GPU多卡分布式训练入门
引言
近年来,随着Transformer架构的提出,使得深度学习模型轻松突破上万亿规模参数,传统的单机单卡模式已经无法满足超大模型进行训练的要求。所以引入多卡分布式训练原因之一:模�型在一块GPU上放不下,多块GPU上才能运行完整的模型。另外在模型小,但是训练数据集大的情况下要加速训练也需要引入多 GPU 分布式训练提升训练速度。
一些术语
在分布式训练中,AllReduce 是把所有节点的梯度求和(或取均值)后同步回每个节点,让所有卡的梯度保持一致;AllGather 是把每个节点持有的不同数据片段收集起来,让每张卡都拿到完整的数据(比如 ZeRO 里把分片的参数还原);ReduceScatter 则是 AllReduce 的前半段,先规约再分片分发给各节点,每张卡只拿到结果的一部分(ZeRO-2/3 用它来分片梯度/参数);Broadcast 是一对多,把一个节点的数据发给所有节点;AllToAll 是每个节点给其他每个节点发不同的数据,MoE 的 Expert 路由常用它。简单记:Gather 是"收集拼完整",Reduce 是"规约求结果",两者组合就是 AllReduce 和 ReduceScatter。
规约(Reduce) 就是把多个值按某种运算合并成一个值。
最常见的规约操作:
- 求和:[1, 2, 3, 4] → 10
- 求均值:[1, 2, 3, 4] → 2.5
- 取最大值:[1, 2, 3, 4] → 4
在分布式训练里,4张卡各自算出自己的梯度,规约就是把这4份梯度加在一起(或取均值),得到全局梯度。
GPU0 梯度: [0.1, 0.2] GPU1 梯度: [0.3, 0.4] GPU2 梯度: [0.1, 0.1] GPU3 梯度: [0.2, 0.1] ↓ 规约(求和) 结果: [0.7, 0.8] ← 代表所有卡的综合梯度
所以 AllReduce = 所有卡都参与规约,且每张卡最终都得到结果,用来同步梯度保证每张卡的模型参数更新一致。
常用的多GPU训练��方法
