DeepSeek v3.2
Agent RL 相关内容
Introduce
引出在 AI 智能体领域,与专有模型相比,开源模型在泛化能力和指令遵循方面存在显著差距,影响了其在实际部署中的有效性
我们提出创新流程以增强工具使用场景中的泛化推理能力:先采用 DeepSeek-V3(DeepSeek-AI,2024)方法实施冷启动阶段,将推理与工具使用统一在单轨迹中;随后推进至大规模智能体任务合成,生成超过 1,800 个差异化环境与 85,000 条复杂指令。这套海量合成数据驱动强化学习过程,显著提升了模型在智能体语境中的泛化能力与指令遵循能力
后训练
思维上下文管理
-
解决的核心问题:Token 效率
- 在以往的推理模型(如 DeepSeek-R1)中,模型在每一轮对话后通常会丢弃之前的思维链(Thinking process) 。但在 多轮工具调用 场景下,如果模型每进行一次工具操作(如调用搜索 API)就要重新从头开始推理整个问题,会造成极大的 Token 浪费 和 重复计算
-
三大核心规则
-
保留思维内容: 只要对话中增加的是 与工具相关的信息(例如工具的输出结果),模型就会在上下文里保留之前的思维内容,而不必重新推理
-
按需清除: 只有当 新的用户消息 进入对话时,历史的推理过程(Thinking traces)才会被丢弃 ()
-
保留执行历史: 即使推理过程被清除了,之前的 工具调用记录及其结果 依然会保留在上下文中,确保模型记得已经做过什么
-
冷启动
在 DeepSeek-V3.2 技术报告中,3.2.2. Cold-Start(冷启动) 部分的核心目的是为了证明:通过精心设计的指令(Prompting),模型能够预先展现出将“思维链(Reasoning)”与“工具调用(Tool-use)”结合的能力,从而为后续的大规模强化学习(RL)提供高质量的初始数据轨迹。 具体来说,这一部分证明了以下三个关键点:
证明模型具备“跨域结合”的潜力
该阶段证明了模型无需专门的预训练,就能通过复杂的系统提示(System Prompts)将原本独立的两种能力——非代理类推理数据 和 非推理类代理工具调用数据——无缝融合在一起。 模型表现出能够准确遵循显式指令,在推理过程中自主决定何时执行工具。
