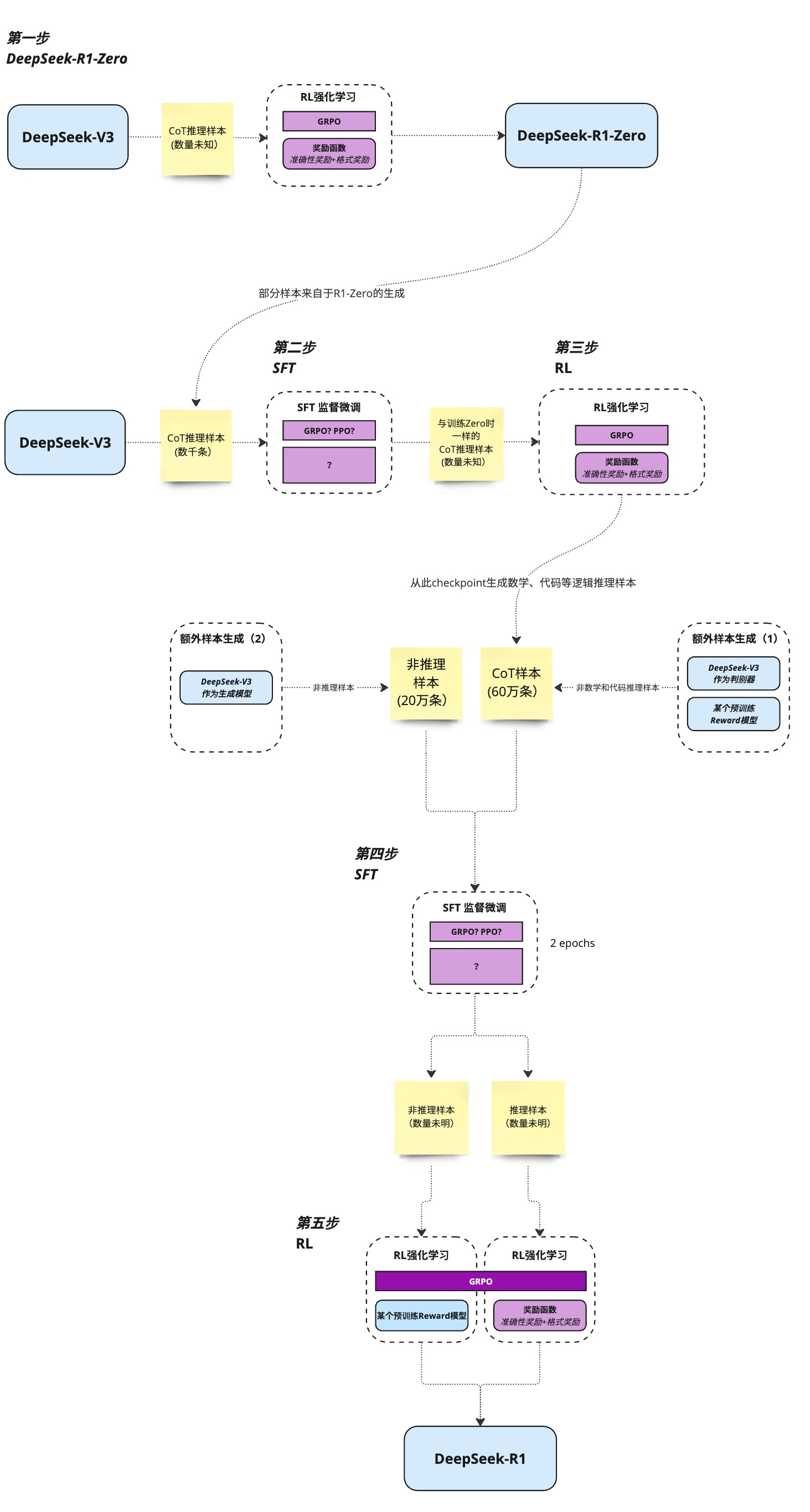
