端到端目标检测 DETR、最简多模态 ViLT
DETR
前言
研究动机:端到端目标检测的意义
DETR(DEtection TRansformer)是 2020 年 5 月发布在 Arxiv 上的一篇论文,可以说是近年来目标检测领域的一个里程碑式的工作。从论文题目就可以看出,DETR 其最大创新点有两个:end-to-end(端到端)和 引入 Transformer。
目标检测任务,一直都是比图片分类复杂很多,因为需要预测出图片中物体的位置和类别。以往的主流的目标检测方法都不是端到端的目标检测,因为:
- 会加入很多的先验知识,预先生成一些锚框。比如 one-stage 方法(YOLO 系列)中的 Anchor 模板;two-stage(R-CNN 系列)中的 proposal。
- 这些方法都不是直接预测物体,而是利用 anchor/proposal 去做近似,或者像 Anchor Free 这样利用角点/中心点定位,设计一些回归/分类任务,间接出框。
- Anchor Based、Anchor Free 方法最后都会生成大大小小很多的预测框,必须在后处理时使用 NMS 去除这些冗余的框。
正是因为需要很多的人工干预、先验知识(Anchor)还有 NMS,所以整个检测框架非常复杂,难调参难优化,并且部署困难(NMS 需要的算子普通的库不一定支持,即不是所有硬件都支持)。所以说,一个端到端的目标检测是大家一直以来梦寐以求的。
简介
- DETR 如何做到 end-to-end
DETR 利用 Transformer 这种全局建模的能力,直接把目标检测视为集合预测问题(即给定一张图像,预测图像中感兴趣物体的集合)。然后使用可学习的 object query 替代了生成 anchor 的机制;使用了新的目标函数,并利用二分图匹配的方式,强制模型对每个物体生成一个预测框,从而替代了 NMS 这一步。
DETR 把之前不可学习的东西(anchor、NMS)变成可学的东西,删掉了这些依赖先验知识的部分,从而得到了一个简单有效的端到端的网络。所以 DETR 不需要费尽心思的设计 anchor,不需要 NMS 后处理,也就没有那么多超参需要调,也不需要复杂的算子。
除了端到端这一点,DETR 使用了 Transformer Encoder-Decoder 的架构。相比于原始的 Transformer,DETR 是并行预测的(in parallel),即所有预测框是一起出框的。
原始
Transformer Decoder用于自然�语言处理,为了屏蔽未来信息,使用了 masked self attention,所以是使用自回归的方式,一个接一个的顺序预测。但是目标检测任务是不需要顺序的,不存在说先得预测大物体才能预测小物体,或者说预测图片右边的物体必须依赖于图片左边的物体,所以没法做自回归预测;而且并行预测明显是更快更高效的。
-
简单架构
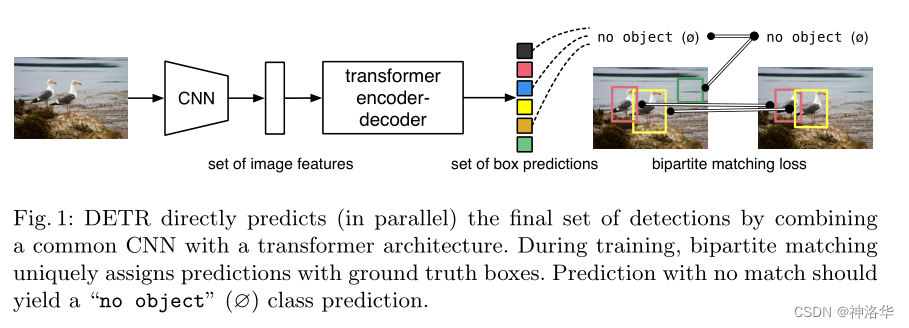
整个模型前向流程如上,训练分四个步骤:- 使用 CNN 网络提取图片特征
- 全局建模:图片特征拉成一维,输入
Transformer Encoder中进行全局建模,进一步通过自注意力学习全局特征。
之所以使用Transformer Encoder,是因为 Transformer 中的自注意力机制,使得图片中的每个点(特征)都能和图片中所有其他特征做交互了,这样模型就能大致知道哪块区域是一个物体,哪块区域又是另一个物体,从而能够尽量保证每个物体只出一个预测框。所以说这种全局特征非常有利于移除冗余的框。 - 通过
Transformer Decoder生成 N 个预测框 set of box prediction(默认取 N = 100,也就是一张图固定生成 100 个预测框)。 - 计算二分图匹配损失(bipartite matching loss),选出最优预测框,然后计算最优框的损失。
计算 N 个预测框与所有 GT box(真实框)的 matching loss,然后通过二分图匹配算法来选出与每个物体最匹配的预测框。比如上图中有两个物体,那么最后只有两个框和它们是最匹配的,归为前景;剩下 98 个都被标记为背景(no object)。最后和之前的目标检测算法一样,计算这两个框的�分类损失和回归损失。
推理时,前三步是一样的。通过 decoder 生成 N 个预测框后,设置一个置信度阈值进行过滤,得到最终的预测框。(比如设阈值 = 0.7,表示只输出置信度大于 0.7 的预测框,剩下都当做背景框)
总的来说,
Transformer Encoder全局建模,用于区分物体;Transformer Decoder用于描绘物体边界,将物体位置补充的更完整(见 4.2 可视化)。 -
性能 在摘要中,作者卖了一下 DETR 的优点:
-
简单性:不仅框架简单,可以进行端到端的检测,而且只要硬件支持 CNN 和 Transformer 就一定可以支持 DETR。
-
在 COCO 数据集上的性能,和一个 训练好的 Faster R-CNN baseline 是差不多的,无论从内存、速度还是精度来说。
-
迁移性好:DETR 框架可以很容易的拓展到其它任务上,比如在全景分割上的效果就很好(加个分割头就行)。
局限性:
-
DETR 对大物体检测效果不错,但是对小物体的检测效果不好(见实验 4.1)。
前者归功于 transformer 可以进行全局建模,这样无论多大的物体都可以检测,而不像 anchor based 方法检测大物体时会受限于 anchor 的尺寸。后者是因为作者只是使用了一个简单的结构,很多目标检测的针对性设计还没有使用,比如多尺度特征、针对性的检测头。 -