证明“思维中调用工具”模式的可行性
通过这一部分的实�验,DeepSeek 团队证明了可以使用特定的模板诱导模型产生特定的行为模式:
-
标签化引导: 使用
<think></think>标签来强制模型在输出答案前进行思考。 -
多轮交互模式: 证明了通过提示词可以让模型在思维链内部多次调用 Python 解释器等工具(即
Thinking-Then-TOOLCALL模式)。 -
复杂场景适应: 例如在竞争性编程任务中,模型能学会在给出最终代码前先通过思考和工具调试来验证逻辑。
为强化学习提供“启动基石”
这是冷启动最重要的证明点:虽然此时模型生成的“推理+工具”轨迹可能还不够稳健(robustness),但它已经能够偶尔产生 符合预期目标的正确轨迹。
大规模智能体任务合成
多样化的强化学习(RL)任务集对于增强模型的鲁棒性至关重要 。对于搜索、代码工程和代码解释等任务,我们采用了真实世界的工具,包括实际的网页搜索 API、编程工具和 Jupyter Notebooks 。虽然这些强化学习环境是真实的,但所使用的提示词(Prompts)要么是从互联网资源中提取的,要么是合成生成的,而非源自真实的用户交互 。对于其他任务,环境和提示词均为合成构建 。表 1 描述了我们使用的智能体任务 。
表 1 | 不同智能体任务的说明,包括任务数量、环境类型(真实或合成)以及提示词来源(提取或合成) 这里的提示词其实可以认为全是合成的,因为提取也是信息的抽取:
| 任务类别 | 任务数量 | 环境 | 提示词 |
|---|---|---|---|
| 代码智能体 (Code Agent) | 24,667 | 真实 | 提取 |
| 搜索智能体 (Search Agent) | 50,275 | 真实 | 合成 |
| 通用智能体 (General Agent) | 4,417 | 合成 | 合成 |
| 代码解释器 (Code Interpreter) | 5,908 | 真实 | 提取 |
搜索智能体 (Search Agent)
我们采用基于 DeepSeek-V3.2 的多智能体流水线来生成多样化、高质量的训练数据 。
- 实体采样:首先从大规模网络语料库中采样不同领域的信息丰富的长尾实体 。