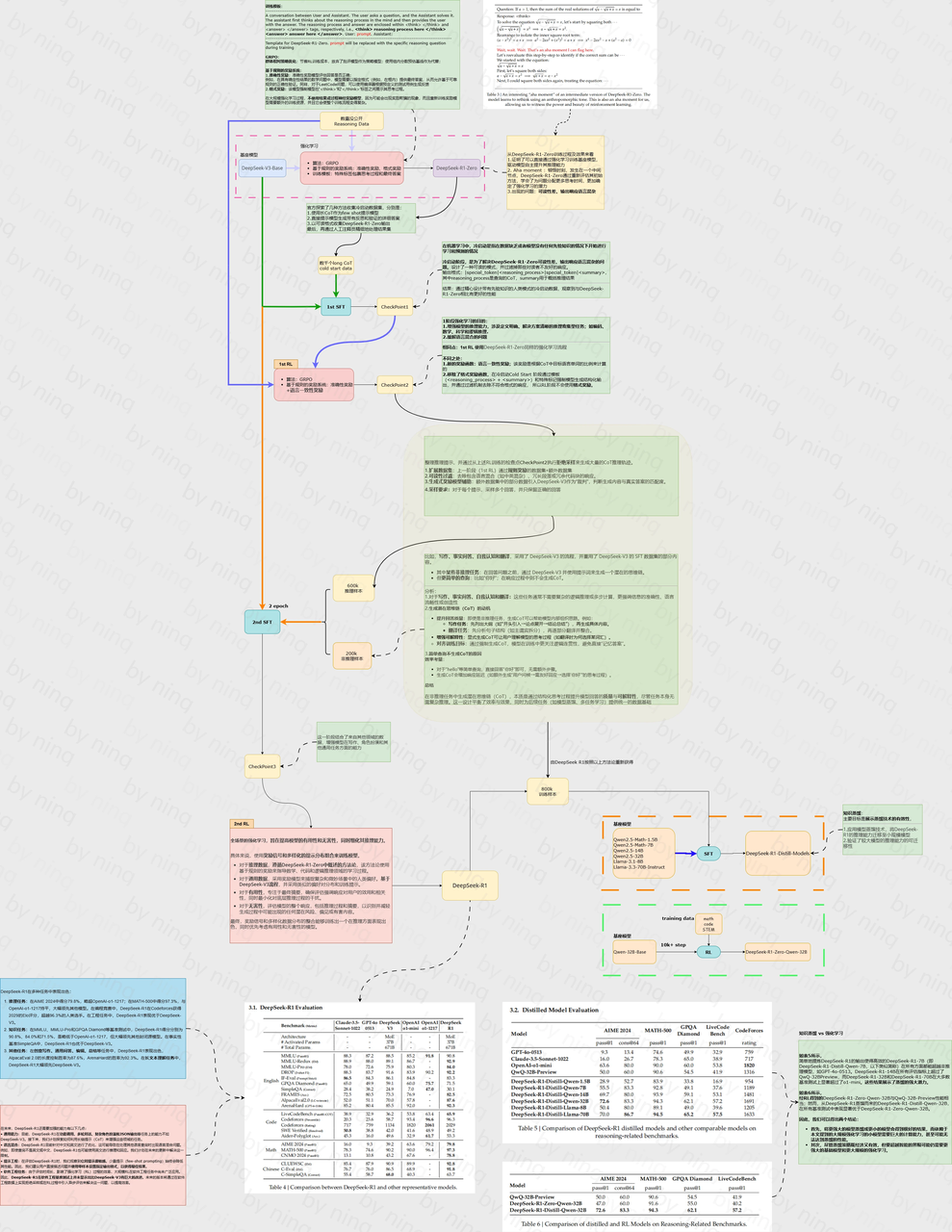
拒绝采样