训练太慢。
为了达到好的效果,作者在 COCO 上训练了 500epoch,而一般模型训练几十个 epoch 就行了。
-
-
改进
DETR 精度只有 44 AP,比当时 SOTA 模型差了近 10 个点,但是想法特别好,解决了目标检测里面的很多痛点,所以影响还是很大的。而且其本身只是一个简单的模型,还有很多可以改进的。比如 半年后提出的 Deformable-DETR, 融入了多尺度特征,成功解决小物体检测效果不好的问题,还解决了训练慢的问题。
另外 DETR 不仅是一个目标检测方法,还是一个拓展性很强的框架。其设计理论,就是适用于更多复杂的任务,使其更加的简单,甚至是使用一个框架解决所有问题。后续确实有一系列基于它的改进工作,比如 Omni-DETR, up-DETR, PnP-DETR, SMAC-DETR, DAB-DETR, SAM-DETR, DN-DETR, OW-DETR, OV-DETR 等等,将 DETR 应用在了目标追踪、视频领域的姿态预测、语义分割等多个视觉任务上。(感觉类似 CLIP 出来之后,有一系列基于它的工作)
相关工作
这一块介绍了三部分:
- 介绍之前的集合预测工作
- 如何使用 Parallel Decoding 让 transformer 可以并行预测
- 目标检测
- 集合预测:以前也有集合预测这一类的方法,也做了二分图匹配,也可以做到每个物体只得到一个预测框,而不需要 NMS。但是这些方法性能低,要不就是为了提高性能加了很多人工干预,显得复杂。
- encoder-decoder:以前也有用 encoder-decoder 做检测,但都是 17 年以前的工作,用的是 RNN 的结构,效果和性能都不好(RNN 自回归,效率慢)。
所以对比以前的工作发现,能让 DETR 工作的好最主要的原因就是使用了 Transformer。比如上面两点,都是 backbone 学的特征不够好,才需要使用很多人工干预,或者说模型效果性能都不好。 所以说 DETR 的成功,还是 Transformer 的成功。
算法
目标函数
DETR 模型每次输出固定个数(N = 100)的预测框,如何判断哪个预测框匹配哪个 GT box 呢?这就涉及到二分图匹配算法。
假设现在有 3 个工人和 4 个任务,由于每个工人的特长不一样,他们完成不同任务的时间(成本)也是不一样的,那如何分配任务能够使总的成本最低呢?最直接的最暴力的方法,就是用直接遍历,找出各种排列组合中的最优组合,但这样的复杂度无疑是很高的。匈牙利算法是解决该问题的一个知名且高效的算法,能够以较低的复杂度得到唯一的最优解。
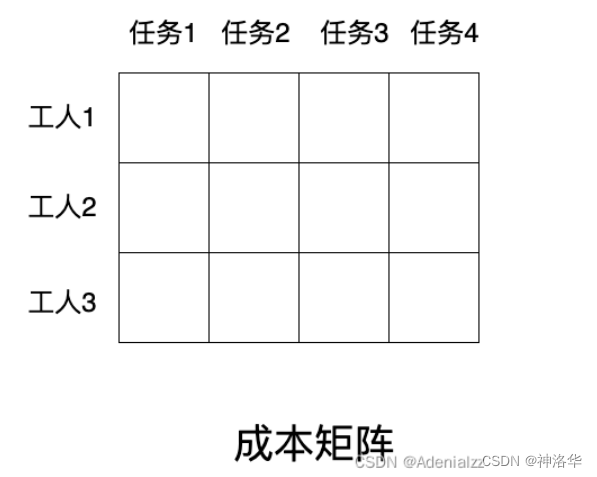
在 scipy 库中,已经封装好了匈牙利算法,只需要将成本矩阵(cost matrix)输入进去就能够得到最优的排列。在 DETR 的官方代码中,也是调用的这个函数进行匹配(from scipy.optimize import linear_sum_assignment)。
从 N 个预测框中,选出与 M 个 GT Box 最匹配的预测框,也可以转化为二分图匹配问题,这里需要填入矩阵的“成本”,就是每个预测框和 GT Box 的损失。对于目标检测问题,损失就是分类损失和边框损失组成。即:
所以整个步骤就是:
- 遍历所有的预测框和 GT Box,计算其 loss。
- 将 loss 构建为 cost matrix,然后用 scipy 的
linear_sum_assignment(匈牙利算法)求出最优解,即找到每个 GT Box 最匹配的那个预测框。 - 计算最优的预测框和 GT Box 的损失。常规目标检测算法损失为:(分类+回归)
但是在 DETR 中,损失函数有两点小改动:
- 去掉分类损失中的 log
对于前一项分类损失,通常目标检测方法计算损失时是需要加 log 的,但是 DETR 中为了保证两部分损失的数值区间接近,便于优化,选择了去掉 了 log; - 回归损失为 L1 loss+GIOU
对于后一项回归损失,通常方法只计算一个L1 loss(预测框和真实框坐标的 L1 损失)。但是 L1 loss 和预测框的大小有关,框越大损失越大。 DETR 中,用 Transformer 提取的全局特征对大物体比较友好,经常出一些大框,这样就不利于优化,因此作者这里还添加了一个GIoU Loss。
其实这里使用匈牙利算法找最优匹配,和之前使用 anchor/proposal 这种先验知识来匹配预测框和真实框是差不多的,只不过这里的约束更强,也就是强制模型对每个物体只输出一个预测框。
关于
GIOU Loss,可以参考帖子 《YOLOv1——YOLOX 系列及 FCOS 目标检测算法详解》 4.3 章节CIoU Loss,其中详细介绍了回归损失使用 L1 loss、IoU Loss、GIoU Loss 和 CIoU Loss 的优劣。
模型结构
作者在这部分给出了模型更详细的框架,如下图所示:
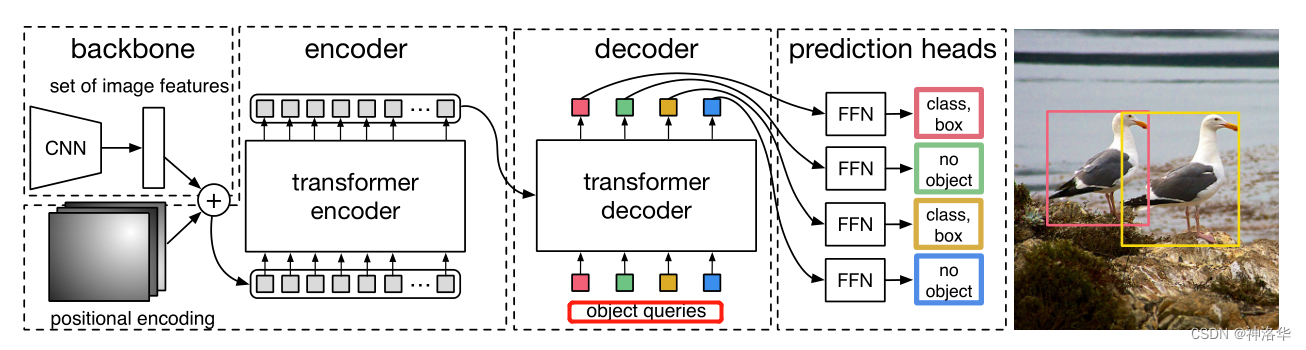
下面参考官网的一个 demo,以输入尺寸 3×800×1066 为例进行前向过程:
- CNN 提取特征(
[800,1066,3]→[25,34,256])
backbone 为 ResNet-50,最后一个 stage 输出特征图为 25×34×2048(32 倍下采样),然后用 1×1 的卷积将通道数降为 256; Transformer encoder计算自注意力([25,34,256]→[850,256])