- 问答构建:随后,问题构建智能体使用具有可配置深度和广度参数的搜索工具探索每个实体,并将发现的信息整合为问答对 。
- 多样化生成:具有异构配置(不同检查点、系统提示词等)的多个答案生成智能体为每个提出的问答对生成多样的候选响应 。
- 验证过滤:具备搜索能力的验证智能体通过多次传递验证所有答案,仅保留标准答案正确且所有候选答案均可证明错误的代码样本 。
- 数据增强:这些数据跨��越多种语言、领域和难度等级 。为了补充这些可验证样本并更好地反映真实世界的使用情况,我们还利用现有的有助强化学习数据集中的过滤实例来扩充数据集,在这些实例中搜索工具能提供可衡量的收益 。
- 奖励模型:接着,我们制定了跨多个质量维度的详细评估标准,并采用生成式奖励模型根据这些标准为响应评分 。这种混合方法能够同时优化事实可靠性和实际实用性 。
代码智能体 (Code Agent)
我们通过从 GitHub 挖掘数百万个“问题-拉取请求”(issue-PR)对,构建了用于软件问题解决的大规模可执行环境 。
- 质量过滤:利用启发式规则和基于大语言模型(LLM)的判断对该数据集进行了严格过滤,以确保高质量,要求每条条目包含合理的问题描述、相关的金牌补丁(gold patch)以及用于验证的测试补丁 。
- 自动化构建:采用由 DeepSeek-V3.2 驱动的自动化环境设置智能体为这些配对构建可执行环境 。该智能体负责处理包安装、依赖解析和测试执行 。测试结果以标准 JUnit 格式输出,确保跨编程语言和测试框架的一致解析 。
- 验证标准:只有当应用金牌补丁后产生非零数量的“错误转正确”(F2P)测试用例(表明问题已修复)且“正确转错误”(P2F)测试用例数量为零(表明没有回归风险)时,环境才被视为构建成功 。
- 覆盖规模:利用此流水线,我们成功构建了数万个可重现的问题解决环境,涵盖了 Python、Java、JavaScript、TypeScript、C、C++、Go 和 PHP 等多种编程语言 。
代码解释器智能体 (Code Interpreter Agent)
我们利用 Jupyter Notebook 作为代码解释器来处理复杂的推理任务 。为此,我们策划了一套涵盖数学、逻辑和数据科学的多样化问题集,每个问题都要求模型利用代码执行能力来得出解决方案 。