Cold start dataset





Aha moment

e.g.

为何不用DPO/PPO

为何用GRPO
Advantage

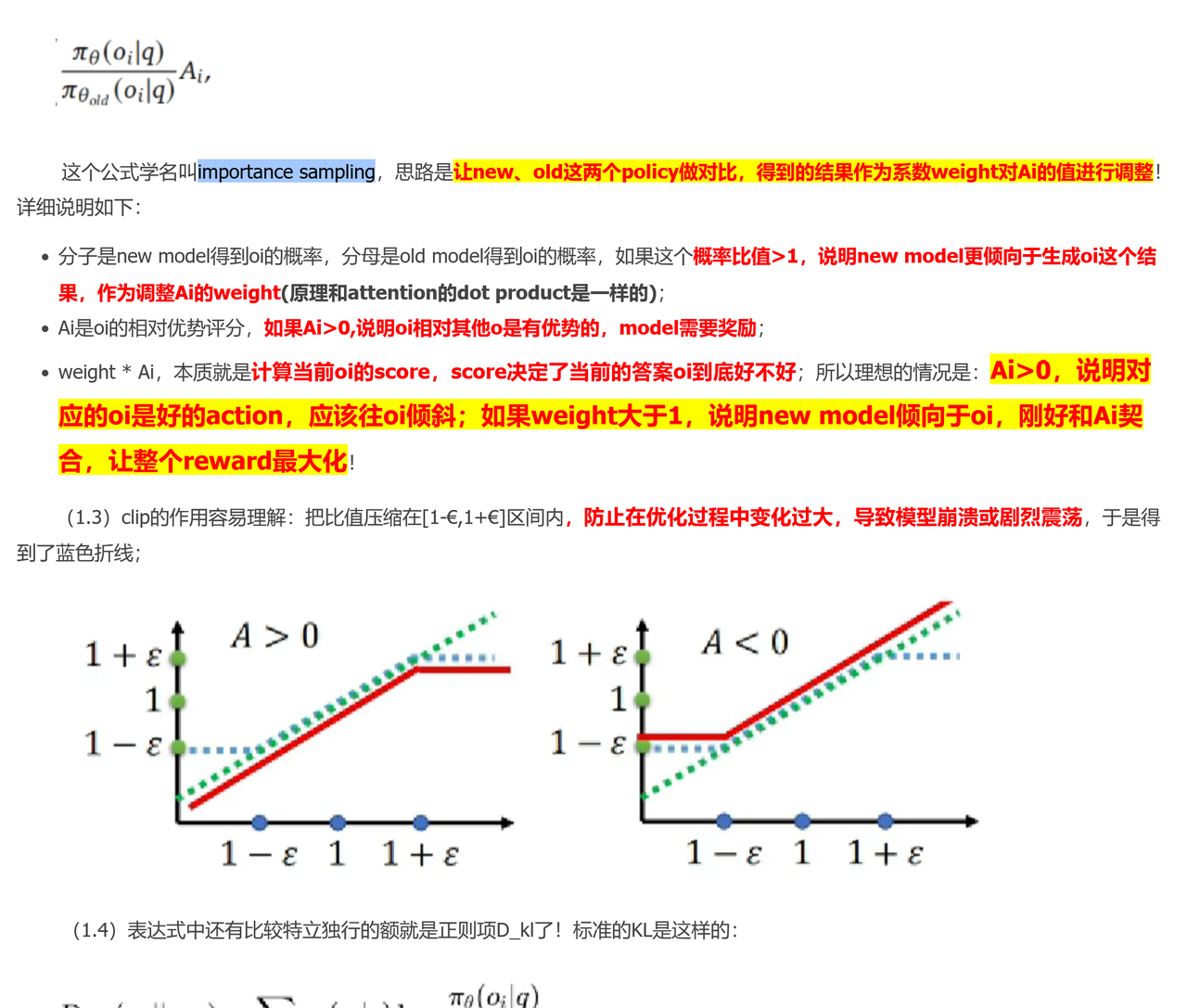
Importance Sample/Clip

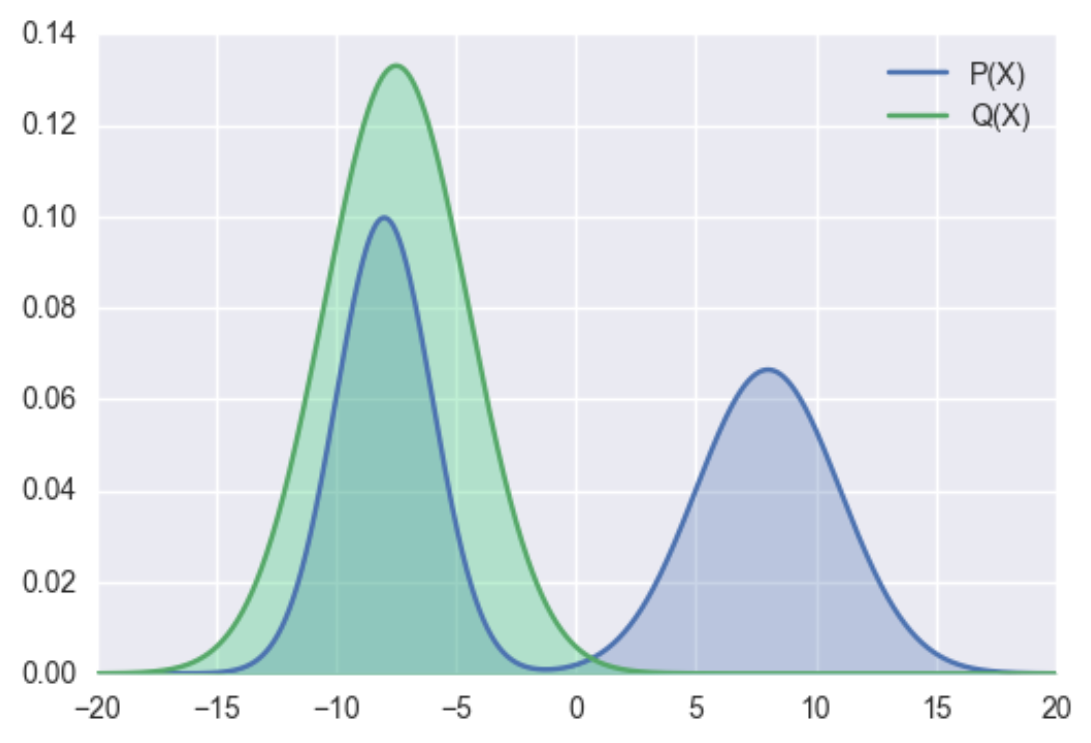
KL散度 代码见手撕
Reverse/Forward KL



Mean-Seeking/Zero-Avoiding
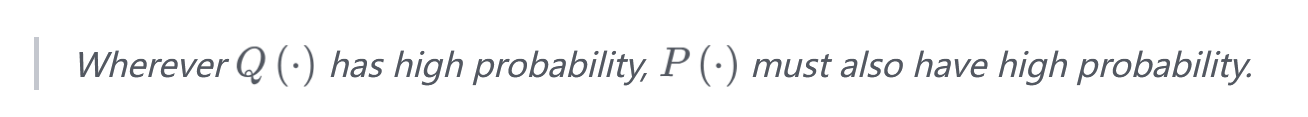
Mode-Seeking/Zero-Forcing