将上一步的特征拉直为 850×256,并加上同样维度的位置编码(Transformer 本身没有位置信息),然后输入的 Transformer encoder 进行自注意力计算,最终输出维度还是 850×256;Transformer decoder解码,生成预测框
decoder 输入除了 encoder 部分最终输出的图像特征,还有前面提到的learned object query,其维度为 100×256。在解码时,learned object query和全局图像特征不停地做across attention,最终输出 100×256 的自注意力结果。
这里的object query即相当于之前的 anchor/proposal,是一个硬性��条件,告诉模型最后只得到 100 个输出。然后用这 100 个输出接 FFN 得到分类损失和回归损失。- 使用检测头输出预测框
检测头就是目标检测中常用的全连接层(FFN),输出 100 个预测框( )和对应的类别。 - 使用二分图匹配方式输出最终的预测框,然后计算预测框和真实框的损失,梯度回传,更新网络。
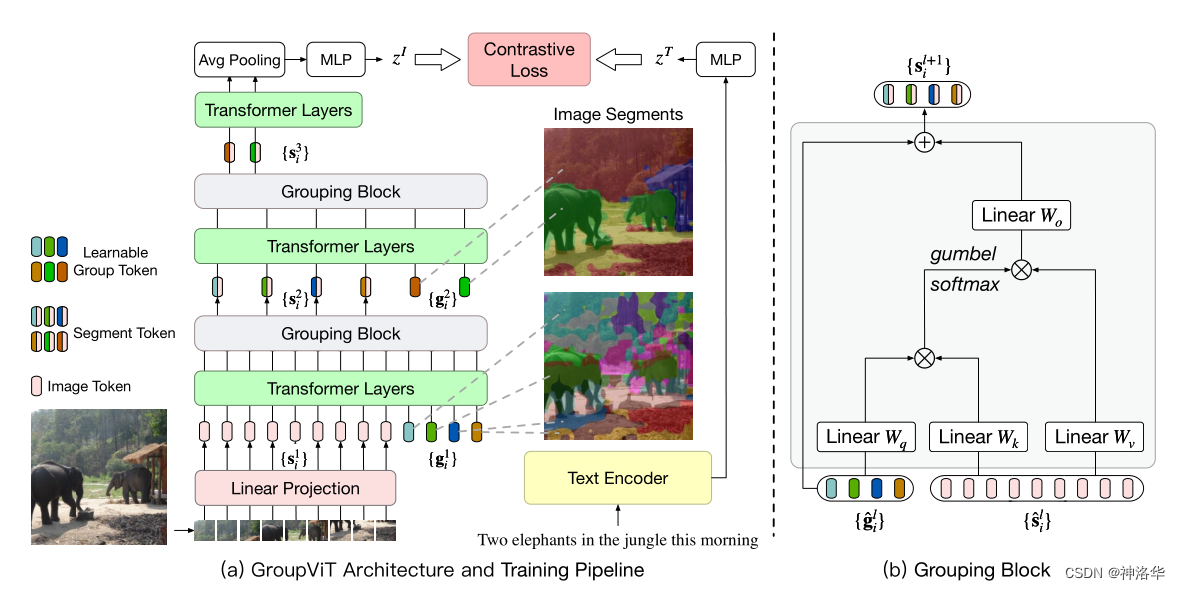
object query准确来说是learned positional embedding,我感觉有点就类似 Group ViT 中的 grouping 操作。简单说如果有一些聚类的中心点,从这些中心点开始发散,把周围相似的点逐渐扩散成一个 group。Group ViT 使用计算单元 Grouping Block,将可学习的 Group Tokens 一点点的 group 起来,最终变成物体掩模(segmentation mask)。Group ViT 结构如下图所示:
ViT 的 Linear Projection 层将图片分割成 patch 然后映射为
Pacth embeddings,即图中 token (维度 196×384),然后和learned group token一起输入 Transformer Layer。学习 6 层之后使用 Grouping Block 模块,将图像块 token 分配到各个 group token 上,合并成为更大的、更具有高层语义信息的 group,即 Segment Token(维度 64×384,相当于一次聚类的分配)。 * 重复上述过程:添加新的 Group tokens (8×384),经过 3 层 Transformer Layers 的学习之后,再次经过 grouping block 分配,得到 (8×384) 。
除此之外还有部分细节:
- Transformer-encode/decoder 都有 6 层
- 除第一层外,每层 Transformer encoder 里都会先计算 object query 的 self-attention,主要是为了移除冗余框。这些 query 交互之后,大概就知道每个 query 会出哪种框,互相之间不会再重复(见实验)。
- decoder 加了 auxiliary loss,即每层 decoder 输出的 100×256 维的结果,都加了 FFN 得到输出,然后去计算 loss,这样模型收敛更快。(每层 FFN 共享参数)
伪代码
下面是论文中给出的简化代码,可以直接跑,只是精度会差两个点。
import torch
from torch import nn
from torchvision.models import resnet50
class DETR(nn.Module):
def __init__(self, num_classes, hidden_dim, nheads,
num_encoder_layers, num_decoder_layers):
super().__init__()
# We take only convolutional layers from ResNet-50 model
self.backbone = nn.Sequential(*list(resnet50(pretrained=True).children())[:-2])
self.conv = nn.Conv2d(2048, hidden_dim, 1) # 1×1卷积层将2048维特征降到256维
self.transformer = nn.Transformer(hidden_dim, nheads, num_encoder_layers, num_decoder_layers)
self.linear_class = nn.Linear(hidden_dim, num_classes + 1) # 类别FFN
self.linear_bbox = nn.Linear(hidden_dim, 4) # 回归FFN
self.query_pos = nn.Parameter(torch.rand(100, hidden_dim)) # object query
# 下面两个是位置编码
self.row_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
self.col_embed = nn.Parameter(torch.rand(50, hidden_dim // 2))
def forward(self, inputs):
x = self.backbone(inputs)