通用智能体 (General Agent)
为了在强化学习中扩展智能体环境和任务,我们采用了一个自动环境合成智能体,合成了 1,827 个面向任务的环境 。这些任务 难以解决但易于验证。合成工作流主要由环境与工具集构建、任务合成及解决方案生成组成 。具体步骤如下:
1. 数据存储:给定任务类别(例如规划旅行路线)和配备 bash 及搜索工具的沙箱,智能体首先使用这些工具从互联网生成或检索相关数据,并存储在沙箱数据库中 。
2. 工具合成:智能体随后合成一组任务特定的工具,每个工具以函数形式实现 。
3. 迭代增强:为了创建既具挑战性又可自动验证的任务,智能体最初根据当前数据库提出一个简单的任务,并提供其解决方案及用 Python 实现的验证函数 。
-
解决方案函数仅限于调用工具函数或进行逻辑计算,不能调用其他函数或直接访问��数据库,确保任务只能通过工具接口解决 。
-
此外,解决方案产生的结果必须通过验证函数的校验。如果未通过,智能体会修改解决方案或验证函数 。
-
智能体随后迭代增加任务难度,并更新相应的解决方案和验证函数。在此过程中,如果当前工具集不足以解决任务,智能体会扩充工具集 。
通过该工作流,我们获得了数千个“环境、工具、任务、验证器”元组 。随后我们在该数据集上使用 DeepSeek-V3.2 进行强化学习,仅保留 pass@100 非零的实例,最终得到 1,827 个环境及其对应的 4,417 个任务 。
评估
Agent 评估
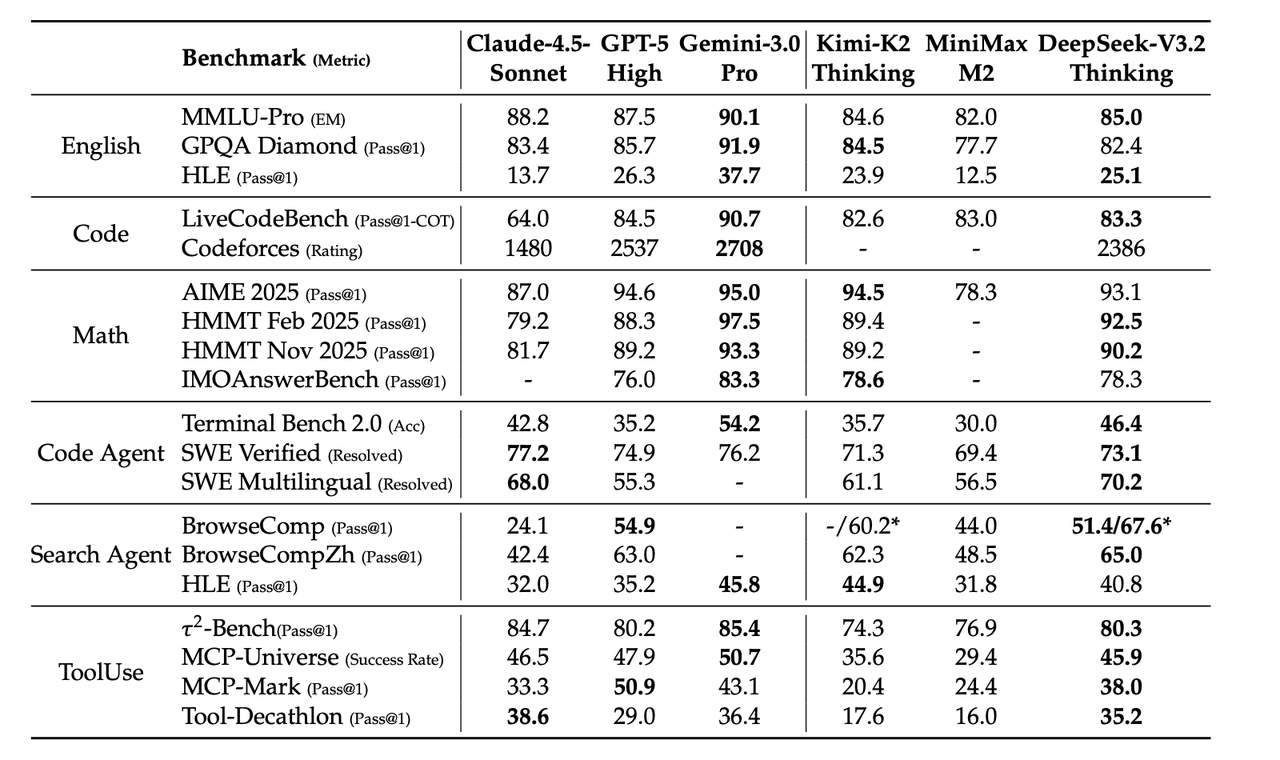
这一部分的第一张表就是 agent 能力,一部分能力强于 k2
感觉这里强不强的主要原因,主要是数据迭代了,我v3.2比k2发的晚,所以可以蒸馏k2
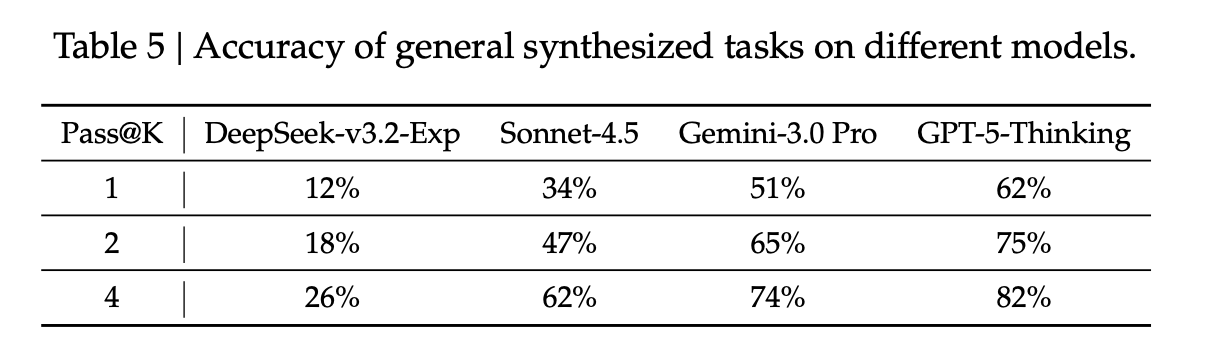
合成智能体的数据是否有用
这一部分(4.3. 章节)主要介绍了针对 合成智能体任务(Synthetic Agentic Tasks)开展的消融实验(Ablation Experiments)。其核心目的是通过实验回答两个关键问题:
合成任务是否具有足够的挑战性?