三种估计器



GRPO reverse K3估计器


Reward


Reward Model -> MCTS/PRM (Unsuccessful Attempts)
PRM



MCTS


Distill启发

为什么便宜

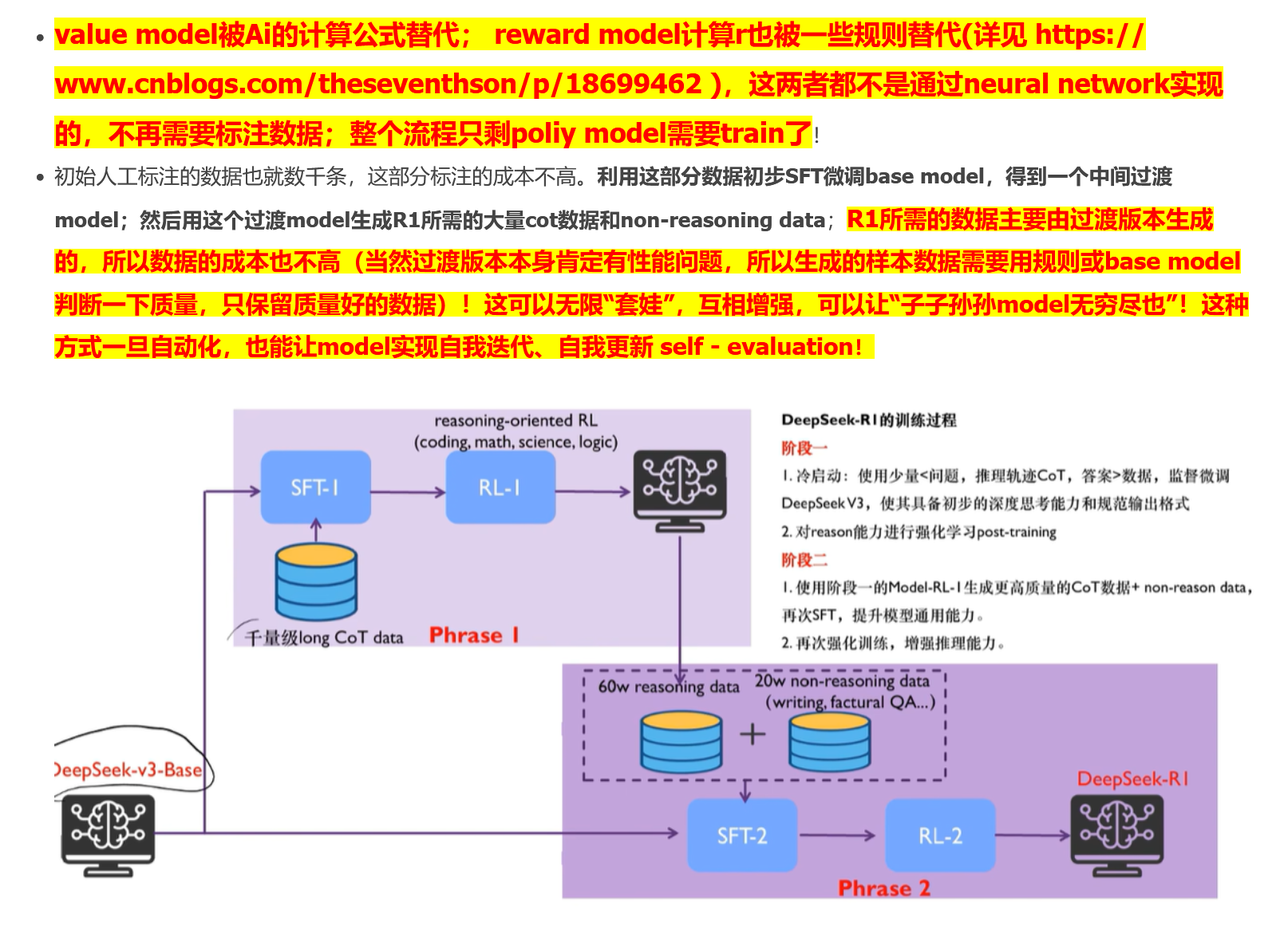
概括