这里主要介绍几种常见的多 GPU 训练方法:
模型并行方式
如果模型特别大,GPU显存不够,无法将一个显存放在GPU上,需要把网络的不同模块放在不同GPU上,这样可以训练比较大的网络。
这里业界一般又会区分成两种方式:流水线并行 和 张量并行。
流水线并行
朴素的模型并行存在GPU利用度不足,中间结果消耗内存大的问题。

流水线并行是一种将模型的不同阶段分配到不同的 GPU 上进行计算的方式。具体来说,流水线并行将模型划分为多个阶段,按模型的layer层切分到不同设备,即层间并行。例如,在使用两个 GPU 进行流水线并行时,可以将模型的前半部分分配到第一个 GPU 上进行计算,将后半部分分配到第二个 GPU 上进行计算,两个 GPU 之间通过数据传输进行交互。这样可以加快模型的计算速度,提高训练效率。
简单地将模型切分到多设备上并不会带来性能的提升,因为模型的线性结构到时同一时刻只有一台设备在工作,而其它设备在等待,造成了资源的浪费。为了提升效率,流水线并行进一步将小批次(MiniBatch)切分成更细粒度的微批次(MicroBatch),在微批次中采用流水线式的执行序,从而达到提升效率的目的。
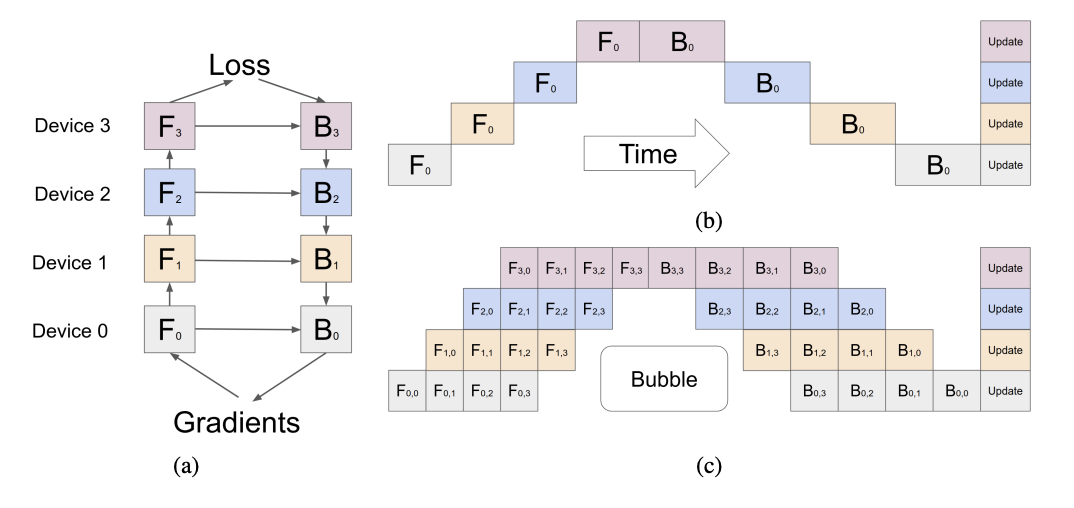
【来源:Easy Scaling with Micro-Batch Pipeline Parallelism】
随着模型的增加,每块GPU中存储的中间结果也会越大。简单粗暴但有效的办法:用时间换空间,在Gpipe论文里,这种方法被命名为re-materalization,后人也称其为active checkpoint。
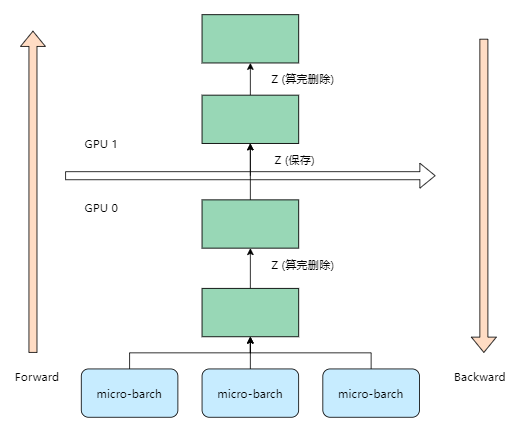
每块GPU上,我们只保存来自上一GPU的最后一层输入Z,其余的中间结果算完不保存。等到backward的时候再由保存下来的Z重新进行forward来算出。现在计算每块GPU峰值时刻的内存:每块GPU峰值时刻存储大小 = 每块GPU上的输入数据大小 + 每块GPU在forward过程中的中间结果大小。