为了验证这些自动生成的任务是否太简单,团队抽取了 50 个实例进行测试 :
- 实验结果:DeepSeek-V3.2-Exp(强化学习前)的准确率仅为 12%。
- 对比:即便是一流的闭源模型(如 GPT-5-Thinking),在这些任务上的准确率最高也只有 62%。
- 结论:这证明了合成数据包含的智能体任务对于现有顶尖模型来说依然极具挑战性,适合用于强化学习 。
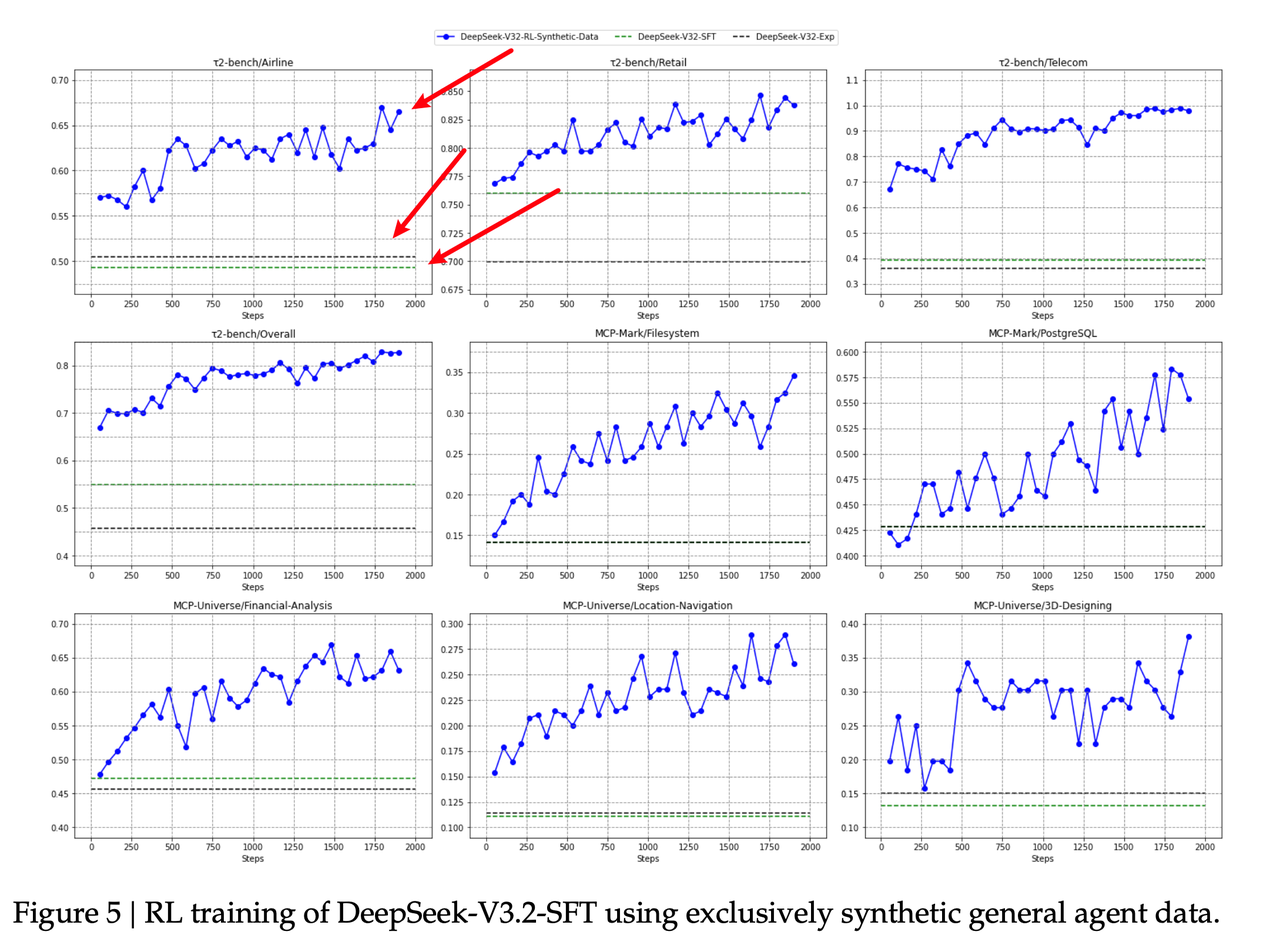
合成任务能否泛化到现实世界?
团队研究了在合成数据上进行强化学习(RL)后,模型能力是否能迁移到其他未见过的任务或真实环境中 。
- 泛化表现:实验显示,仅在合成智能体数据上进行强化学习,就能显著提升模型在 Tau2Bench、MCP-Mark 和 MCP-Universe 等第三方基准测试中的表现 。
- 对比验证:如果强化学习仅局限于真实的“代码”和“搜索”环境,则无法在上述通��用智能体基准测试中取得进步 。
- 结论:这有力地证明了 大规模合成数据 在提升模型通用智能体能力(如泛化性和指令遵循)方面的独特潜力 。
核心结论
该章节论证了 DeepSeek 无需完全依赖真实用户数据,通过 高质量的自动合成任务,就能有效地训练出能够处理复杂、跨领域任务的通用 AI 智能体 。
上下文处理策略的消融
解决的核心问题:上下文瓶颈
- 长度限制:即使拥有 128k 的上下文窗口,在复杂的搜索任务中,模型仍会频繁触及长度上限 。
- 后果:这会导致推理过程提前中断,限制了模型通过增加执行步骤(测试时计算)来解决问题的潜力 。
三种上下文管理策略
当 Token 使用量超过上下文窗口的 80% 时,系统会采取以下措施 :
- 总结 (Summary):对已溢出的轨迹进行总结,然后重新启动执行过程 。
- 丢弃 75% (Discard-75%):直接丢弃轨迹中前 75% 的工具调用历史,以释放空间 。
- 全部丢弃 (Discard-all):重置上下文,丢弃所有之前的工具调用历史 。
这个现象很反常,按理来说,全部丢弃上下文会有信息损失(不会再从头开始做嘛?还是说,因为这个任务步骤太长了(100+ step),所以可以丢弃,不会有什么影响?)