h = self.conv(x)
H, W = h.shape[-2:]
pos = torch.cat([self.col_embed[:W].unsqueeze(0).repeat(H, 1, 1),
self.row_embed[:H].unsqueeze(1).repeat(1, W, 1),
], dim=-1).flatten(0, 1).unsqueeze(1) # 位置编码
h = self.transformer(pos + h.flatten(2).permute(2, 0, 1),self.query_pos.unsqueeze(1))
return self.linear_class(h), self.linear_bbox(h).sigmoid()
detr = DETR(num_classes=91, hidden_dim=256, nheads=8, num_encoder_layers=6, num_decoder_layers=6)
detr.eval()
inputs = torch.randn(1, 3, 800, 1200)
logits, bboxes = detr(inputs)
实验
对比 Faster RCNN
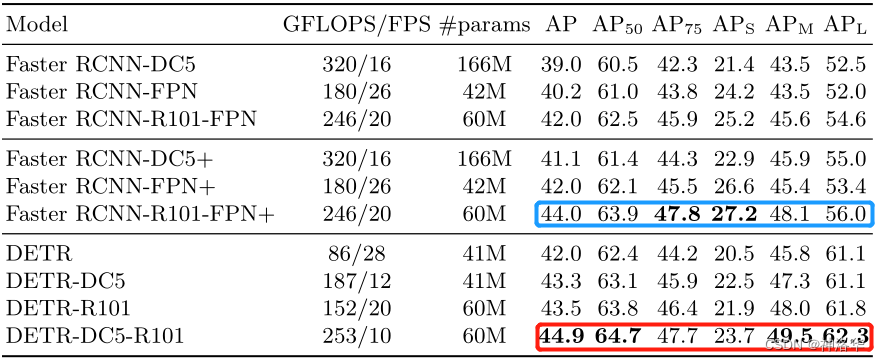
-
最上面一部分是 Detectron2 实现的 Faster RCNN ,但是本文中作者使用了很多 trick
-
中间部分是作者使用了 GIoU loss、更强的数据增强策略、更长的训练时间来把上面三个模型重新训练了一次,这样更显公平。重新训练的模型以+表示,参数量等这些是一样的,但是普偏提了两个点
-
下面部分是 DETR 模型,可以看到参数量、GFLOPS 更小,但是推理更慢。模型比 Faster RCNN 精度高一点,主要是大物体检测提升 6 个点 AP,小物体相比降低了 4 个点左右
-
参数量、计算量和推理速度之间并没有必然的关系
-
transformer encoder/decoder 层数消融试验,结果是层数越多效果越好,但是考虑到计算量,作者最后选择 6 层。
可视化
- 编码器自注意力图可视化
下图展示了对于一组基准点(图中红点)的 Encoder 注意力热力图的可视化,即基准点与图像中所有其他点的自注意力分�布。
可以观察到,Transformer Encoder 的自注意力已经做得非常好了, 基本能够非常清晰地区分开各个物体,甚至已经有一点实例分割的 mask 图的意思了。而且在严重遮挡的情况下,也能够清楚地区分左侧的两头牛。
所以 Transformer Encoder 的作用,正是可以把图片中的物体清楚地区分开,再在这个基础上做分割或者检测就会简单很多,效果也更好。

2. 解码器注意力图可视化
通过前面的可视化,我们已经看到 Encoder 学习的全局特征,基本已经能够区分开图中不同的物体。但是对于目标检测来说,大致地区分开不同的物体是不够的,我们还需要物体边界框的精确坐标,这部分就由 Decoder 来做。
下图是 将 Decoder 自注意力用不同的颜色可视化出来 ,比如左图中的两头大象分别由蓝色和橙色表示。右侧斑马也用三个颜色表示。
可以观察到,即使在严重遮挡的情况下,每个物体边界的注意力还能区分开来,如大象尾巴、象腿等处。而且两头象的皮肤还有斑马上的花纹都差不多,但是轮廓都分的很清楚。作者认为这是 Decoder 在区分不同物体边界的极值点(extremities),在 Encoder 能够区分开不同的物体之后,Decoder 就只需要关注物体的边界位置,解决遮挡这些问题,最终精准地预测出不同物体的边框位置。因此,Encoder-Decoder 的结构是必要的(类似 U-Net)。

3. object query 的可视化
下图将 COCO2017 ��验证集中所有图片的预测框可视化了出来,在 N = 100 个预测框中只取了 20 个。下图每一个框代表一个 object query,并且每张图都根据其尺寸进行了归一化(相当于每张图都除以高宽,得到 1×1 大小)。
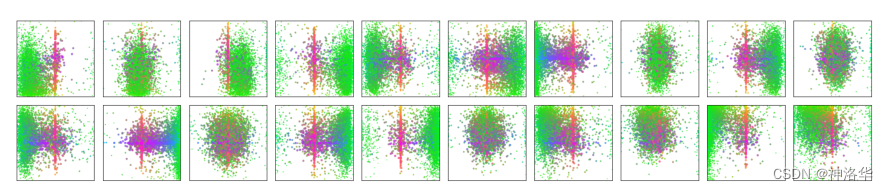
- 这些点用不同颜色进行区分,绿色表示小的 bounding box,蓝色表示大的纵向 box,红色表示大的横向 box。
- 不同 query 负责检测不同的物体
从上面可以看出,不同的 query 负责检测不同位置不同大小的物体。比如上图第一个 query,就是负责检测图片左侧靠下部分的小物体,中心部分的大物体,其它以此类推,遍历 100 个 query 后,图片中存在这个物体的就返回预测框。 - 对比 anchor
query 也类似 anchor,都是检测图片中某个部位有没有某种物体。只不过 anchor 需要先验地手动设置,而 query 是与网络一起端到端学习的。 - COCO 数据集中心都有大物体
上图还可以看到,每张图中心都有红色的竖线,表示每个 query 都会检测图片中心是否有横向的大物体。这是因为 COCO 数据集图片中心往往都有一个大的物体,query 则学到了这个模式,或者说分布。
ViLT
- 论文 《ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision》、代码
- 李沐 《ViLT 论文精读》、帖子 《2021: ViLT》、知乎 《ViLT:最简单的多模态 Transformer》
- ViLT 是直接在 ViT 的基础上改进的
前言
天下苦目标检测久矣!!!