张量并行
张量并行是一种将模型的不同部分分配到不同的 GPU 上进行计算的方式。具体来说,张量并行将模型的输入和输出张量分割成多个子张量,也就是将计算图中的层内的参数切分到不同设备,即层内并行。例如,在使用两个 GPU 进行张量并行时,可以将输入张量的前半部分分配到第一个 GPU 上进行计算,将后半部分分配到第二个 GPU 上进行计算。
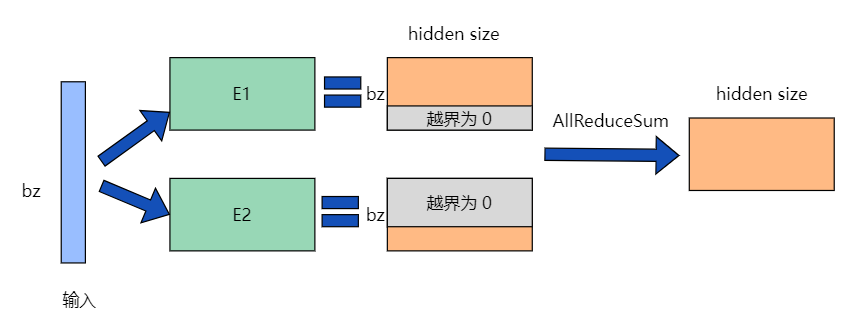
对于Embedding算子,如果总的词表非常大,会导致单卡显存无法容纳Embedding层参数。可以其将Embedding参数沿word_size维度,切分为两块,每块大小为[word_size/2, hidden_size],分别存储在两个设备上,即每个设备只保留一半的词表。
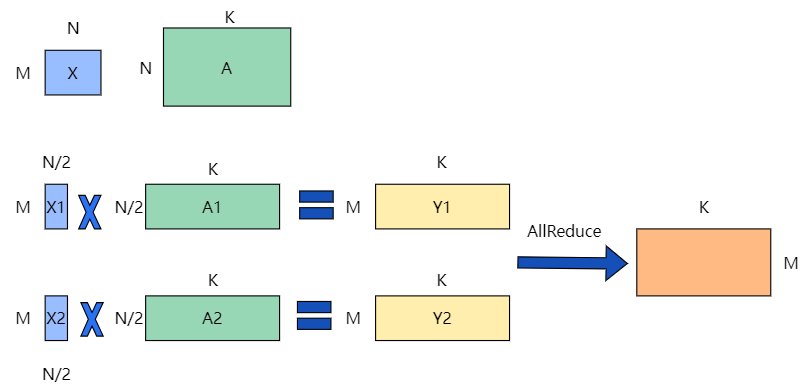
矩阵乘的张量模型并行充分利用矩阵分块乘法的原理。举例来说,要实现如下矩阵乘法Y=X*A,其中X是维度为MxN的输入矩阵,A是维度为NxK的参数矩阵,Y是结果矩阵,维度为MxK。如果参数矩阵A非常大,甚至超出单张卡的显存容量,那么可以把参数矩阵A切分到多张卡上,并通过集合通信汇集结果,保证最终结果在数学计算上等价于单卡计算结果。这里,参数矩阵A存在两种切分方式:按列切块 和 按行切块。
还有几个问题需要注意:
一个是参数初始化问题,多卡的参数初始化要等价于单卡初始化结果,应该将参数切分到多个卡上后,再修改相应卡的随机性,保证各个卡的随机种子不同,这样从随机角度而言,多卡参数初始化的随机性与单卡相同。不然可能两张卡的随机种子一样导致失去了一般的随机性,会导致 loss 收敛速度逐渐变慢。
另外是算子计算随机性,比如 Dropout 是典型的具有随机性的算子,Transformer结构的self-attention模块中就大量使用了Dropout算子,根据使用的位置不同,Dropout将存在两种随机性,需要利用两套随机种子进行控制。