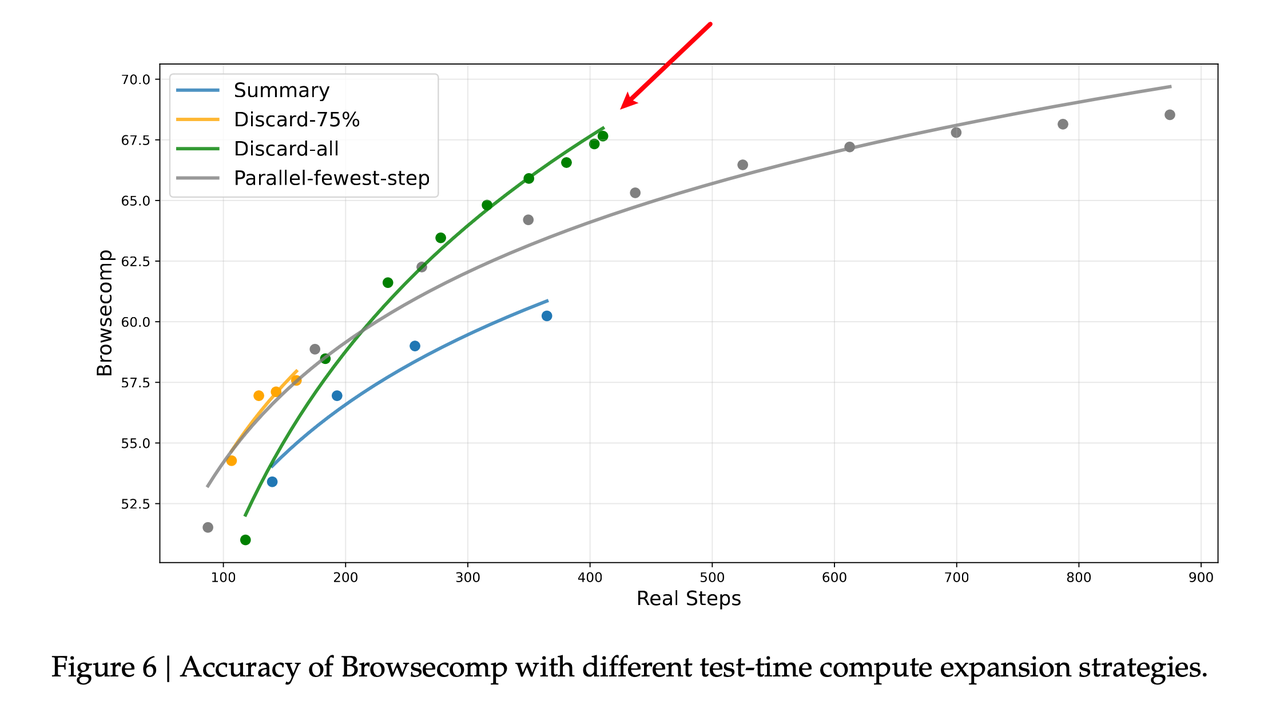
实验结果与评估
研究团队在 BrowseComp 基准测试上评估了这些策略,并与并行缩放(Parallel scaling)进行了对比 :
- 性能提升:上下文管理允许模型执行更多步骤,显著提升了准确率 。
- 策略对比:
- 总结 (Summary):将平均执行步数从 140 提升至 364,得分从 53.4 升至 60.2,但整体效率较低 。
- 全部丢弃 (Discard-all):尽管方式简单,但在效率和扩展性上表现优异,得分达到 67.6,效果与更复杂的并行缩放相当,且步数更少 。
总结
这个技术报告,其实就三个点:dsa,rl 训练框架和 agent
agent 也是做了很多数据合成的工作,证明了合成的数据确实可用(数据才是最有用的),同时做了上下文管理策略的消融(但是结果反直觉,全部扔掉历史是最好的),都可以参考