DETR 一经出世就广受热捧,因为它可以进行端到端的目标检测,使得目标检测的框架和流程都大大简化;另外引入 Transformer 之后,整个检测性能也不错,所以推动着整个目标检测工作都往这个方向走。
ViLT 也是一个极其简单的视觉文本多模态的框架,其最主要贡献,就是把多模态学习框架中的目标检测,也就是论文中反复强调的 Region Feature(区域性特征)直接拿掉了。这个操作简直是大快人心,因为它极大地简化了视觉模态特征的抽取过程,大大提高了模型的推理速度,可称之为多模态领域一个里程碑式的工作。
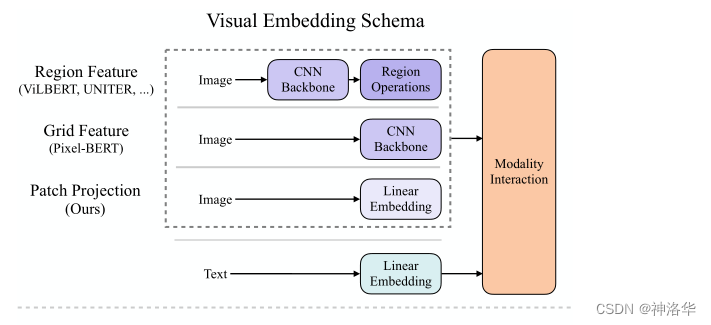
- 抽取视觉特征的三种方式
现有的 VLP 模型(Vision-and-Language Pre-training,视觉文本多模态模型)抽取文本特征基本上都使用 pre-trained BERT 的 tokenizer 来得到 text embedding,但抽取视觉特征存在着差异。往往处理视觉特征的网络越复杂,模型效果就越好,所以抽取视觉特征是现有 VLP 模型的瓶颈。图下图所示,获取 visual embedding 的方法总共有三大类:
-
Region Feature:通常采用 Faster R-CNN 二阶段检测器提取区域性特征,这种操作也是最贵的;比如图像经过 ResNet101 backbone 提取特征,再经过 RPN 得到一些 RoI,然后使用 NMS 过滤冗余的 RoI,最后经过 RoI Head 得到一些一维的向量(Region Feature),也就是一个个 bounding box。
-
grid feature:将 CNN backbone 得到的 feature map,作为网格特征,大大简化了计算量比如将 ResNet50 最后得到的 7×7 特征图拉直为一个序列,或者是上一层的 14×14 的特征图
-
patch projection:使用类似 ViT 模型中的patch projection层直接得到 patch embeddings,ViLT 是首个这么做的,有三个原因:- 不需要使用额外的网络,无论是 CNN backbone 还是目标检测,都非常贵。
- 不需要缓存特征。前两种方法都需要在线下使用预训练的模型提前抽取好图片特征,然后再训练。虽然这样训练还是比较轻量的,但在部署的时候是一个很大的局限性。真实场景里每时每刻都在生成新数据,都需要抽取新数据的特征,这时推理速度就是一大瓶颈了,所以作者才想设计一个更轻量更简单的视觉特征抽取方案。
- ViT 的
patch projection层表现很好。在ViT论文中,其作者对比了使用 CNN backbone 先抽特征再使用 patch projection 层(ViT Hybrid 混合模型)和直接使用 patch projection 层(ViT)两种将图片映射成patch embedding的方式,发现最终结果差不多,可见只用patch projection层模型也能工作的很好。受此启发, 作者直接将 ViT 的patch projection层拿过来用,替代之前的提取网络!