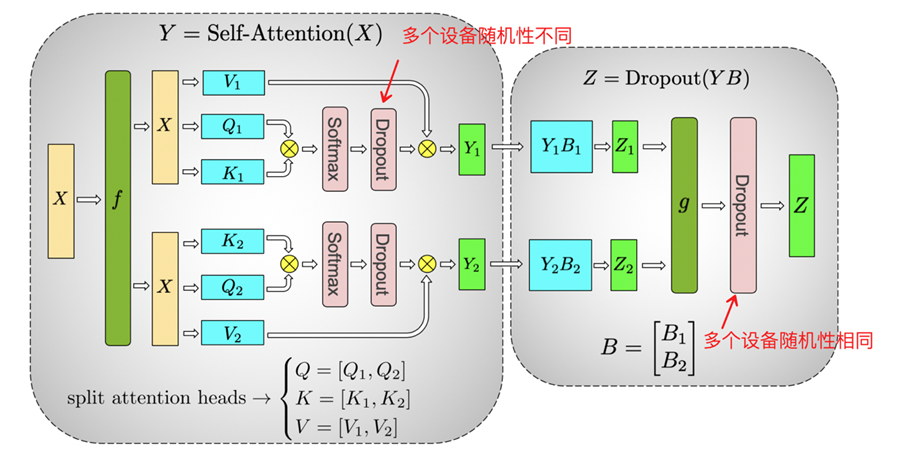
【来源:Training Multi-Billion Parameter Language Models Using Model Parallelism】
数据并行方式
所谓的数据并行,将整个模型放在一块GPU里,再复制到每一块GPU上,同时进行正向传播和反向误差传播。就是将数据x进行切分,而每个设备上的模型w是完整的、一致的。如下图所示,x被按照第0维度平均切分到2个设备上,两个设备上都有完整的w。
这样,在两台设备上,分别得到的输出,都只是逻辑上输出的一半(形状为 ),将两个设备上的输出拼接到一起,才能得到逻辑上完整的输出。

从图上可以看出来这个过程其实相当于加大了batch_size。
数据并行策略下,在反向传播过程中,需要对各个设备上的梯度进行 AllReduce,以确保各个设备上的模型始终保持一致。当数据集较大,模型较小时,由于反向过程中为同步梯度产生的通信代价较小,此时选择数据并行一般比较有优势,我们子 lora 预训练的时候就是采用的这个方案。
混合并行方式
为了充分利用带宽,通常情况下,张量并行所需的通信量最大,而数据并行与流水线并行所需的通信量相对来说较小。因此,同一个服务器内使用张量并行,而服务器之间使用数据并行与流水线并行。以 GPT-3 为例,以下是它训练时的设备并行方案:它首先被分为 64 个阶段,进行流水并行。每个阶段都运行在 6 台 DGX-A100 主机上。在6台主机之间,进行的是数据并行训练;每台主机有 8 张 GPU 显卡,同一台机器上的8张 GPU 显卡之间是进行模型并行训练。
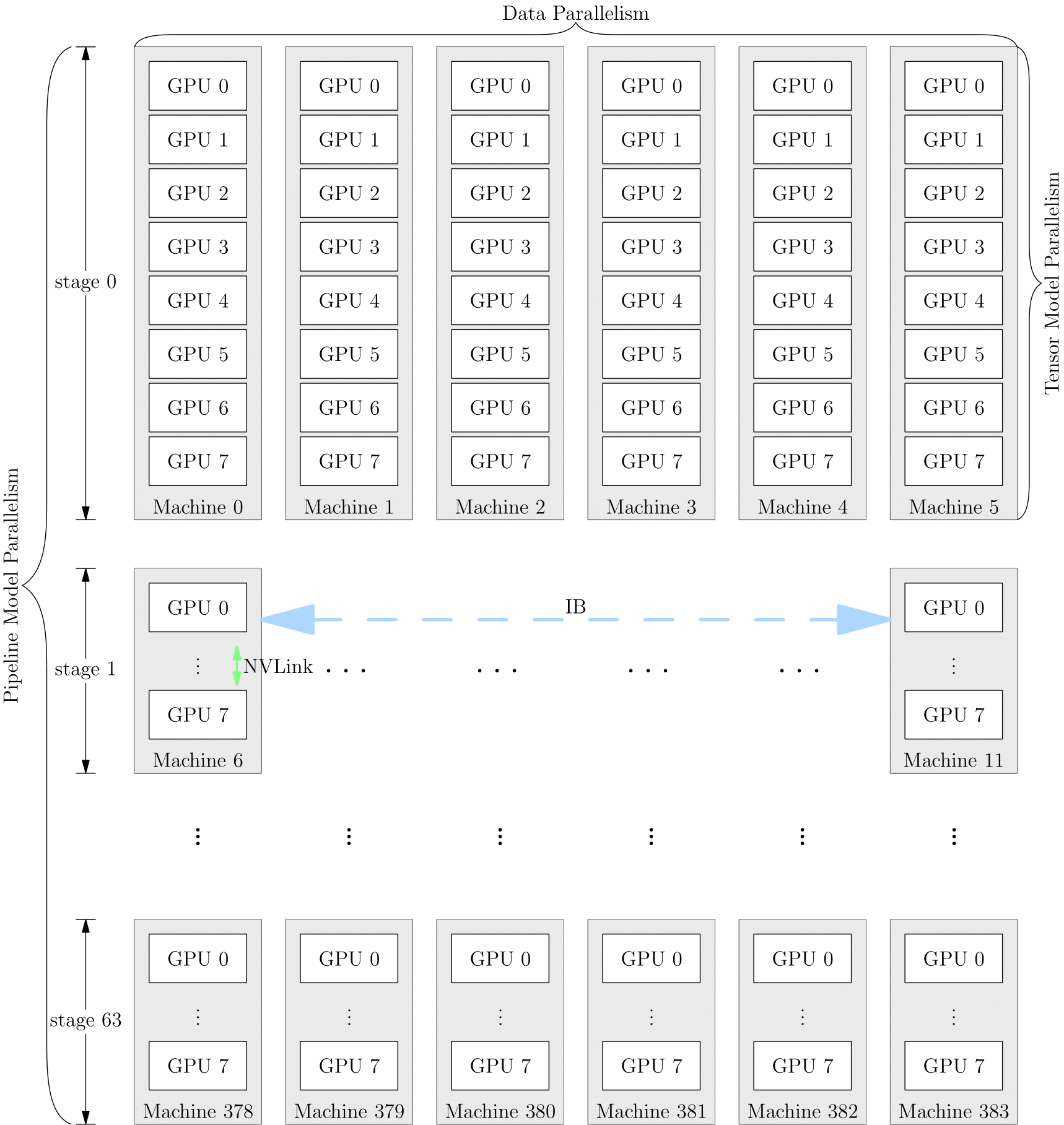
总结
流水线并行:
-
优点:通用性比较好,提高吞吐量和资源利用率
-
缺点:阶段不平衡,存在气泡
张量并行:
-
优点:显存效率高
-
缺点:缺乏通用性,需要引入额外比较大的通信开销
数据并行:
-
优点:通用性强
-
缺点:显存总开销比较大