这三种方法都是将抽取到的visual embedding当做一个序列,和同样长度的text embedding序列一起输入 Transformer 做后续的特征融合,其性能和运行时间如下:
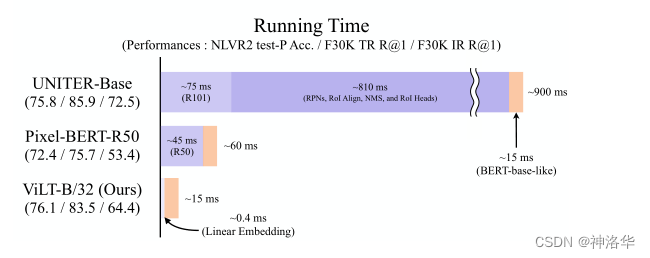
-
Region Feature:整个运行时间 900ms,其中视觉特征抽取就要 885ms,处理文本特征只有 15ms,浪费了太多计算资源在视觉特征的处理上,比后面处理多模态融合的时间还多,所以也不是很合理(VLP 应该花费更多精力在多模态特征的融合上)。 -
ViLT相比Region Feature方法性能下降了很多,但是高于grid feature方法,而且抽取视觉特征抽取只需要 0.4ms,训练时间上千倍的减少,这也是本文的最大卖点。
- 模态交互
多模态特征的融合有两种常见方式:
-
Single-stream:单通路结构,文本特征和图像特征直接 concat 连接,然后输入一个 transformer 进行交互;
-
Dual-stream:双通道结构,文本特征和图像特征分别过一个文本模型和图像模型,充分挖掘单模态特征,然后再经过一个 transformer layer 做融合。
这两种方法的效果其实差不多,dual-stream 明显更贵,参数量、计算量更多,所以作者采用了 Single-stream。
引言
2017 年以来,NLP 领域基本就是被 transformer 一统江湖了,所以 VLP 模型的文本处理也只能这么做,没有什么好改的。但 VLP 要做 Vision-Language Pre-training,就 必须将图像的像素,转换为带有语义性质的离散的特征,这样才可以和文本 tokens 匹配起来,才能在后续输入 transformer 时进行特征融合,这也是大家研究的重点。
- 目标检测抽特征
图像的像素不能直接扔给 transformer,不然序列长度就太长了。ViT提出将图片分割成一个个固定大小的 patch,然后使用线性层映射为 patch embedding 输入网络(比如 patch size = 16×16 时,处理后序列长度从 224×224 降为 14×14)。但ViT是 2021 年的工作,之前的工作这部分处理都是依赖于一个目标检测器。
选用目标检测器来处理图像特征有很多原因:
- 目标检测是一个天然的离散化过程,其得到的
bounding box代表一个个物体,有明确的语义信息(可类比文本中的 token),而且还是离散化的。所以这种方法简单粗暴,效果也好。- 以前的
VLP下游任务(包括 VLP 领域的数据集),不管是 VQA(视觉问答,给定图像回答问题)、visual captioning(VC,视觉字幕,给定图片或视频,生成对应的文本描述)还是 image-text-retrieval(图文检索)等等,这些任务都跟物体有非常强烈的联系,一旦检测到物体,就很可能做出正确的答案。所以选择目标检测作为多模态模型的一部分,也是很合理的。目前 VLP 模型的目标检测器都是在 Visual Genome 数据集 ��上预训练的,其包含 1400 类物体和 400 类属性。如果物体类别太少,就和文本 token 匹配不起来了,因为文本 token 基本是无穷无尽的。
-
Pixel-BERT 抽取网格
使用在 ImageNet 上预训练好的 ResNet 抽取特征,将 ResNet 最后得到的特征图当成是一个离散的序列,然后和文本特征一起输入 transformer 做融合,速度就快很多。 -
ViLT三大贡献-
使用
patch projection层抽取视觉特征,极大简化了多模态学习框架,减少了运行时间和参数量 -
ViLT是第一个不使用卷积特征和区域性特征的同时(Without Convolution or Region Supervision),模型性能还表现的比较好的模型 -
首次在
VLP训练中使用了整词掩码和图像数据增强,并被证明可以明显提升模型性能。
CV 领域早已证明数据增强是一个很有用的 trick,但在多模态领域,始终要考虑图文匹配的问题,所以一直没有使用。比如文本是“草地上有只小白兔”,对图像使用数据增强,可能就不是白色兔子和绿色的草地了,这时新生成的图文对就不是一个正确的对。
-
背景知识
这部分相当于多模态工作的简单综述,很多介绍多模态的工作都使用了下面这张图。
首先,作者根据 1)图像和文本的表达力度(参数量/计算量)是否平衡(图像和文本特征一样重要,理论上比重应该差不多);2)多模态特征怎样融合;将 VLP 模型归结为四类:
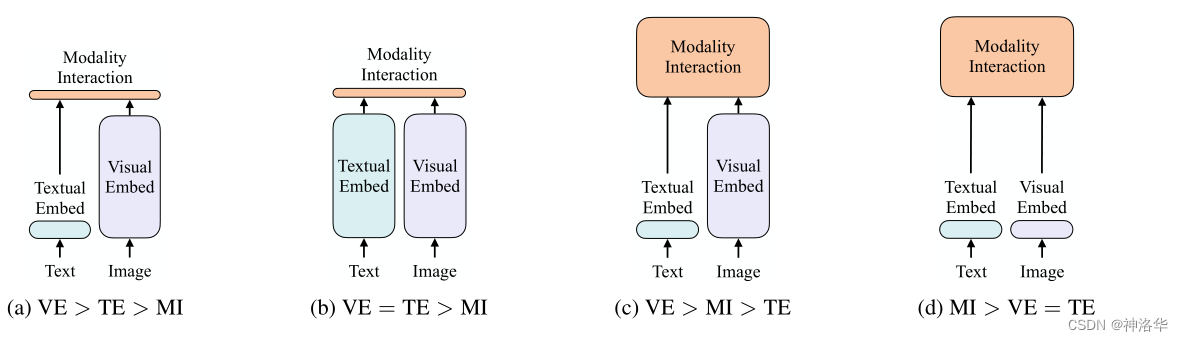
- VE, TE 和 MI 分别表示 visual embedder, textual embedder 以及 modality interaction(模态融合)
- a:VSE/ SCAN 等模型的做法,视觉特征的处理远大于文本特征,模态融合只使用了简单的点乘操作或很简单的浅层 attention 网络;即 VE > TE > MI
- b:CLIP,每个模态单独使用 transformer encoder,两者计算量差不多。特征融合部分,只是简单的计算了一下图文特征的相似性;即 VE = TE > MI
CLIP 特别适合需要图文特征(GroupViT/GLIP 等)或者是图文检索的任务,但做 VQA 或者 visual reasoning(视觉推理,更难的 VQA)这种需要视觉推理的任务时,会稍逊一筹。因为一个简单的不可学习的点乘,是没法做深层次的特征融合和分析的。 - c:这些年 80%的工作都是这个方向,比如 ViLBERT、UNITER、Pixel-BERT 等等。文本侧很轻量,但图像侧使用很重的 CNN 抽取特征;最后特征融合使用了 Transformer,所以 VE > MI > TE;
对于大部分视觉文本多模态任务来说,模态融合一定要做的比较好,最后的效果才会比较好,跟之前抽取的特征关系不太大,即理想框架应该是
MI > VE = TE。
- d:文本视觉特征的抽取都很轻量,特征融合使用 transformer,即
MI > VE = TE。
算法
模型结构
ViLT 模型结构如下图所示:
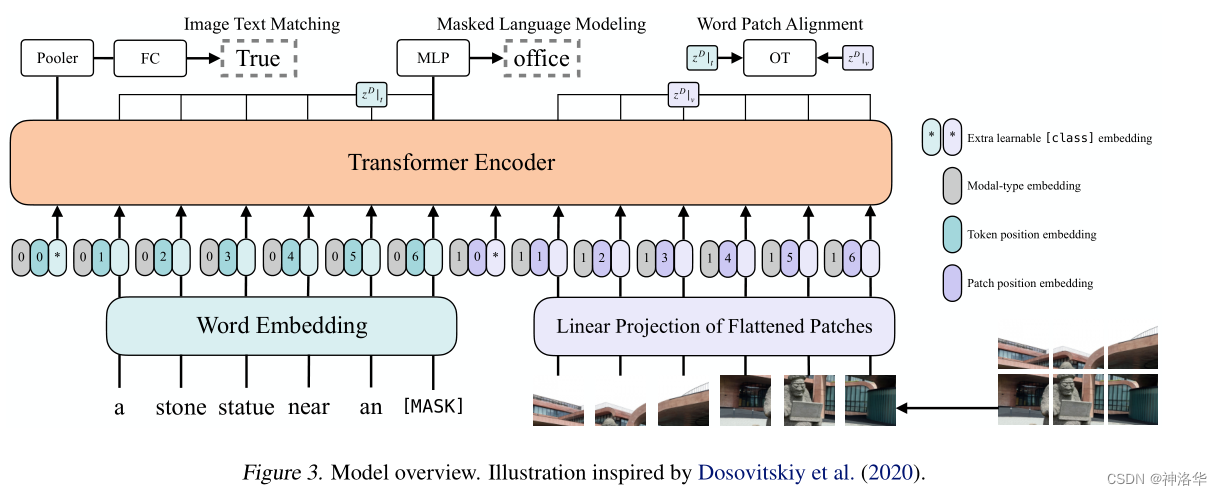
- 文本经过 pre-trained BERT tokenizer 得到 word embedding(前面有 CLS token,图中*表示)
- 图片经过 ViT patch projection 层得到 patch embedding(也是用*表示 CLS token);
- 文本特征+文本位置编码+模态嵌入得到最终的 text embedding,图像这边也是类似的操作得到 image embedding;二者 concat 拼接之后,一起输入 transformer layer,然后做 MSA 交互(多头自注意力)
模态嵌入即 Modal-type embedding,使用 0 代表文本,1 代表图像。因为在
Single-stream模型中,图文特征是直接拼在一起输入一个 transformer。如果不进行标注,模型是不知道哪一块是文本,哪一块是特征,这样不利于学习。加了模态嵌入可以区分之后,模型就可以在训练时找出图文之间的关系,学习的更好。
论文中也给出了前向过程的数学表达式:
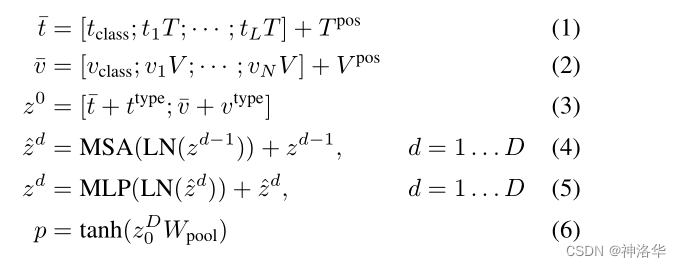
- 文本 t t ttokenizer 后得到 L×H 维的 word embedding,再加上(L+1)×H 维的位置编码和 cls token 得到文本嵌入 ,同理得到 N×H 维的图片嵌入 ;
- 和 分别��加上各自的模态嵌入 和 之后,拼接得到输入序列 ;
- 输入 transformer layer 做后续的 MSA 等操作得到最后的输出 。
目标函数
ViLT 使用了一般 VLP 模型常用的目标函数,即图文匹配 loss( ITM,image text matching)和 BERT 的掩码学习 loss(MLM,Masked Language Modeling)。另外 ViLT 还使用了 Word Patch Alignment(WPA)。
ITM loss:以 50%的概率将文本对应的图片随机替换成数据集中的其它图片,然后将文本 CLS token 对应输出使用一个 FC ��层映射成一个二值 logits,用来判断图像文本是否匹配;MLM loss:随机 mask 一个文本 token,然后将其重建出来。
其实图片这边也可以使用 masked patch 重构任务,但是当时 MAE 还没出来,重构效果还不够好,所以作者没有这么做。后续有 VL-BEiT,就使用了图像-文本掩码任务(masked vision-language modeling )。WPA:简单理解就是将文本和图像的输出都当做一个概率分布,然后使用最优运输理论计算一下两者的距离
模型总结
ViLT 模型确实很简单,如果将图片这边 patch embedding 也看做 token embedding,那这就是一个 BERT 模型;如果将文本特征拿掉,那这就是一个 ViT。
整词掩码
另外 ViLT 还使用了 whole word masking 技巧,即将整个 token masked 掉而不是只掩码子词,避免了只通过单词上下文就可以进行预测。比如将“giraffe”词 tokenized 成 3 个部分[“gi”, “##raf”, “##fe”],可以 mask 成[“gi”, “[MASK]”, “##fe”],但是前后分别为 "gi" 和 "e" 的单词本来就没多少,模型很可能只通过文本的上下文信息就预测出这个单词就是“giraffe”,导致图像信息没有利用到,图文匹配 loss 就失去了意义。
图像增强
上面提到的 c 类 VLP 模型,需要缓存特征,即在训练前就提前抽取好视觉特征,所以在下游任务微调时没法做图像数据增强的(如果想使用图像增强,就得重新抽取,成本太高,所以直到 21 年都还没有人这么做)。
ViLT 是一个端到端的模型,作者在微调时直接就上了 RandAugment。考虑到需要图文匹配,作者改动了其中两处,即去掉了 cutout 和 color inversion(前者是随机去掉图像中某一区域,后者是进行颜色变换)。
实验
训练数据集
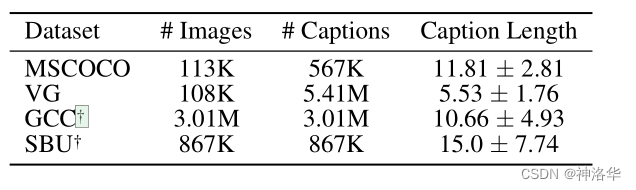
ViLT 使用四个多模态数据集进行预训练:MSCOCO、VG、SBU、GCC。这四个数据集也叫 4M,因为所有图片加在一起是 400 万张左右。
- MSCOCO:即 Microsoft COCO,每张图片有五个 captions(描述图像的标题),平均标题长度 12。模型生成的标题要尽量和这 56 万标题相似。(图像 11 万,图文对 56 万)
- VG:即 Visual Genome,10.8 万图片,541 万标题,标题平均长度 5.5
- SBU/GCC :即 SBU Captions 和 Google Conceptual Captions。这两个数据集都是一张图配一个标题,但数据集建造者只给了图片链接,其中不少失效了,所以作者只使用了其中能用的部分,在下图用
†表示。
性能对比
- 分类任务
下面在
VQAv2和NLVR2两个数据集上对比了ViLT-B/32和其它模型的性能。这两个都可以简单理解为(转化为)多模态领域的分类任务。
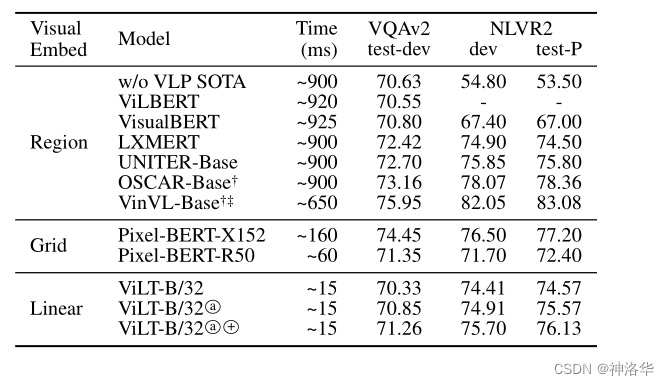
- 上图 a 表示使用改进的
RandAugment数据增强策略;+表示训练更长的时间(20 万 steps) ViLT-B/32在速度和精度之间平衡的比较好
- 检索任务
作者比较了 ViLT-B/32 和其它模型在 Flickr30k 和 MSCOCO 两个检索任务上的性能

上图是 Zero-Shot 的结果,下图是微调的结果。
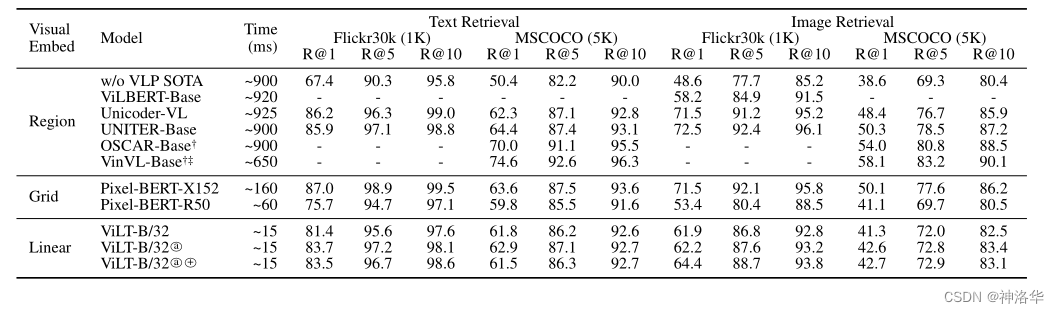
可以看到 ViLT-B/32 的取舍做的不错,速度很快,不过精度还有待提高。
消融试验
下面是作者做的一些消融试验:
w 表示整词掩码,m 是图像的完形填空后重建,论文称之为 MPP、a 表示数据增强
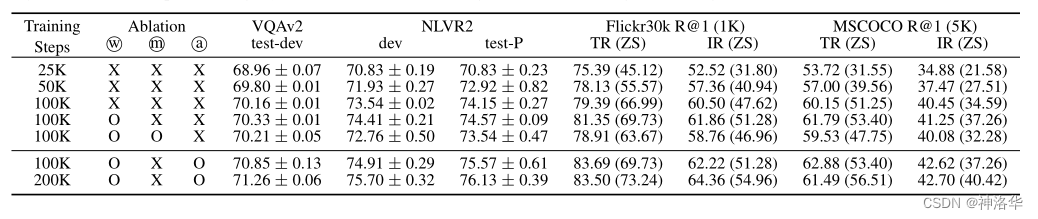
- ViLT 也是一种自监督训练的形式,可以看到随着训练时间的增加,模型性能一直提升
- 对比三种策略,整体掩码和数据增强都比较有效,特别是数据增强。MPP 效果不好,作者后续没有再使用
结论
ViLT 提出了一个极简的多模态框架,成功将 BERT 和 ViT 应用于多模态 Transformer 中。ViLT-B/32 证明了不使用卷积特征或者 Region Feature,只需要一个 patch projection 层,模型效果也不错,但性能还是有待提高。作者提出三种改进方向:
- Scalability:模型越大越好,数据集越多越好
- 使用 masked vision-language modeling,即图像部分也做掩码重建(完形填空)。后续 VL-BEiT 做到了这一点。
- 数据增强:消融试验中数据增强的提升是最大的,作者希望可以优化这一块。